亚马逊平台的运营模式搜索引擎优化seo多少钱
现在的OCR软件很多,有在线的也有本地的,单识别文字功能还行,不过能批量识别的好像不多,网上搜了几个都不怎么好用。尤其是识别身份证件之类的软件,并且还能提取出识别到的信息,比如姓名 名族地址等等更少。
之前也写过一个,功能欠缺,这次重新改了下,效果还行,速度略慢,方便使用。
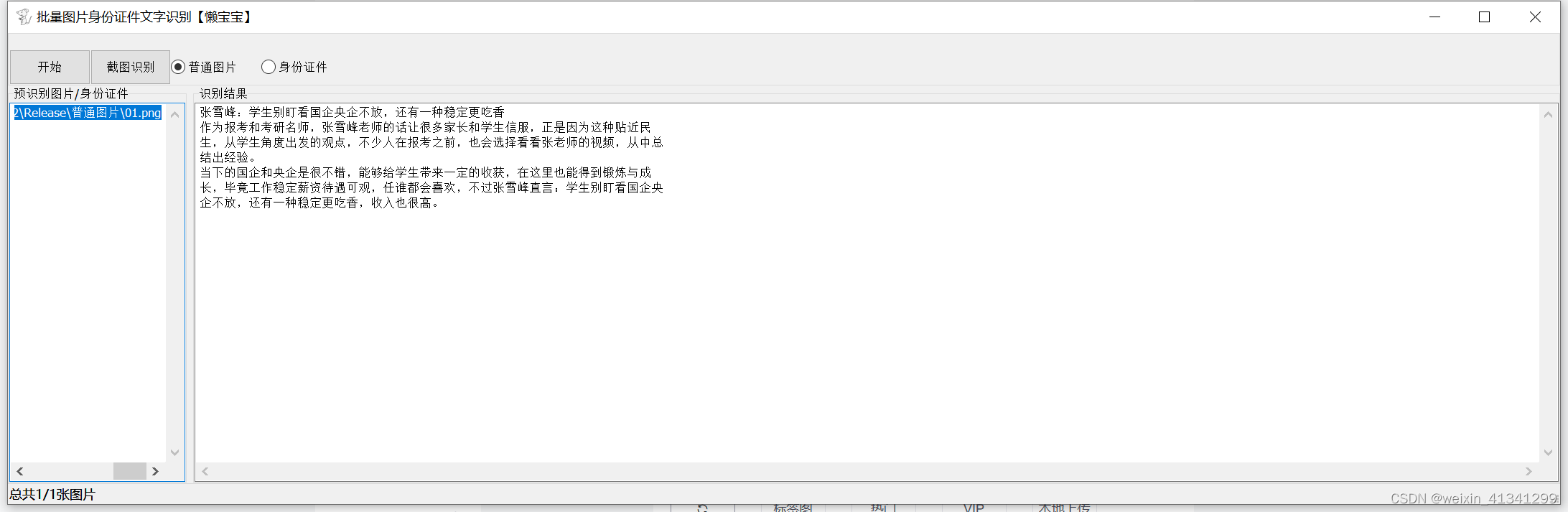
待识别图片:

识别结果:
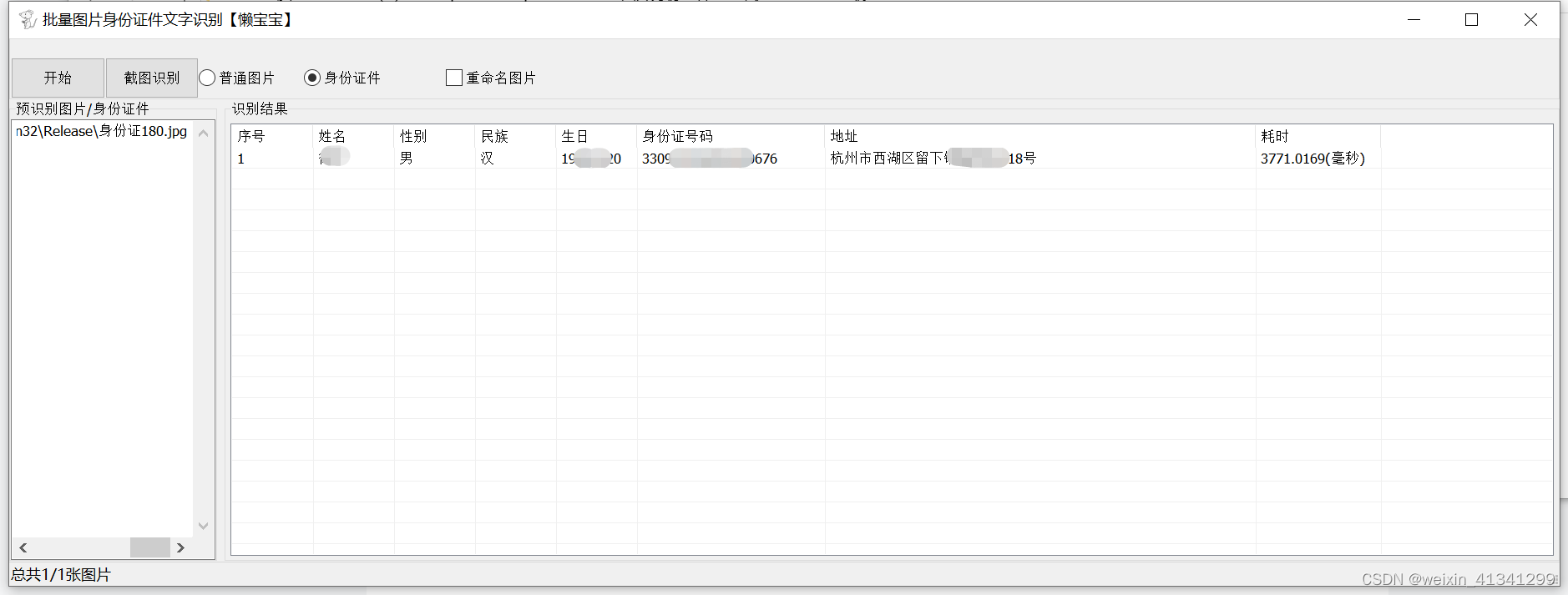
身份证件识别:
软件名称:批量图片身份证件识别软件 界面如上图
双击第一个窗口,导入需要批量识别的图片,再点击开始即可批量识别图片中的文字,
对于身份证件,本软件可以直接提取具体的姓名 性别 名族 身份证号码以及住址,简单好用。
备注,这个软件一般只会用于需要大批量识别图片中的文字,并需要保存才有用。
如果只是识别少量的话,直接用微信、QQ等免费文字识别工具即可,识别速度快免费精度又高。