郑州做网站最好的公司源代码如何做网站
按键修改阈值功能
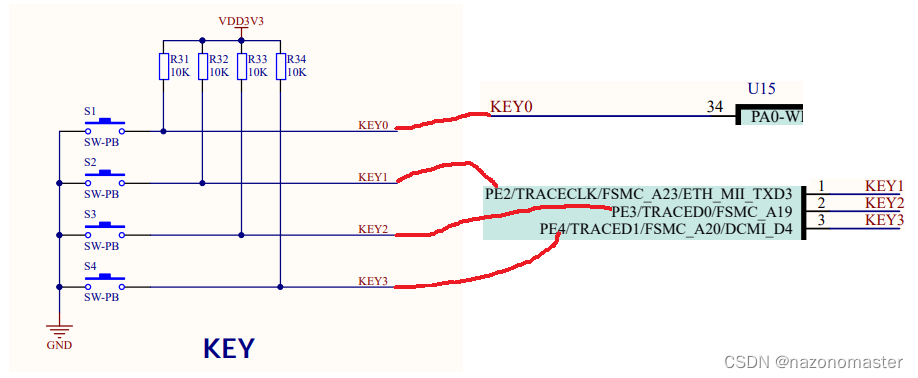
要使用按键,首先要定义按键。通过查阅资料,可知按键的引脚如图所示:按键1(S1)通过KEY0与PA0连接,按键2(S2)通过KEY1与PE2连接,按键3(S3)通过KEY2与PE3连接,按键4(S4)通过KEY3与PE4连接。
key.c
这段代码主要是对四个按键进行了初始化配置,使其能够进行读取输入操作。
#include "key.h"void Key_Init()
{GPIO_InitTypeDef GPIO_InitStructure;/*四个按键*//* GPIOA 引脚的时钟使能 */RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOA, ENABLE); /* 配置PA0引脚为输出模式 s1*/GPIO_InitStructure.GPIO_Pin = GPIO_Pin_0; //配置的引脚GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IN; //输入模式GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; //推挽模式GPIO_InitStructure.GPIO_Speed = GPIO_Speed_100MHz; //速度为100MHzGPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; //上下拉电阻:无上下拉电阻GPIO_Init(GPIOA, &GPIO_InitStructure);/* 配置PE2引脚为输出模式 s2*/GPIO_InitStructure.GPIO_Pin = GPIO_Pin_2; //配置的引脚GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IN; //输入模式GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; //推挽模式GPIO_InitStructure.GPIO_Speed = GPIO_Speed_100MHz; //速度为100MHzGPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; //上下拉电阻:无上下拉电阻GPIO_Init(GPIOE, &GPIO_InitStructure);/* 配置PE3引脚为输出模式 s3*/GPIO_InitStructure.GPIO_Pin = GPIO_Pin_3; //配置的引脚GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IN; //输入模式GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; //推挽模式GPIO_InitStructure.GPIO_Speed = GPIO_Speed_100MHz; //速度为100MHzGPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; //上下拉电阻:无上下拉电阻GPIO_Init(GPIOE, &GPIO_InitStructure);/* 配置PE4引脚为输出模式 s4*/GPIO_InitStructure.GPIO_Pin = GPIO_Pin_4; //配置的引脚GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IN; //输入模式GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; //推挽模式GPIO_InitStructure.GPIO_Speed = GPIO_Speed_100MHz; //速度为100MHzGPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; //上下拉电阻:无上下拉电阻GPIO_Init(GPIOE, &GPIO_InitStructure);}
key.h
#ifndef _KEY_H
#define _KEY_H//C文件中需要的其他的头文件
#include <stm32f4xx.h>
#include "sys.h"
#include "delay.h"
#include "math.h"
#include "adc.h"//C文件中定义的函数的声明
void Key_Init(void);#endif
阈值更改函数
这段代码定义了两个函数。这两个函数用于更改阈值和选择需要调整哪个阈值。
Yuzhi_change() 函数的作用是根据按键输入更改传入的指针变量 yuzhi 所指向的阈值,函数内部通过判断按键的状态进行阈值的加减操作,最大值为 99,最小值为 1。如果按键 s1 被按下,则阈值加一,D1 灯亮;如果按键 s2 被按下,则阈值减一,D2 灯亮。
Yuzhi_kind_change() 函数的作用是根据按键输入选择需要调整哪个阈值。函数内部使用一个 switch 语句判断当前需要调整的阈值类型,调用 Yuzhi_change() 函数更改阈值。如果按键s3 被按下,则更改当前需要调整的阈值类型,并且再次调用 Yuzhi_change() 函数更改阈值。此函数的传入参数包括 kind、wendu_yu、yanwu_yu 和 CO_yu,其中 kind 为当前需要调整的阈值类型,取值为 1、2、3,分别对应温度、烟雾、CO 浓度阈值。
//阈值更改函数
void Yuzhi_change(u8 *yuzhi)
{if( PAin(0)== 0 )//s1按下{if( *yuzhi<99 ){PFout(9) = 0;//D1亮(*yuzhi)++;}}elsePFout(9) = 1;//D1灭if( PEin(2)== 0 )//s2按下{if( *yuzhi>1 ){PFout(10) = 0;//D2亮(*yuzhi)--;}}elsePFout(10) = 1;//D2灭}u8 kind = 1;//更改需要调整哪个阈值
void Yuzhi_kind_change(u8 *kind, u8 *wendu_yu, u8 *yanwu_yu, u8 *CO_yu)
{switch(*kind){case 1:Yuzhi_change(&*wendu_yu);break;case 2:Yuzhi_change(&*yanwu_yu);break;case 3:Yuzhi_change(&*CO_yu);break;default :break;}/*按键3实现下调*/if( PEin(3)== 0 ){PEout(13) = 0;if( *kind<3 )(*kind)++;else if( *kind == 3 )*kind = 1;switch(*kind){case 1:Yuzhi_change(&*wendu_yu);break;case 2:Yuzhi_change(&*yanwu_yu);break;case 3:Yuzhi_change(&*CO_yu);break;default :break;}}elsePEout(13) = 1;}
空气质量判断和报警系统
这段代码实现了一个空气质量判断和报警系统。
首先,在空气质量判断的部分,根据一定的判断条件,将空气质量分为三个等级。如果 CO_ppm,Smog_ppm 和 buf[2](也就是温度)都小于 25,那么空气质量等级为 1,即为优;如果 CO_ppm,Smog_ppm 和 buf[2] 中任意一个大于 35,那么空气质量等级为 3,即为差;否则,空气质量等级为 2,即为良。
接着,在报警系统的部分,如果 CO_ppm,Smog_ppm 或 buf[2] 的值大于等于相应的阈值(CO_yu,Smog_yu或Temperature_yu),就会触发报警,此时 PFout(8) 输出高电平,蜂鸣器响起来;否则,PFout(8) 输出低电平,蜂鸣器不响。
整个代码的功能就是对空气质量进行判断,并在需要时触发报警。
/*空气质量判断*/
if( CO_ppm<25 && Smog_ppm<25 && buf[2]<25 )quality = 1;
else if( CO_ppm>35 || Smog_ppm>35 || buf[2]>35 )quality = 3;
else quality = 2;/*报警系统*/
if( (CO_ppm >= CO_yu) || (Smog_ppm >= Smog_yu ) || (buf[2]>=Temperature_yu) )PFout(8) = 1;//蜂鸣器叫
elsePFout(8) = 0;LED灯定义
这段代码实现了一个 LED 的初始化。
#include "led.h"void led_init(void)
{GPIO_InitTypeDef GPIO_InitStructure;//1、初始化led对应的引脚 PF9 PF10 PE13 PE14的时钟RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOE|RCC_AHB1Periph_GPIOF, ENABLE);//2、通过结构体初始化led引脚/* 配置PF9 PF10引脚为输出模式 */GPIO_InitStructure.GPIO_Pin = GPIO_Pin_9 | GPIO_Pin_10; //配置的引脚GPIO_InitStructure.GPIO_Mode = GPIO_Mode_OUT; //输出模式GPIO_InitStructure.GPIO_OType = GPIO_OType_PP; //推挽模式GPIO_InitStructure.GPIO_Speed = GPIO_Speed_100MHz; //速度为100MHzGPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL; //上下拉电阻:无上下拉电阻GPIO_Init(GPIOF, &GPIO_InitStructure);/* 配置PE13 PE14引脚为输出模式 */GPIO_InitStructure.GPIO_Pin = GPIO_Pin_13 | GPIO_Pin_14; //配置的引脚GPIO_Init(GPIOE, &GPIO_InitStructure);PFout(9) = 1;PFout(10) = 1;PEout(13) = 1;PEout(14) = 1;
}按键4控制OLED显示空气质量和现在可以更改哪一个阈值
这段代码定义了一个名为s4的函数,它有七个参数:kind、str_shidu、str_temp、str_smog、str_co、str_temp_yu、str_smog_yu、str_co_yu 和 quality。其中,kind表示显示什么类型的数据,如温度、烟雾浓度和CO浓度;str_shidu、str_temp、str_smog 和 str_co分别表示湿度、温度、烟雾浓度和 CO 浓度的数据值;str_temp_yu、str_smog_yu 和 str_co_yu 表示温度、烟雾浓度和CO浓度的阈值;quality表示空气质量的评级。
函数的主体部分是一个 if 语句,当 PEin(4) 等于0时(即按下按钮 4),执行 if 语句中的代码,否则执行 else 语句中的代码。if 语句中的代码主要是对 OLED 屏幕进行显示,根据 quality 参数的值,显示空气质量的评级(优、良或差),同时根据 kind 参数的值,显示相应的数据类型(温度、烟雾浓度或CO浓度)以及它们的数据值和阈值。
if语句的最后,通过 PEout(14) = 1;将指示灯 d4 熄灭,等待下一次按下按钮执行函数。
void s4(int kind, char *str_shidu, char *str_temp, char *str_smog, char *str_co, char *str_temp_yu, char *str_smog_yu, char *str_co_yu, u8 quality)
{if( PEin(4)== 0 ){PEout(14) = 0;OLED_Clear();OLED_ShowChinese3(0,0,6,16);//空OLED_ShowChinese3(18,0,7,16);//气OLED_ShowChinese3(36,0,8,16);//质OLED_ShowChinese3(54,0,9,16);//量switch(quality){case 1:OLED_ShowChinese3(72,0,10,16);//优OLED_Refresh();break;case 2:OLED_ShowChinese3(72,0,11,16);//良OLED_Refresh();break;case 3:OLED_ShowChinese3(72,0,12,16);//差OLED_Refresh();break;default :break;}OLED_ShowChinese3(0,16,0,16);//现OLED_ShowChinese3(18,16,1,16);//在OLED_ShowChinese3(36,16,2,16);//可OLED_ShowChinese3(54,16,3,16);//以OLED_ShowChinese3(72,16,4,16);//调OLED_ShowChinese3(90,16,5,16);//整switch(kind){case 1:OLED_ShowChinese2(0,32,0,16);//温OLED_ShowChinese2(18,32,2,16);//度OLED_ShowChinese2(36,32,6,16);//阈OLED_ShowChinese2(54,32,7,16);//值OLED_Refresh();break;case 2:OLED_ShowString(0,32,"CH4",16);OLED_ShowChinese2(36,32,6,16);//阈OLED_ShowChinese2(54,32,7,16);//值OLED_Refresh();break;case 3:OLED_ShowString(0,32,"CO",16);OLED_ShowChinese2(36,32,6,16);//阈OLED_ShowChinese2(54,32,7,16);//值OLED_Refresh();break;default :break;}OLED_Refresh();delay_ms(1500);/********OLED部分*********/OLED_Clear();OLED_ShowChinese2(0,0,1,16);//湿OLED_ShowChinese2(18,0,2,16);//度OLED_ShowChar(36,0,':',16);//:OLED_ShowString(48,0,&*str_shidu,16);OLED_ShowChinese2(87,0,6,16);//阈OLED_ShowChinese2(105,0,7,16);//值OLED_ShowChinese2(0,16,0,16);//温OLED_ShowChinese2(18,16,2,16);//度OLED_ShowChar(36,16,58,16);//26号‘:’,ASC2为58OLED_ShowString(48,16,&*str_temp,16);OLED_ShowString(96,16,&*str_temp_yu,16);OLED_ShowString(0,32,"CH4:",16);OLED_ShowString(32,32,&*str_smog,16);OLED_ShowString(96,32,&*str_smog_yu,16);OLED_ShowString(0,48,"CO: ",16);OLED_ShowString(32,48,&*str_co,16);OLED_ShowString(96,48,&*str_co_yu,16);OLED_Refresh();PEout(14) = 1;}elsePEout(14) = 1;
}