土特产网站建设深圳注册公司去哪里注册
MySQL tinyint(1) 、int(32) 与 varchar(255) 长度含义不同
发现 tinyint(1),int(32) 和 varchar(255)
这里面的数字的含义是不同的。
先说数字类型 tinyint 和 int 等
他们能存储的字节大小是与类型绑定的,即定义了 tinyint 或者 int 就确定了能存储的空间大小。
tinyint(1) 和 tinyint(4) 都只能存储 1byte 的大小
int(32) 能存储 4byte 的大小,详细参见官方文档截图。
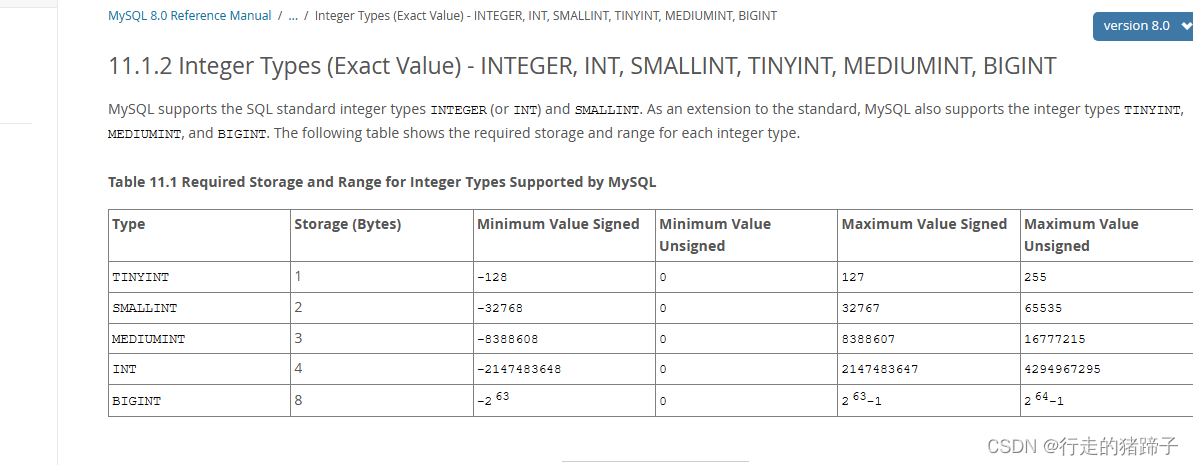
官方文档:https://dev.mysql.com/doc/refman/8.0/en/integer-types.html
数字 1,4,32 对于能存储的字节长度没有影响,参考 stackoverfolw 回答
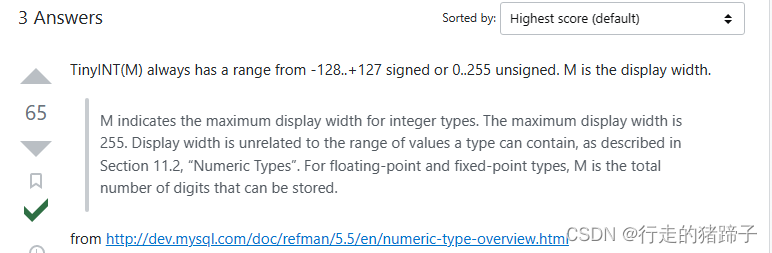
但是 varchar(N) 的数字的含义却不太一样。 这里面 N 的含义是指字符的个数。
varchar 能够存储的最大长度是 65535 bytes。
以 utf8mb 编码为例,一个字符占用 4 字节。
理论上 N 能设置的最大值为 65535 / 4 = 16383
但是实际操作中,我最大能设置 16378 ,怀疑有 5 位用作校验或者其他用途了。(有时候还只能设置成 16377 这个暂时未知为什么

举个例子,varchar(2) 只能保存 2 个字符
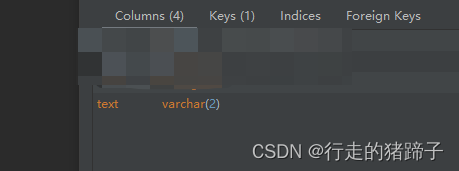
再添加第三个字符的时候即报错
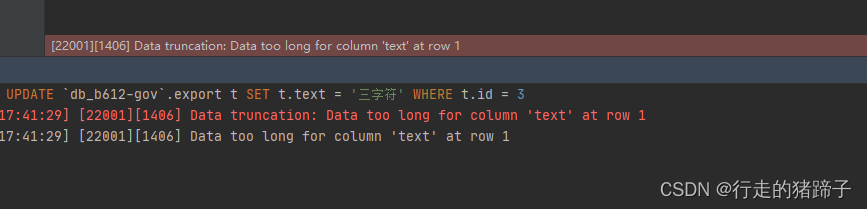
Data truncation: Data too long for column 'text' at row 1
这个错误大家应该很熟悉了