全能网站服务器discuz 转 wordpress
1、Rewrite的定义
rewrite功能就是使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。rewrite只能放在 server { }, location { }, if { }中,并且只能对域名后边的除去传递的参数外的字符串起作用。 例如location 只能对域名后边的除去传递的参数外的字符串起作用,例如http ://www. kgc.com/index.ph p?id= 1 只对/i ndex. php 重写。如果想对域名或参数字符串起作用, 可以使用if 全局变星匹配, 也可以使用proxy_pass反向代理。
1.1:rewrite跳转场景
- 可以调整用户浏览的URL , 看起来更规范, 合乎开发及产品人员的需求。
- 为了让搜索引擎搜录网站内容及用户体验更好, 企业会将动态URL 地址伪装成静态地址提供服务。
- 网址换新域名后, 让旧的访问跳转到新的域名上。例如, 访问京东的360buy. com 会跳转到jd .com 。
- 根据特殊变簸、目录、客户端的信息进行URL 调整等。
1.2:rewrite跳转实现
Nginx 是通过ngx_http_rewrite_module 模块支持url 重写、支持if 条件判断, 但不支持else 。另外该模块需要PCRE 支持,应在编译N ginx 时指定PCRE 支持,默认已经安装。
根据相关变量重定向和选择不同的配置, 从一个location 跳转到另一个location , 不过这样的循环最多可以执行10 次, 超过后Nginx 将返回500 错误。同时, 重写模块包含set 指令,来创建新的变量并设其值, 这在有些情景下非常有用的, 如记录条件标识、传递参数到其他location 、记录做了什么等等。rewrite 功能就是使用Nginx 提供的全局变量或自己设置的变量, 结合正则表达式和标志位实现url 重写以及重定向。
1.3: Nginx 正则表达式
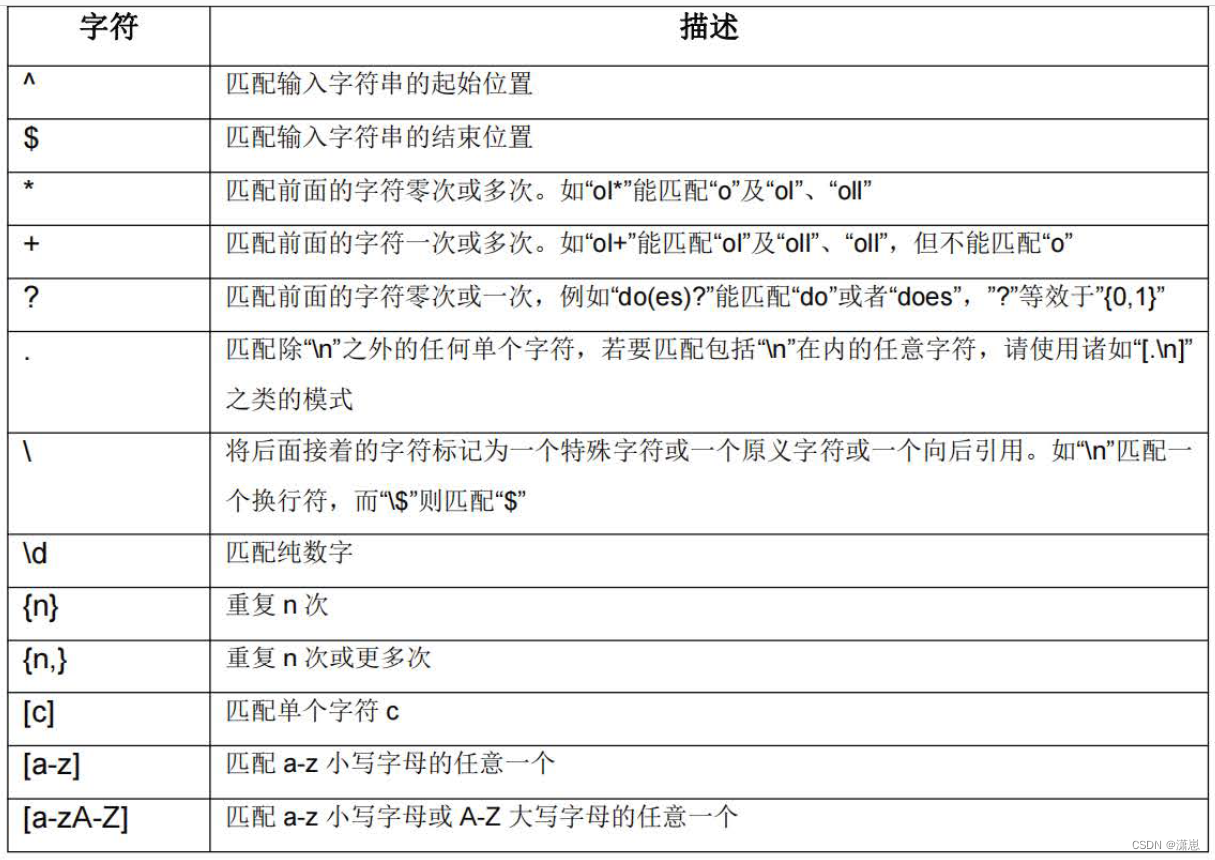
2:Nginx Rewrite 基本操作
2.1:Rewrite 语法
Rewrite 命令的语法如下所示,其中regex 表示正则匹配规则、rep lacement 表示跳转后的内容、flag 表示rewrite 支持的flag 标记。
rewrite< regex>< replacement> [flag];
flag 标记说明:
- last: 相当千Apache 的[L]标记, 表示完成rewrite 。
- break: 本条规则匹配完成即终止, 不再匹配后面的任何规则。
- redirect: 返回302 临时重定向, 浏览器地址会显示跳转后的URL 地址, 爬虫不会更新url(因为是临时) 。
- permanent: 返回301 永久重定向, 浏览器地址栏会显示跳转后的URL 地址, 爬虫更新url 。
last 和break 区别是: last 一般写在server 和if 中, 而break 一般使用在location 中。last 不终止重写后的urI 匹配, 即新的url 会再从server走一遍匹配流程, 而break 终止重写后的匹配。
2.2:Location 分类
location 大致可以分为三类, 语法如下:
location = patt{}[精准匹配]
location patt{}[一般匹配]
location~ patt {}[正则匹配]
- ~ : 表示执行一个正则匹配, 区分大小写。
- ~*: 表示执行一个正则匹配, 不区分大小写。
- !~: 表示执行一个正则匹配, 区分大小写不匹配。
- !~* : 表示执行一个正则匹配, 不区分大小写不匹配。
- ^~: 表示普通字符匹配。使用前缀匹配。如果匹配成功, 则不再匹配其他location 。
- = : 进行普通字符精确匹配, 也就是完全匹配。
- @ : 它定义一个命名的location , 使用在内部定向时, 例如error_page, try_files 。
2.3:Location 优先级
在Nginx 的location 配置中location 的顺序没有太大关系。匹配优先级和location 表达式的类型有关: 相同类型的表达式,字符串长的会优先匹配。
- 等号类型( = ) 的优先级最高。一旦匹配成功, 则不再查找其他匹配项。
- ^~类型表达式。一旦匹配成功, 则不再查找其他匹配项。
- 正则表达式类型( ~和~* )的优先级次之。
- 常规字符串匹配类型。按前缀匹配。
- 通用匹配( /) ' 如果没有其它匹配, 任何请求都会匹配到。
从功能看rewrite 和location 似乎有点像, 都能实现跳转,主要区别在千rewrite 是在同一域名内更改获取资源的路径, 而location 是对一类路径做控制访问或反向代理,还可以proxy_pass 到其他机器。很多情况下rewrite 也会写在location 里, 它们的执行顺序如下:
(1) 执行server 块里面的rewrite 指令。
(2) 执行location 匹配。
(3) 执行选定的location 中的rewrite 指令。