网站设计一般包括网站结构设计绿色食品网站开发步骤

目录
一、安装MySQL编辑编辑
1、检查MySQL是否安装及版本信息编辑
2、卸载
2.1 rpm格式安装的mysql卸载方式
2.2 二进制包格式安装的mysql卸载
3、安装
二、配置MySQL
1、修改MySQL临时密码
2、允许远程访问
2.1 修改MySQL允许任何人连接
2.2 防火墙的问题
一、安装MySQL

1、检查MySQL是否安装及版本信息
安装前请先检查系统是否安装过mysql
rpm -qa|grep -i mysql![]()
可以看到系统已经安装过mysql数据库
2、卸载
2.1 rpm格式安装的mysql卸载方式
根据查询结果对mysql相关软件包进行卸载。
rpm -e bt-mysql57-5.7.44-1.el7.x86_642.2 二进制包格式安装的mysql卸载
如果mysql是通过二进制包格式安装的,那么rpm –qa|grep mysql 的命令是根本查不到结果的,需要按以下方式进行卸载清除。
首先停止mysql服务,查看运行状态如下图:
#停掉mysql
service mysql stop
#查看状态
service mysql status接下来,查找所有msyql文件进行删除
find / -name mysql
然后,根据查询结果执行删除命令
rm -rf /usr/lib64/mysql同理,全部删除。
最后,查看和删除mysql用户
#查看MySQL用户
id mysql
#删除MySQL用户
userdel mysql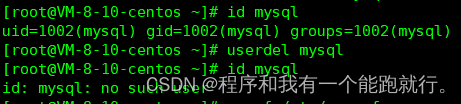
另外,还要删除可能存在的配置文件
rm -f /etc/my.cnf
rm -f /usr/my.cnf![]()
3、安装
- 下载wget命令
yum -y install wget- 在线下载mysql安装包
wget https://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm- 安装MySQL
rpm -ivh mysql57-community-release-el7-8.noarch.rpm- 安装mysql服务
导入 GPG 密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022首先进入cd /etc/yum.repos.d/目录
cd /etc/yum.repos.d/安装MySQL服务(这个过程可能有点慢)
yum -y install mysql-server
- 启动MySQL服务
systemctl start mysqld
可以查看一下是否启动成功
systemctl status mysqld.service

二、配置MySQL
1、修改MySQL临时密码
MySQL安装成功后会有一个临时密码,我们可以使用grep命令查看临时密码先登录进去MySQL,然后修改MySQL密码。
- 获取MySQL临时密码
grep 'temporary password' /var/log/mysqld.log
![]()
- 使用临时密码先登录
mysql -uroot -p

- 把MySQL的密码校验强度改为低风险
set global validate_password_policy=LOW;

- 修改MySQL的密码长度
set global validate_password_length=5;

- 修改MySQL密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'admin'; 
- 退出mysql
exit
- 用新密码登录一下

大功告成!!!
2、允许远程访问
2.1 修改MySQL允许任何人连接
- 首先登录MySQL
mysql -uroot -p

- 创建一个远程登陆的用户以及登录密码(%为任意主机可连接,可设置为特定IP,test为用户名,12345为密码,任意设置)在 MySQL 中为用户 ‘test’ 授予所有数据库的全部权限,,同时启用授权选项。
GRANT ALL PRIVILEGES ON *.* TO 'test'@'%' IDENTIFIED BY '12345' WITH GRANT OPTION;- 刷新权限
flush privileges;- 查询数据库的用户(看到 User: 'test'@'%'; 表示创建新用户成功了)
SELECT DISTINCT CONCAT('User: ''',user,'''@''',host,''';') AS query FROM mysql.user;
2.2 防火墙的问题
使用以下命令来检查 firewalld 状态
sudo systemctl status firewalld如果 firewalld 正在运行,您可能需要配置该防火墙以允许 MySQL 服务器的连接。您可以使用以下命令打开 MySQL 服务的防火墙端口:
sudo firewall-cmd --add-service=mysql --permanent
sudo firewall-cmd --reload这将允许 firewalld 通过默认的 MySQL 端口 3306 接受连接
2.3 使用Navicat连接工具测试
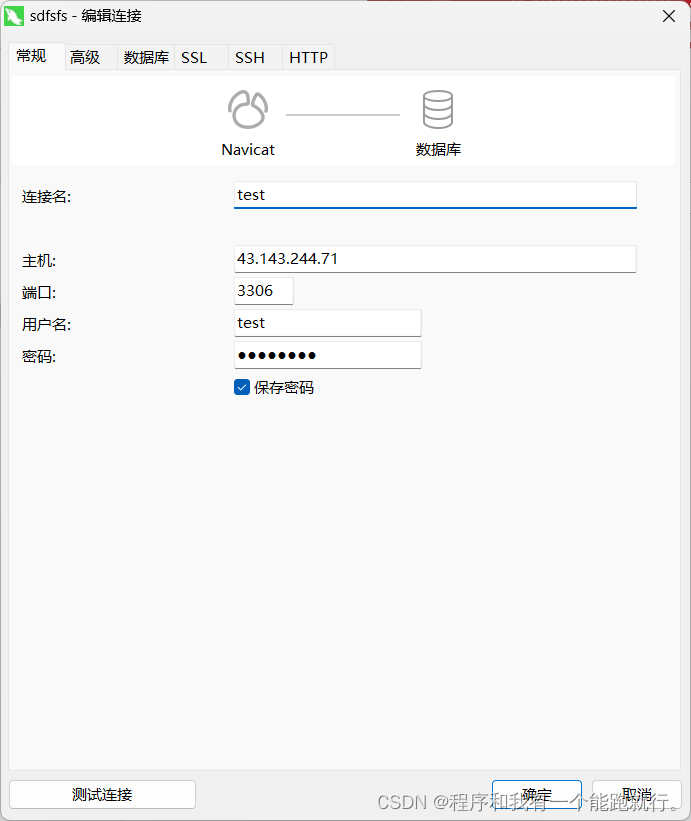

连接成功 ~
