护肤网站模版桂林建站平台哪家好
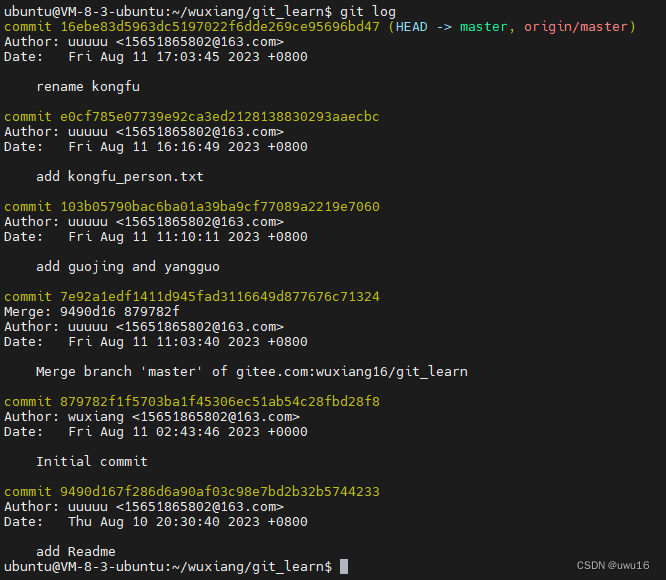
- 通过git log可以查看版本演变历史
主要包括:- commit 哈希id
- 提交的Author信息
- 提交的日期和时间
- commit info信息
git log
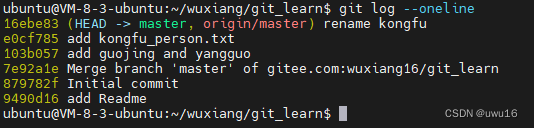
本人常用,显示简洁:
git log --oneline
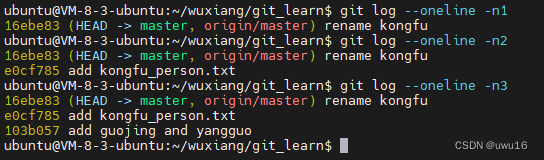
当log条数很多的时候,可以如下指定显示的数量:
git log --oneline -n3
git log
本人常用,显示简洁:
git log --oneline
当log条数很多的时候,可以如下指定显示的数量:
git log --oneline -n3