空间链接制作网站网站想改版 权重
目录
Linux磁盘与文件系统管理详解:从基础到实践
一、磁盘基础简述
1️⃣硬盘类型:
2️⃣机械硬盘结构:
3️⃣磁盘容量计算:
公式:磁盘容量=磁头数×柱面数×每磁道扇区数×每扇区字节数
4️⃣接口类型:
二、Linux系统分区
1️⃣ 分区概念:
2️⃣ 分区方式:
3️⃣ 分区实战示例:
三、Linux创建文件系统
1️⃣文件系统概念:
四、挂载与卸载文件系统
1️⃣ 挂载概念:
2️⃣ 挂载操作示例:
3️⃣ 自动挂载配置:
4️⃣卸载操作:
Linux磁盘与文件系统管理详解:从基础到实践
引言:
在Linux系统中,磁盘和文件系统的管理是系统管理员必备的核心技能。本文将从磁盘基础、Linux系统分区、文件系统创建与管理,到LVM逻辑卷管理,全面解析Linux磁盘管理的方方面面。
一、磁盘基础简述
1️⃣硬盘类型:
- 机械硬盘(HDD):通过磁性碟片存储数据,由盘片、磁头、主轴等组成。
- 固态硬盘(SSD):通过闪存颗粒存储数据,读写速度更快,成本较高。
2️⃣机械硬盘结构:
- 盘片:多个盘片,每面一个磁头。
- 磁道:同心圆,最外为0磁道。
- 扇区:磁道等分弧段,最小存储单元(通常512B或4KB)。
- 柱面:相同编号磁道形成的圆柱。
3️⃣磁盘容量计算:
公式:磁盘容量=磁头数×柱面数×每磁道扇区数×每扇区字节数
4️⃣接口类型:
- IDE(ATA/PATA):并行接口,理论速度133MB/s。
- SATA:串行接口,三代理论速度600MB/s。
- SCSI:服务器常用,理论速度320MB/s。
二、Linux系统分区
1️⃣ 分区概念:
- 将硬盘划分为多个独立区域,便于管理和数据组织。
- Linux以挂载点(如/、/home)区分分区,Windows以盘符标识。
2️⃣ 分区方式:
- MBR分区:最多4个主分区(或3主+1扩展),最大支持2TB。
- GPT分区:支持128个分区,无2TB限制,需64位系统。
3️⃣ 分区实战示例:
① 添加20G硬盘(sdb),使用fdisk创建MBR分区:
② 添加4T硬盘(sdc),使用gdisk创建GPT分区:
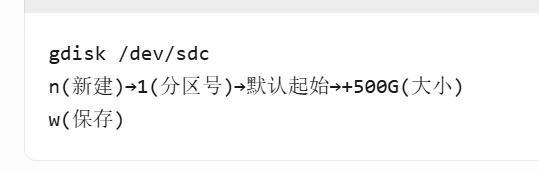
三、Linux创建文件系统
1️⃣文件系统概念:
- 操作系统管理存储设备的机制,规定数据存储方式和访问方法。
2️⃣常见文件系统:
- ext2:无日志,简单高效但恢复慢。
- ext3:日志式,兼容ext2,广泛使用。
- ext4:ext3改进版,支持大文件和大分区。
- XFS:高性能日志文件系统,适合企业级应用。
- Btrfs:支持快照、校验等高级特性。
- SWAP:虚拟内存交换分区。
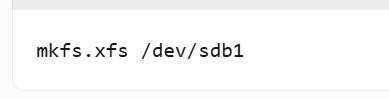
3️⃣创建文件系统示例:
① 格式化sdb1为XFS:
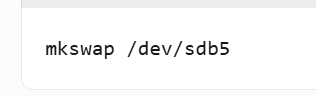
② 创建swap分区(sdb5):
四、挂载与卸载文件系统
1️⃣ 挂载概念:
- 将存储设备映射到目录树的过程,用户通过挂载点访问设备。
2️⃣ 挂载操作示例:
- 临时挂载sdb1到/data:

- 挂载ISO镜像:

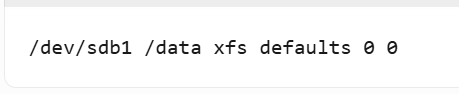
3️⃣ 自动挂载配置:
- 编辑/etc/fstab实现永久挂载:
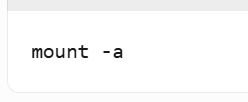
- 刷新挂载信息:
4️⃣卸载操作:
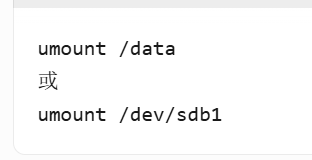
- 卸载/data挂载点:
五、LVM逻辑卷管理
1️⃣LVM概念:
- 逻辑卷管理器,提供灵活的存储管理方案,支持动态调整。
2️⃣LVM组成:
- PV(物理卷):物理磁盘或分区。
- VG(卷组):多个PV组成的存储池。
- LV(逻辑卷):在VG上创建的虚拟分区。
3️⃣LVM创建示例:
- 准备20G硬盘(sdc),创建PV:

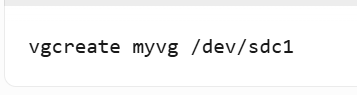
- 创建VG(myvg):
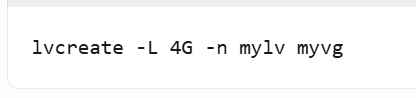
- 创建LV(mylv):
- 格式化并挂载:
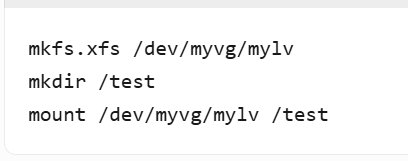
4️⃣LVM扩容示例:
扩展mylv1增加2G空间
