长沙网站制作多少钱wordpress主题改字体
最近有偶然的机会学习了一次QPSK防止以后忘记又得找资料,这里就详细的记录一下
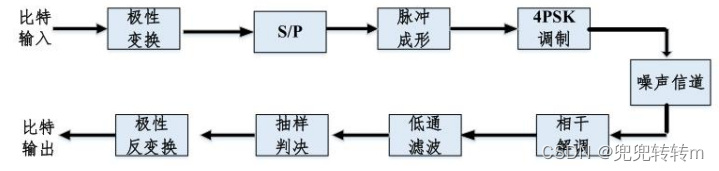
基于 QPSK 的通信系统如图 1 所示,QPSK 调制是目前最常用的一种卫星数字和数 字集群信号调制方式,它具有较高的频谱利用率、较强的抗干扰性、在电路上实现也较为简单,在后文仅仅使用MATLAB进行模拟。
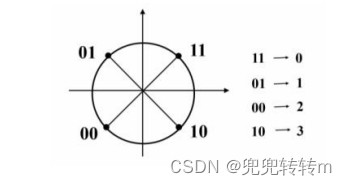
其相位图如图 2 所示,二进制数 0 和 1 分别表示两个相位,为了提高传输速率,通 常可以采用多项调制的方法,即将待发的数字信号按两比特一组的方式组合,两位二进 制数的组合方式又四种—(00,01,10,11)。每个组合是一个双比特码,通常可以用四 个不同的相位值表示这四组双比特码。在传输过程中,相位改变一次,传输两个二进制 数。这种调相方法成为四项调相或四项调制,广泛广泛应用 于卫星链路、数字集群等 通信业务。
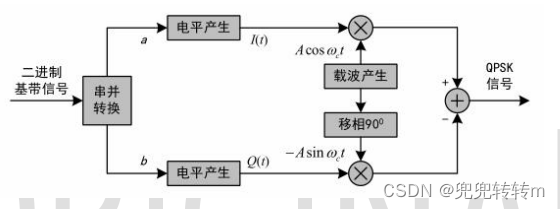
如图 3 所示,QPSK 信号可以采用正交调制器来实现
根据图1和图3的原理图,就可以开始着手写MATLAB代码了。 我将其分为以下几个方面
- 模拟源信号
- 源信号->双极性信号
- 双极性信号转为QPSK信号
- QPSK信号经过模拟信道传输,引起失真。
- 采用相干解调法分离QPSK信号。
- 低通滤波过滤噪音
- 抽样判决获得信号
- 最后将信号极性反转获得源信号
QPSK详细代码如下,在代码中已经做好注释了。
%% 采用代码实现的4PSK通信系统仿真
% 假设在T=1,加入高斯噪声
clc;
clear all;
close all;
%% 发端
% 1.调制,生成二进制信号
bit_in = randi([0 1],1000,1);
% 2.变为双极性码
data = -2*bit_in+1;
% 3.串并转换模块:奇数位为I,偶数为为Q
data_I = data(1:2:1000); % 间断获取 I
data_Q = data(2:2:1000); % 间断获取 Q
data_I1=repmat(data_I',20,1);
data_Q1=repmat(data_Q',20,1);% 按列优先将data_I1中的数据存入data_I2
for i=1:1e4data_I2(i)=data_I1(i);data_Q2(i)=data_Q1(i);
end% 4.产生升余弦的基带信号
f=0:0.1:1;
xrc=0.5+0.5*cos(pi*f); data_I2_rc=conv(data_I2,xrc)/5.5;
data_Q2_rc=conv(data_Q2,xrc)/5.5;figure
subplot(2,2,1)
stem(bit_in(1:20),'black','LineWidth',2);
axis([0,20,0,1]);
title("发送的消息序列");
subplot(2,2,2)
plot(f,xrc,'black','LineWidth',2);
title("升余弦信号");
subplot(2,2,3)
plot(data_I2_rc(1:20),'black','LineWidth',2);
title("升余弦I信号");
subplot(2,2,4)
plot(data_Q2_rc(1:20),'black','LineWidth',2);
title("升余弦Q信号");% 5. 正交调制(调相法:将基带数字信号(双极性)与载波信号直接相乘的方法)
f1=1; % 载波频率
t1=0:0.1:1e3+0.9;I_rc=data_I2_rc.*cos(2*pi*f1*t1);
Q_rc=data_Q2_rc.*sin(2*pi*f1*t1);
x=(sqrt(1/2).*I_rc+sqrt(1/2).*Q_rc);figure(1)
subplot(2,1,1);
plot(t1,x,'black','LineWidth',2); xlabel('t'); ylabel('幅度');
grid on;
axis([0 1/f1*10 -1.2 1.2]); % 输出2个周期的信号
title('QPSK信号'); %% 6.仿真信道噪声
n0=rand(size(t1))/2;
y=x+n0;subplot(2,1,2);
plot(t1,y,'black','LineWidth',2); xlabel('t'); ylabel('幅度');
grid on;
axis([0 1/f1*10 -2 2]); % 输出2个周期的信号
title('带噪声的QPSK信号'); %% 仿真接收端
% 7.正交解调:只能采用相干解调
I_demo=y.*cos(2*pi*f1*t1);
Q_demo=y.*sin(2*pi*f1*t1);
% 8.低通滤波
I_recover=conv(I_demo,xrc);
Q_recover=conv(Q_demo,xrc);
I=I_recover(11:10010);
Q=Q_recover(11:10010);% 9.抽样判决
data_recover=[];
for i=1:20:10000data_recover=[data_recover I(i:1:i+19) Q(i:1:i+19)];
end
bit_recover=[];
for i=1:20:20000if sum(data_recover(i:i+19))>0data_recover_a(i:i+19)=1;bit_recover=[bit_recover 1];elsedata_recover_a(i:i+19)=-1;bit_recover=[bit_recover -1];end
end% 10.变为单极性码
bit_recovered=(1-bit_recover)/2;
figure(2)
subplot(2,1,1)
stem(bit_in(1:20),'black','LineWidth',2);
axis([0,20,0,1]);
title("发送的消息序列");subplot(2,1,2)
stem(bit_recovered(1:20),'black','LineWidth',2);
axis([0,20,0,1]);
title("接收的消息序列");figure(3)
subplot(2,1,1)
stem(bit_in(1:20),'black','LineWidth',2);
axis([0,20,0,1]);
title("发送的消息序列");subplot(2,1,2)
stem(data(1:20),'black','LineWidth',2);
axis([0,20,-1,1]);
title("双极性码");
set(gcf,'color','w')BSPK的代码也贴在这里
clc
clear
close all;%%初始化参数设置
data_len = 100000; % 原始数据长度
SNR_dB = 0:10; % 信噪比 dB形式
SNR = 10.^(SNR_dB/10); % Eb/N0
Eb = 1; % 每比特能量
N0 = Eb./SNR ; %噪声功率
error2 = zeros(1,length(SNR_dB)); % 码元错误个数
simu_ber_BPSK = zeros(1,length(SNR_dB)); % 仿真误误码率
theory_ber_BPSK = zeros(1,length(SNR_dB)); % BPSK理论误码率
demod2_signal= zeros(1,data_len); % 解调信号%%基带信号产生
data_source = round(rand(1,data_len)); % 二进制随机序列%%BPSK基带调制
send_signal2 = (data_source - 1/2)*2; % 双极性不归零序列 %%高斯信道无编码
for z = 1:length(SNR_dB)noise2 = sqrt(N0(z)/2) * randn(1,data_len); %高斯白噪声receive_signal2 = send_signal2 + noise2;demod_signal2 = zeros(1,data_len);for w = 1:data_lenif (receive_signal2(w) > 0)demod_signal2(w) = 1; % 接收信号大于0 则判1elsedemod_signal2(w) = 0; % 接收信号小于0 则判0endend%统计错误码元个数for w = 1:data_lenif(demod_signal2(w) ~=data_source(w) )error2(z) = error2(z) + 1; % 错误比特个数endend%计算误码率simu_ber_BPSK(z) = error2(z) / data_len; % 仿真误比特率theory_ber_BPSK(z) = qfunc(sqrt(2*SNR(z))); % 理论误比特率
end%%二进制序列、基带信号图像
figure(1);
stem(data_source);
title("二进制随机序列");
axis([0,50,0,1]);
figure(2);
stem(send_signal2);
title("BPSK基带调制--发送信号");
axis([0,50,-1.5,1.5]);figure(4);
stem(noise2);
title("高斯白噪声");
axis([0,50,-0.5,0.5]);figure(5)
stem(receive_signal2);
title("接收信号");
axis([0,50,-1.5,1.5]);figure(7)
stem(demod_signal2);
title("解调信号");
axis([0,50,0,1]);figure(8);semilogy(SNR_dB,simu_ber_BPSK,'M-X',SNR_dB,theory_ber_BPSK,'k-s'); grid on;
axis([0 10 10^-5 10^-1])
xlabel('Eb/N0 (dB)');
ylabel('BER'); legend('BPSK仿真误码率','BPSK理论误码率'); %%画星座图
scatterplot(send_signal2);
title('发送信号星座图');
scatterplot(receive_signal2);
title('接收信号星座图');
scatterplot(demod_signal2);
title('解码信号星座图');MPSK代码
clc;
clear all;
close all;
%% 调用库函数实现MPSK的通信系统仿真M=4;
cycl=80; % 运行次数
SNR=0:1:30; % 信噪比
s=randi([0 M-1],1,1000); % 输入信息一行1000列;BER1=zeros(cycl,length(SNR));for n=1:cyclfor k=1:length(SNR)x=pskmod(s,M,pi/4); % M进制PSKy=awgn(x,SNR(k),'measured'); % 在传输序列中加入噪声r=pskdemod(y,M,pi/4); % 解调r1=reshape(r',1,[]);[num,rat]=biterr(r1,s,log2(M)); % 误码率计算BER1(n,k)=rat;end
endfigure(1)
subplot(2,1,1)
stem(s(1:20),'black','LineWidth',2);
axis([0,20,0,M]);
title("发送的消息序列");subplot(2,1,2)
stem(r1(1:20),'black','LineWidth',2);
axis([0,20,0,M]);
title("接收的消息序列");%% 8PSK
M=8;
cycl=80; % 运行次数
SNR=0:1:30; % 信噪比
s=randi([0 M-1],1,1000); % 输入信息一行1000列;BER2=zeros(cycl,length(SNR));for n=1:cyclfor k=1:length(SNR)x=pskmod(s,M,pi/4); % M进制PSKy=awgn(x,SNR(k),'measured'); % 在传输序列中加入噪声r=pskdemod(y,M,pi/4); % 解调r1=reshape(r',1,[]);[num,rat]=biterr(r1,s,log2(M)); % 误码率计算BER2(n,k)=rat;end
endfigure(2)
subplot(2,1,1)
stem(s(1:20),'black','LineWidth',2);
axis([0,20,0,M]);
title("原始消息序列");subplot(2,1,2)
stem(r1(1:20),'black','LineWidth',2);
axis([0,20,0,M]);
title("传递消息序列");% 统计平均误码率
figure(3)BER1=mean(BER1);
subplot(2,1,1)
semilogy(SNR,BER1,'k-o','LineWidth',2);
xlabel('SNR/dB'); ylabel('BER');
title("4PSK");
grid onBER2=mean(BER2);
subplot(2,1,2)
semilogy(SNR,BER2,'k-o','LineWidth',2);
xlabel('SNR/dB'); ylabel('BER');
title("8PSK");
grid onQAM代码也在这里
clc;
clear all;
close all;
%% 基于16QAM的通信系统仿真
% 发端
nbit=10000;
M=16; % M表示QAM调制的阶数
k=log2(M);
graycode=[0 1 3 2 4 5 7 6 12 13 15 14 8 9 11 10]; % 格雷映射编码规则
EsN0=5:20; % 信噪比范围
snr=10.^(EsN0/10); % 将db转换为线性值
% 产生16进制的消息符号
s=randi([0,1],1,nbit);
s_reshape=reshape(s,k,nbit/k)'; % 对数据流进行分组,对于16QAM,则每4位一组
msg=bi2de(s_reshape,'left-msb'); % 转化成10进制,作为qammod的输入
% 进行格雷映射
msg1=graycode(msg+1);
% 调制
r=qammod(msg1,M); % 调用matlab中的qammod函数,16QAM调制方式的调用(输入0到15的数,M表示QAM调制的阶数)得到调制后符号
spow1=norm(r).^2/nbit; % 取a+bj的模.^2得到功率除整个符号得到每个符号的平均功率
for i=1:length(EsN0)% 信道sigma=sqrt(spow1/(2*snr(i))); % 16QAM根据符号功率求出噪声的功率x=r+sigma*(randn(1,length(r))+1i*randn(1,length(r))); % 16QAM混入高斯加性白噪声% 16QAM的解调y1=qamdemod(x,M); % 格雷逆映射y2=graycode(y1+1); % 返回译码出来的信息,十进制test=de2bi(y2,k,'left-msb');y3=reshape(test',1,nbit);[err1,ber1(i)]=biterr(s,y3);
end
%% 绘图
figure(1)
subplot(2,1,1)
stem(s(1:20),'black','LineWidth',2);
axis([0,20,0,1.2]);
title("发送的消息序列");subplot(2,1,2)
stem(y3(1:20),'black','LineWidth',2);
axis([0,20,0,1.2]);
title("接收的消息序列");scatterplot(r); % 调用matlab中的scatterplot函数,画星座点图
scatterplot(x); % 调用matlab中的scatterplot函数,画rx星座点图% 16QAM调制信号在AWGN信道的性能
figure( )
semilogy(EsN0,ber1,'black','LineWidth',2); % ber ser比特仿真值 ser1理论误码率 ber1理论误比特率
title('16QAM调制信号在AWGN信道的性能分析');grid;
xlabel('Es/N0(dB)');
ylabel('误比特率');