常州制作网站价格建网站都要什么费用
学过C语言的同志们应该都知道位运算符>> 和 << (右移左移),但是这两个运算符在C++中还是我们的输入和输出流操作符,那么这是为什么呢?,了解完本篇文章之后,我们再来回答这个问题。
C++为了增强代码的可读性引入了运算符重载,运算符重载是具有特殊函数名的函数,也具有其 返回值类型,函数名字以及参数列表,其返回值类型与参数列表与普通的函数类似。
函数名字为:关键字operator后面接需要重载的运算符符号。
函数原型:返回值类型 operator操作符(参数列表)
但是
不能通过连接其他符号来创建新的操作符:比如operator@
重载操作符必须有一个类类型参数 用于内置类型的运算符,其含义不能改变,例如:内置的整型+,不 能改变其含义
作为类成员函数重载时,其形参看起来比操作数数目少1,因为成员函数的第一个参数为隐 藏的this
.* :: sizeof ?: . 注意以上5个运算符不能重载
假设我们定义了如下的一个学生类,包含的有学生的年龄,学号,和名字。
#include <iostearm>
#include <string.h>
using namespace std;class Student
{
public:Student(int age, int id, const char* name){_age = age;_id = id;_name = new char[strlen(name) + 1];//const传给非const的类型是不被允许的,通过开辟新的空间拷贝的方式去实现_namestrcpy(_name, name);}~Student(){_age = _id = 0;delete[] _name;_name = nullptr;}void print(){cout << _age << " " << _id << " " << _name << endl;}
private:int _age;int _id;char* _name;
};int main()
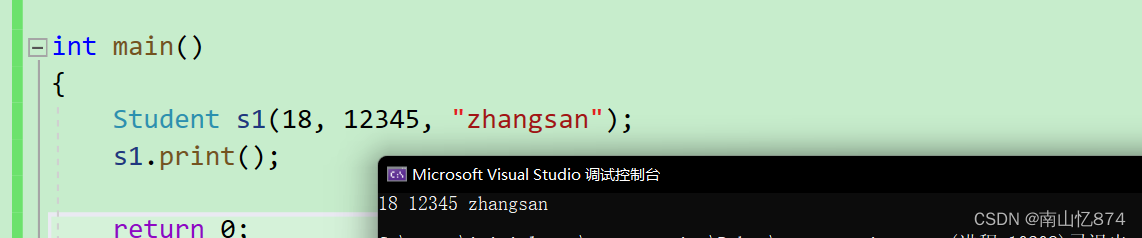
{Student s1(18, 12345, "zhangsan");s1.print();return 0;
}对于自定义类型我们是不能直接使用标准输出cout打印信息的,如下所示:

必须再写一个专门的打印函数。(如果成员变量是public,那么也可以通过直接访问内部成员变量的方式去打印)。
调用该函数去实现相应的功能:
那么如果我们现在就是想要通过cout<<s1来实现打印功能该怎么办呢?
接下来轮到operator(运算符重载关键字)登场了。
我们首先要注意两个重点,一是运算符,而是重载。
operator只能操作之前(语言定义的)存在过的运算符,为该运算符重新赋予新的功能,这种将运算符旧功能通过operator编写的函数,重新为它赋予新的功能就叫做重载。
现在我们接着来谈怎么实现我们的cout<<s1;
如果我们将该函数实现在类的内部,*this就会抢占第一个位置,也就是cout,但是cout实际是ostream类型的并不是Student类型,所以我们将其定义在全局。

接下来我们来一点点的解释,然后再优化一下该函数的缺点。
首先 <<左边的cout会自动的匹配到函数的第一个形参,<<右边的s1会匹配到第二个形参上去(cout << s1)。其实我们也可以将cout和s1分别看成operator<<函数的第一个实参和第二个实参。
为了减少拷贝的次数,所以使用了引用而不是简单的传值。
cout的类型是ostream的
在该函数内部的时候,out是cout的别名,out就相当于cout,我们直接使用即可,但是该类的成员变量都是private类型的,我们不能直接在类的外部进行访问,此时将我们的函数,设置为该类的友元函数即可。
友元函数:可以访问类的内部
或者在类的内部实现三个函数,分别读取对应的三个成员变量(比较的挫不建议)
上面我们实现<<的重载的返回类型是void的,为了和我们标准的cout实现的相同,即cout<<1<<2<<endl;一次打印多个,我们将返回类型改为ostream。
完整的代码如下:
#include<iostream>
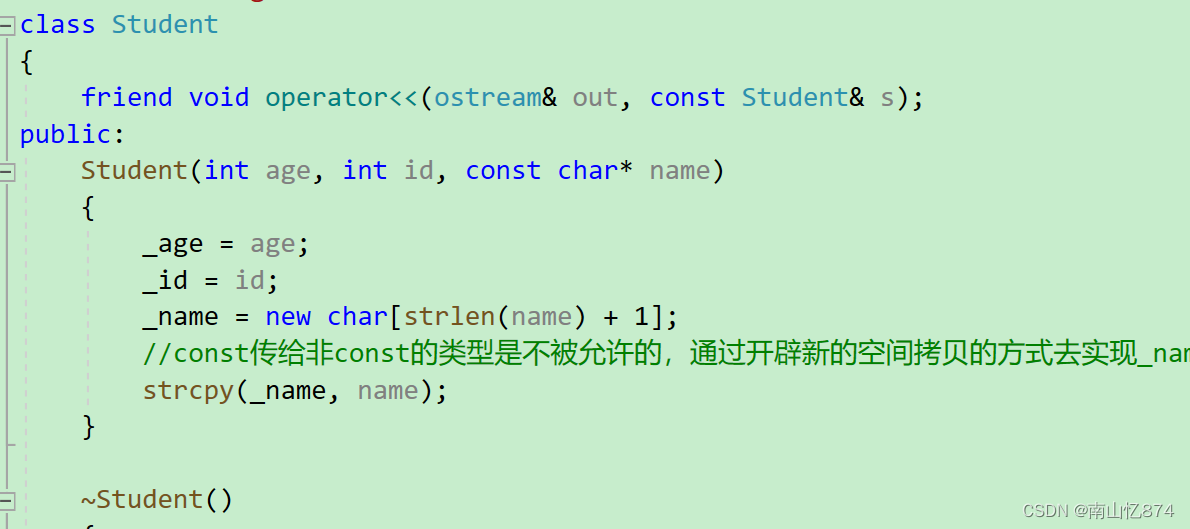
#include <string.h>using namespace std;class Student
{friend void operator<<(ostream& out, const Student& s);
public:Student(int age, int id, const char* name){_age = age;_id = id;_name = new char[strlen(name) + 1];//const传给非const的类型是不被允许的,通过开辟新的空间拷贝的方式去实现_namestrcpy(_name, name);}~Student(){_age = _id = 0;delete[] _name;_name = nullptr;}void print(){cout << _age << " " << _id << " " << _name << endl;}
private:int _age;int _id;char* _name;
};ostream& operator<<(ostream& out, const Student& s)
{out << s._age << " " << s._id << " " << s._name << endl;
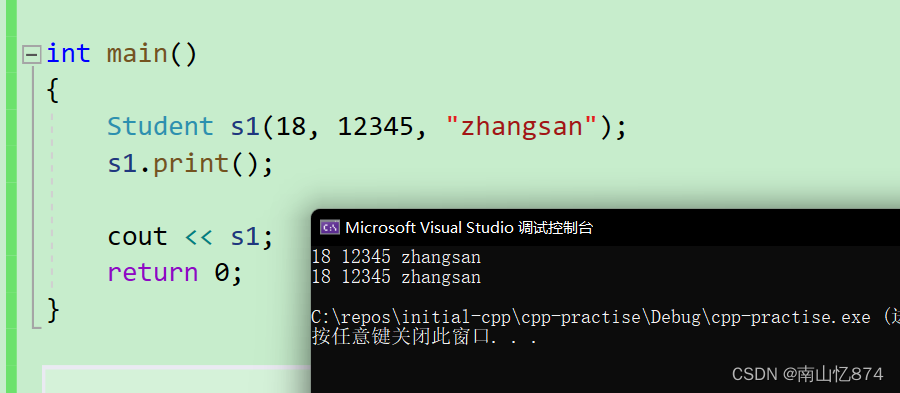
}int main()
{Student s1(18, 12345, "zhangsan");s1.print();cout << s1;return 0;
}运行结果:
运算符重载的用处很大,特别是对于我们的自定义类型,比如日期类的加减法,我们是无法直接对自定义的日期类使用+-的,但是可以使用运算符重载去实现日期类的+-。
我们知道,C++是兼容C的,那么C++的<<就是一个运算符的重载,当然<<在C++中也是可以作为为运算符使用的,如下:
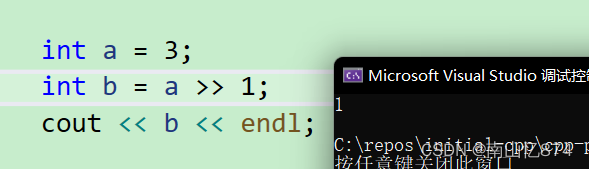
3的二进制右移1位就是0001(十进制1) 。
在C++中会自动识别<<和>>对应的操作数的类型来决定是位运算还是运算符重载<< >>。