在哪家公司建设网站好网站设置仅某浏览器
区块链数据公司Messari首次发布Moonbeam项目分析简报,从项目市值、链上数据表现、质押以及Moonbeam的技术优势XCM使用量等角度全面分析。这个再熊市初期上线的项目一直在默默开发,并在跨链互操作领域拥有了相当的实操成绩。我们翻译了Messari简报中的部分章节,查看全文:https://messari.io/report/moonbeam-q3-2023-brief
关键信息
● 流动性激励计划Moonbeam Ignite的推出与GLMR上线Upbit的消息促使了Moonbeam的市值增长了40%(截至第三季度末)。
● Moonbeam-Acala的XCM通道是波卡使用最高的XCM通道,登记了9,500条消息。除了波卡之外,Moonbeam还与其他几条链保持跨链交互。
● Moonbeam推出Moonbeam流动性(MRL),实现平行链从其他生态访问流动性(反之也可行)而无需Moonbeam帐户或直接与Moonbeam交互。
● Uniswap V3上线Moonbeam。
关键指标
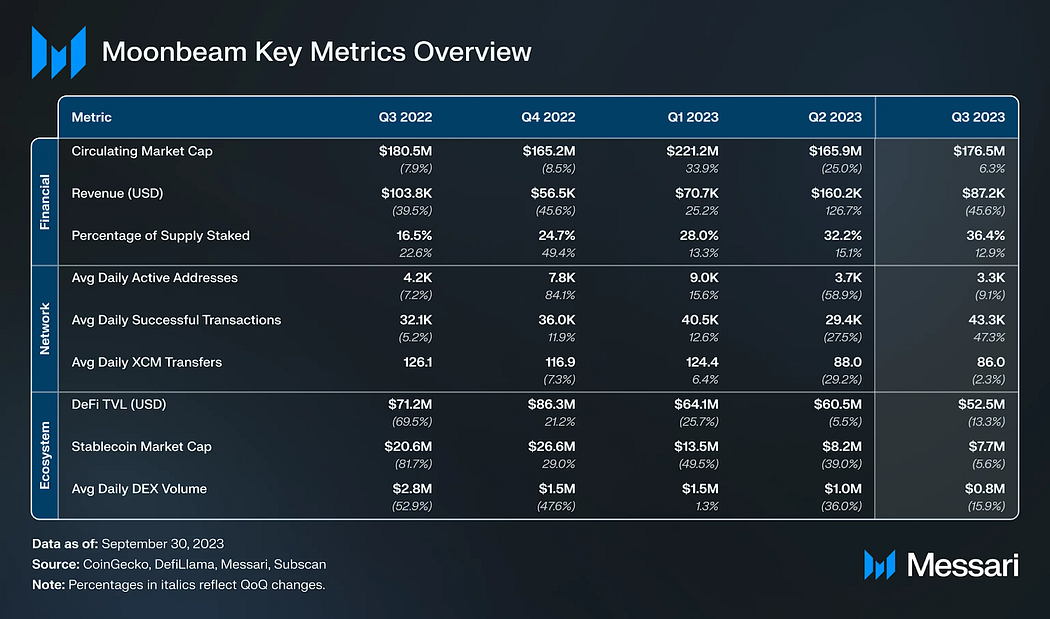
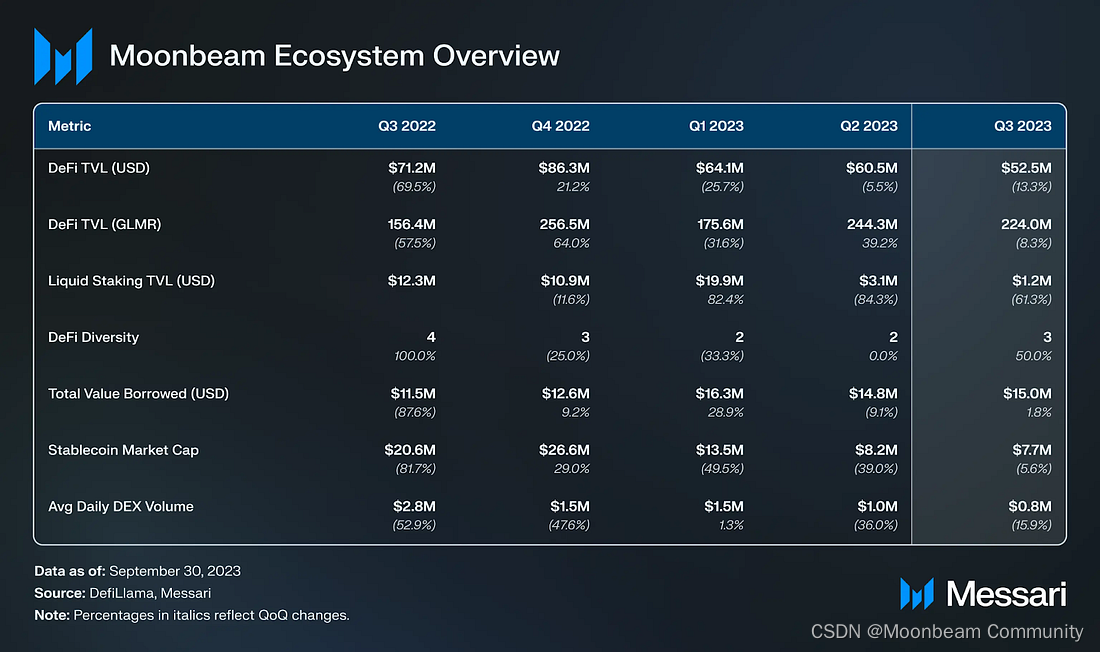
从关键数据看,Moonbeam网络质押量每月以约20%左右的幅度增长,加上Moonbeam网络目前有超过70个收集人(collator),总体质押量的增加对网络整体的稳定运行和去中心化将产生正向影响。此外,尽管第三季度的每日活跃地址数出现小幅下降,但每日成功交易笔数在第三季度呈现增长,这主要是源于近期Moonbeam Ignite活动和Upbit上线。
财务概览

市值
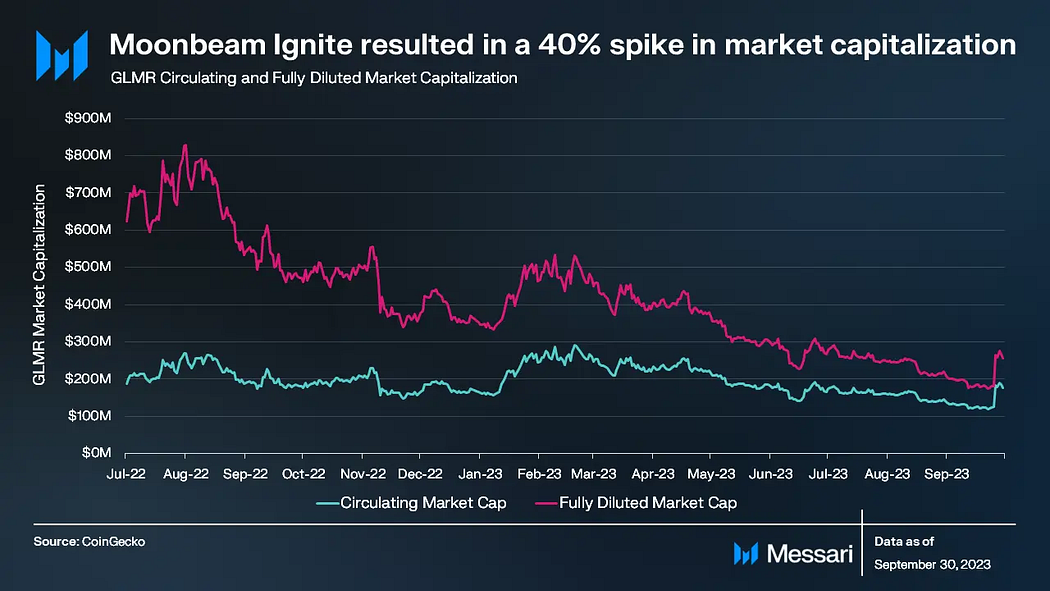
本季度,即使XRP和灰度在法庭上取得胜利,加密货币市场基本上仍保持静止。Moonbeam也反映出了这一趋势,直到上周显着增加了40%。Moonbeam市值的上升来自于Moonbeam Ignite的推出,这是针对其生态系统中的协议的流动性激励计划。截至第三季度末,Moonbeam的流通市值达到1.76亿美元,按市值排名约第175位。
收益

在第二季度,由于Runtime 2302和Xen Crypto部署,Moonbeam收益激增。然而,第三季度收益从16万美元降至8.7万美元,环比下降46%。这使得Moonbeam第三季度与历史平均水平保持一致。
GLMR Token
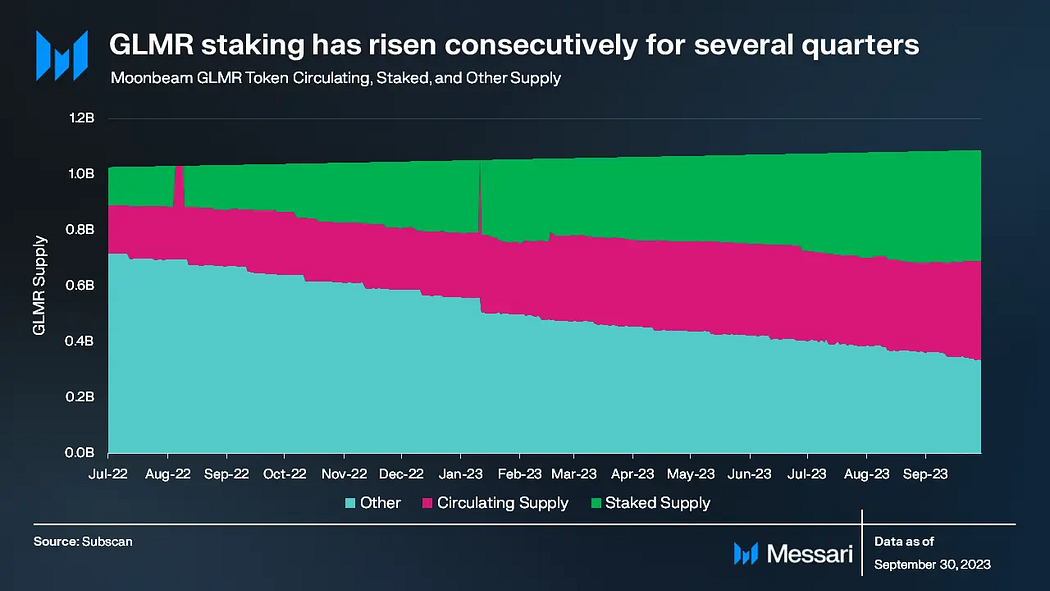
GLMR是Moonbeam网络的原生token,具有多种功能,如奖励收集人、实现链上治理,以及支付网络交易费。GLMR的年通胀为5%,无供应上限。Moonbeam产生的交易费中有80%会被销毁,剩下20%进入财政库。GLMR质押的比例在几个季度中持续上升,到第三季度末,质押的比例达到顶峰,占总供应量的36%。在这个季度Moonbeam引入了投票委托功能。
网络概览
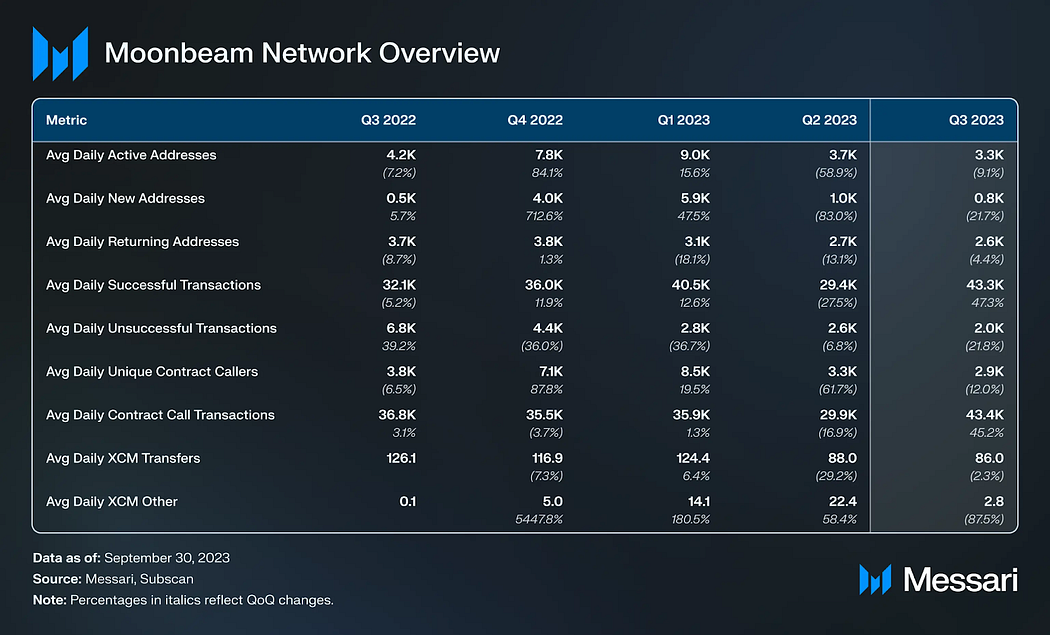
网络使用情况
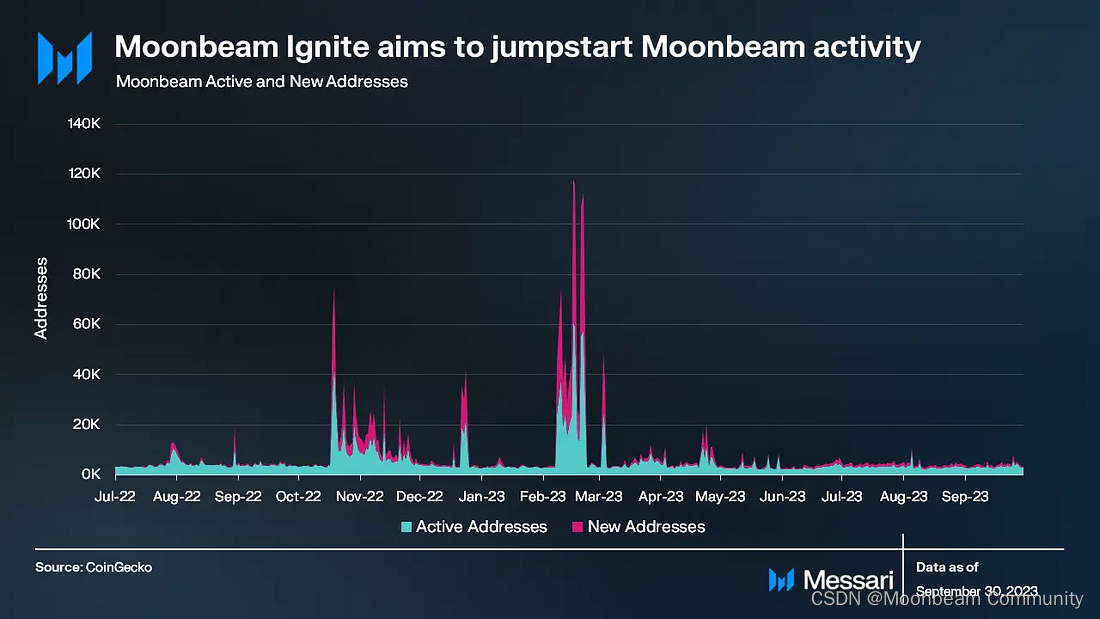
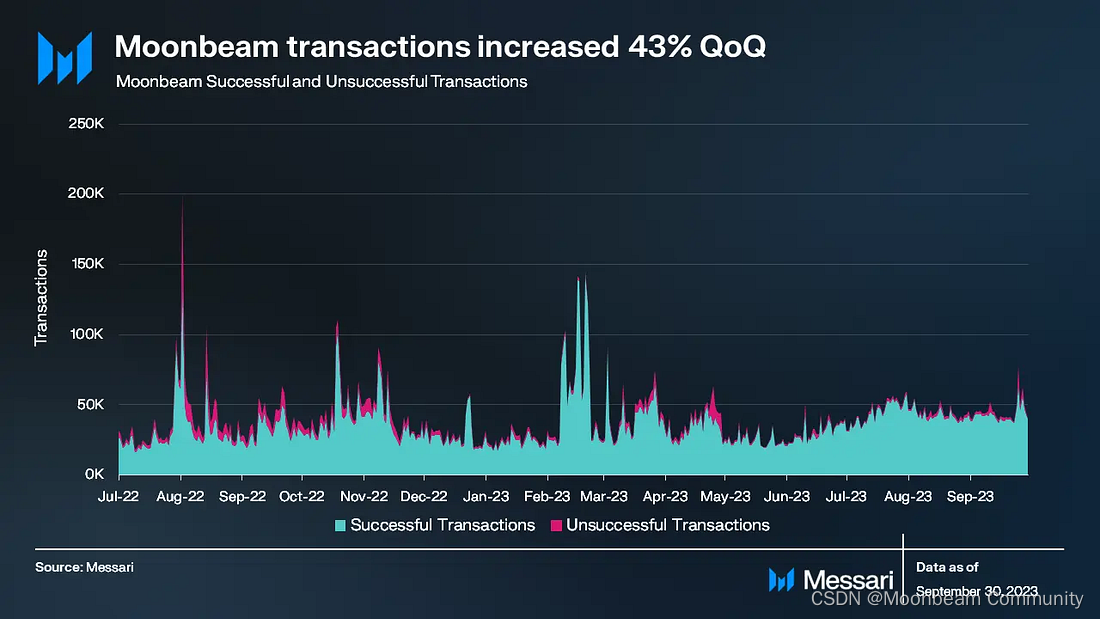
2023年第一季度,Moonbeam的地址活动激增。然而,在接下来的两个季度中,这一活动有所下降,回到了2022年同期的水平。另一方面,Moonbeam的交易量环比增长了43%。可以预料到的是,本季度末交易量的上升是受到Moonbeam Ignite公告的影响。
根据Electric Capital的开发者报告,波卡拥有加密货币领域第二大开发者基础。在波卡生态系统中,Moonbeam拥有最大的开发者群体,本季度拥有超过200名注册开发者。
XCM

跨共识消息格式(XCM)标准化了平行链和其他共识驱动的系统之间通信的消息传递,从而实现资产转移、操作等。6月15日推出的XCM V3带来高级可编程性、与外部网络的桥接功能、跨链锁定、改进的费用支付机制以及对NFT的支持。
从XCM方面来看,Moonbeam在平行链中的活跃度靠前。Moonbeam-Acala通道是最常用的XCM通道。本季度Moonbeam推出了与Centrifuge、Nodle和Origin Trail的新XCM集成。
Moonbeam引入了Moonbeam路由流动性(Moonbeam Routed Liquidity,MRL)。这允许了平行链可以从如以太坊、Solana、Polygon或者Avalanche等生态系统带来流动性。HydraDX是第一条使用MRL的平行链,促进基于Wormhole的Token跨链转移,并通过Moonbeam简化了从以太坊到HydraDX的流动性移动。时至今日,以太坊已通过MRL向HydraDX传递了610万美元的流动性。另外,Interlay平行链也集成了Moonbeam路由流动性。
生态概览
TVL
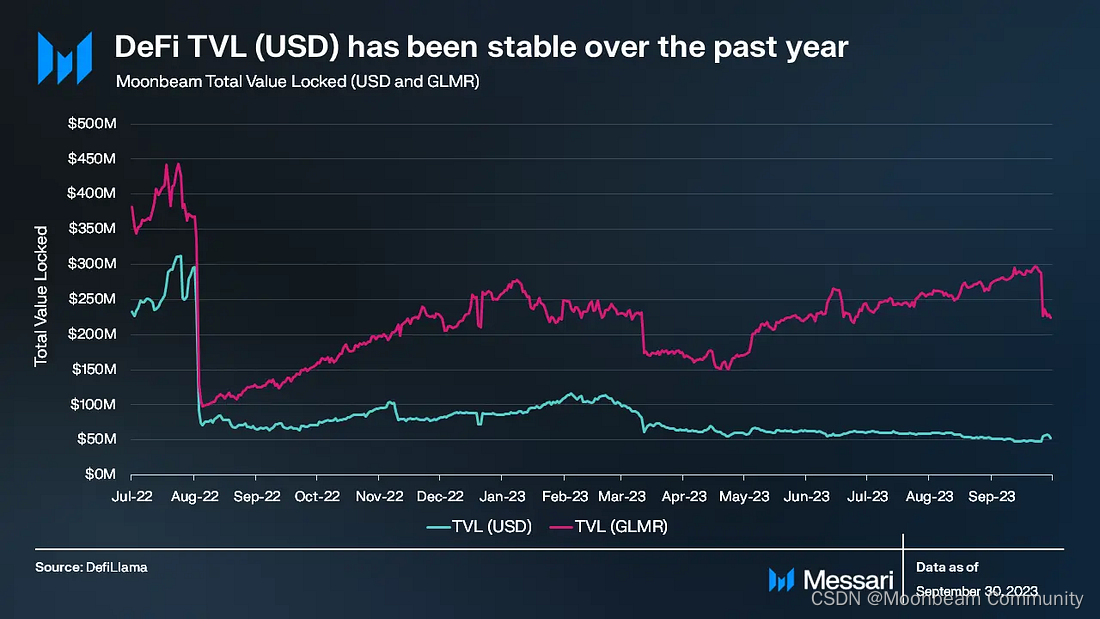
去年,Moonbeam的美元TVL保持相对稳定,但GLMR的TVL持续上升。截至本季度末,Moonbeam的TVL为5,300万美元,在公链中排名约30位。
Moonbeam上TVL最大的Moonwell借贷协议在本季度末TVL为4,200万美元,占Moonbeam累计5,300万美元TVL的79%。其次TVL最大的是StellaSwap和Prime Protocol,分别为3,800万美元和3,500万美元。Moonbeam在第三季度的DeFi多样性得分为3。
值得一提的是,本季度最后一周Uniswap V3上线Moonbeam。
稳定币
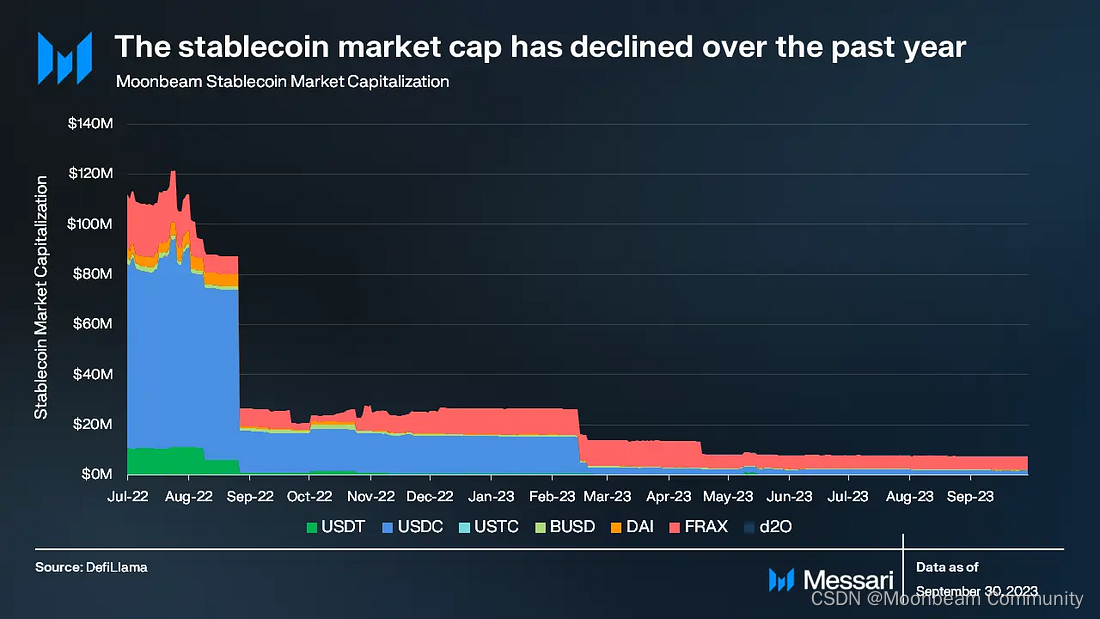
截至本季度末,Moonbeam稳定币市值为800万美元,在公链中排名第40位。原生Frax的市值为500万美元,占Moonbeam稳定币总市值的70%。波卡在本季度引入了对USDC的原生支持,随着Moonbeam开发支持市场,这可能会提升USDC的影响力。重要的是,由于Nomad漏洞事件,Moonbeam的稳定币市值在2022年8月下旬发生了急剧下降。
结语
2023年第三季度,Moonbeam在该季季度最后一周市值显着飙升,在不可预测的加密市场中表现出了韧性。本季度Moonbeam的业绩有喜有忧:虽然收益和TVL等指标环比下降,但交易和质押供应百分比等其他指标却出现增长。尽管XCM消息总数略有下降,但Moonbeam仍然保持着这一重要类别中领先平行链的地位。
展望未来,Moonbeam的目标是通过Moonbeam Ignite发展其网络活动。从更广泛的角度来说,Moonbeam仍然是波卡生态系统中占主导地位的平行链,但与此同时也面临着外部竞争对手的虎视眈眈。