django 网站开发外贸网站建设推广
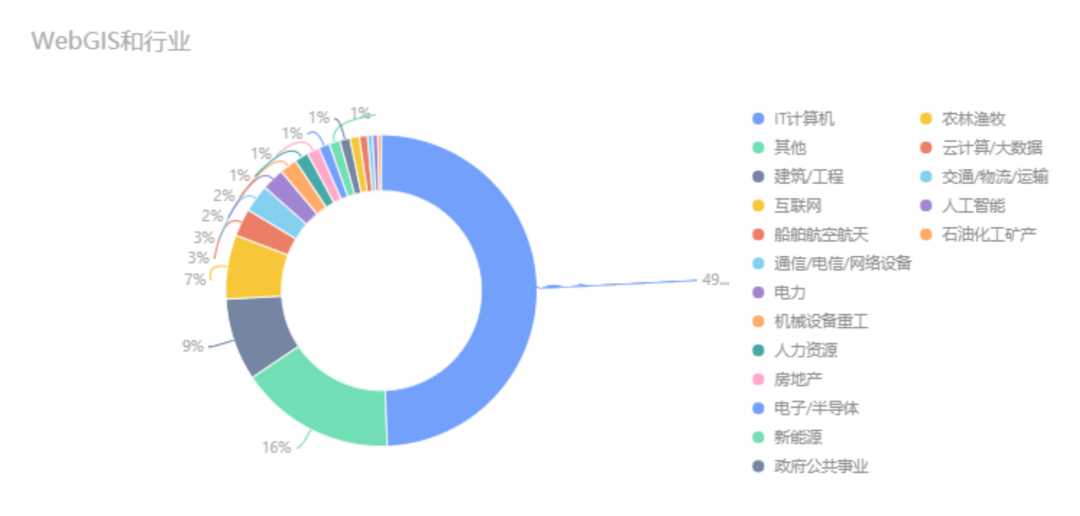
之前我们给大家整理汇总了WebGIS在招岗位的一些特点,包括行业、学历、工作经验等。WebGIS招聘原来看重这个!整理了1300多份岗位得出来的干货!
很多同学好奇,这些招GIS开发的都是哪些公司?主要是做什么的?
今天给大家盘点几个典型案例,让大家知其然也知其所以然。了解其中的原理,才能对职业选择有更好的判断。
IT计算机软件
昨天我们盘点过,IT计算机软件是招聘WebGIS最多的行业,其中有哪些公司?
像我们比较熟悉的大厂华为、高德,腾讯注资的飞渡科技等都赫然在列。
还有一些耳熟能详的GIS头部企业,吉奥时空、中科星图、航天宏图、上海数慧、中地数码、超图软件、易智瑞等等都在招聘GIS开发工程师。
华为
华为高德等大厂为什么要招GIS开发?
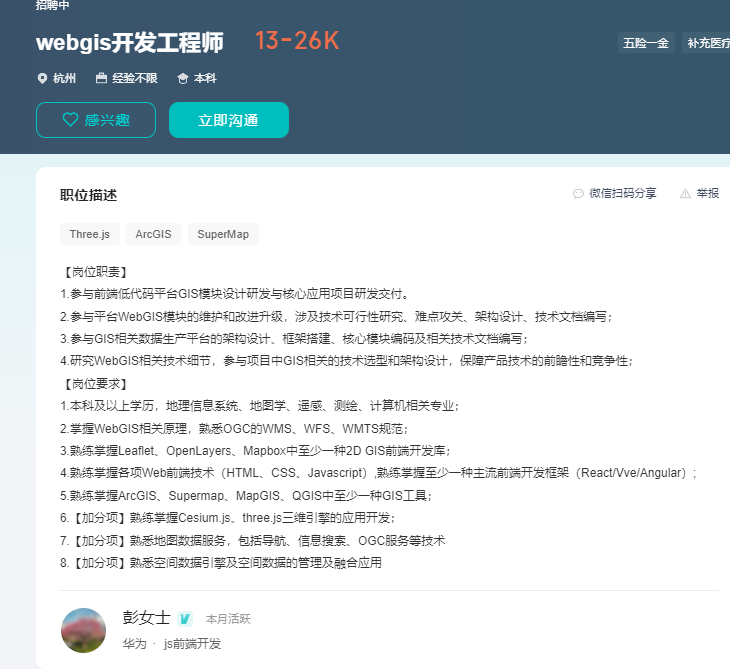
之前我们就介绍过,华为等大厂已经进军高精地图行业,为自动驾驶以及智慧城市数字化建设等业务铺路。
这些都和WebGIS息息相关。
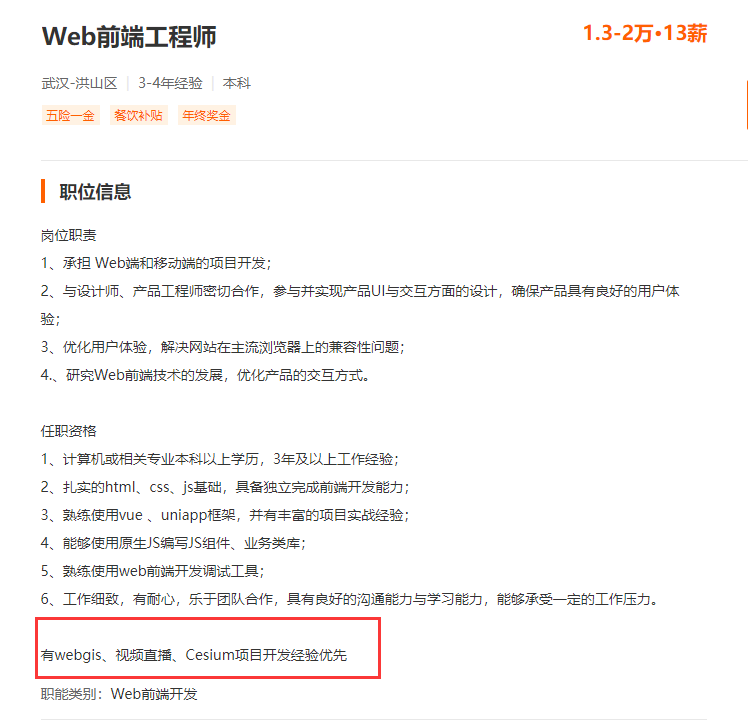
高德
高德偏向无人机应用,要求有cesium和WebGIS开发工作经验优先:
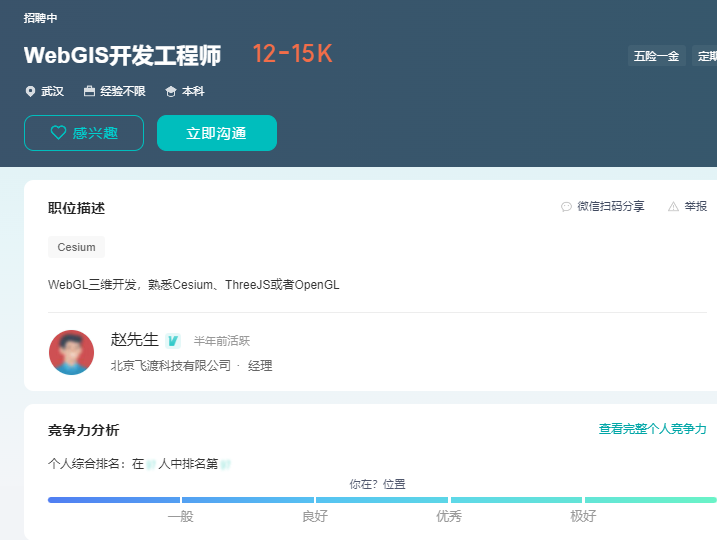
飞渡科技
我们之前也介绍过,主要产品是做融合地理空间、工程BIM、游戏影视、仿真模拟、人工智能、大数据、云计算等技术领域,为智慧城市、智慧园区、智慧建筑、智慧工程、智能工业等行业提供专业的数字孪生产品和服务。
招聘GIS开发工程师,再正常不过了。
其他的GIS头部企业就不用多说了,大部分是有研发GIS相关的软件,提供智慧城市解决方案,承接一些政府项目。
拿中地数码举例,主要以mpgis为载体,提供软件(桌面GIS、服务器GIS、云GIS等)和其相关解决方案(智慧城市、智慧公安、智慧市政等)。

建筑工程
这类公司大部分以勘测、地规等相关的企业,例如南京测绘勘察院、长江勘测规划院、广东国地规划、中控技术股份、上海市政工程设计研究总院等等。
这里列举几个典型案例:
亚信科技
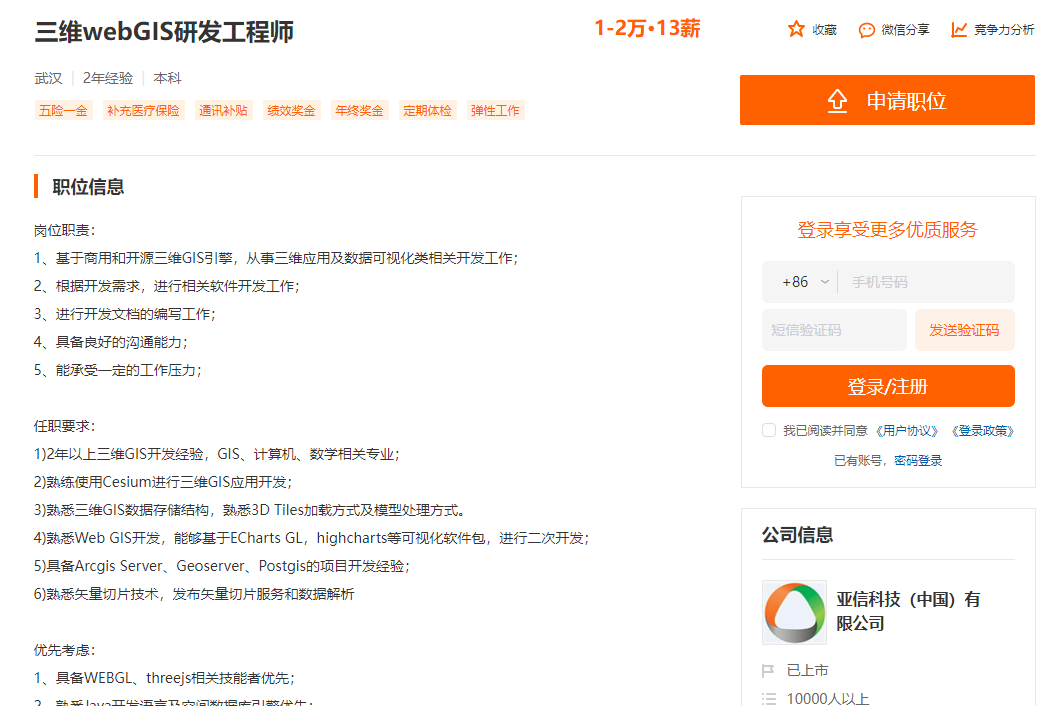
亚信科技控股是上市公司,成立于1993年,公司业务以5G、云计算、人工智能、物联网、大数据等新兴技术为主要扩张方向,开创新业务,探索新模式,助力企业数字化转型。
综上,他家还是一家试图往数字化市场转型的解决方案提供商。
南京测绘勘察院
公司主营测绘地理信息、勘察与岩土设计、三维城市规划与设计、智慧城市系统集成四大专业方向。因此不难理解他们为什么要招聘GIS开发工程师。
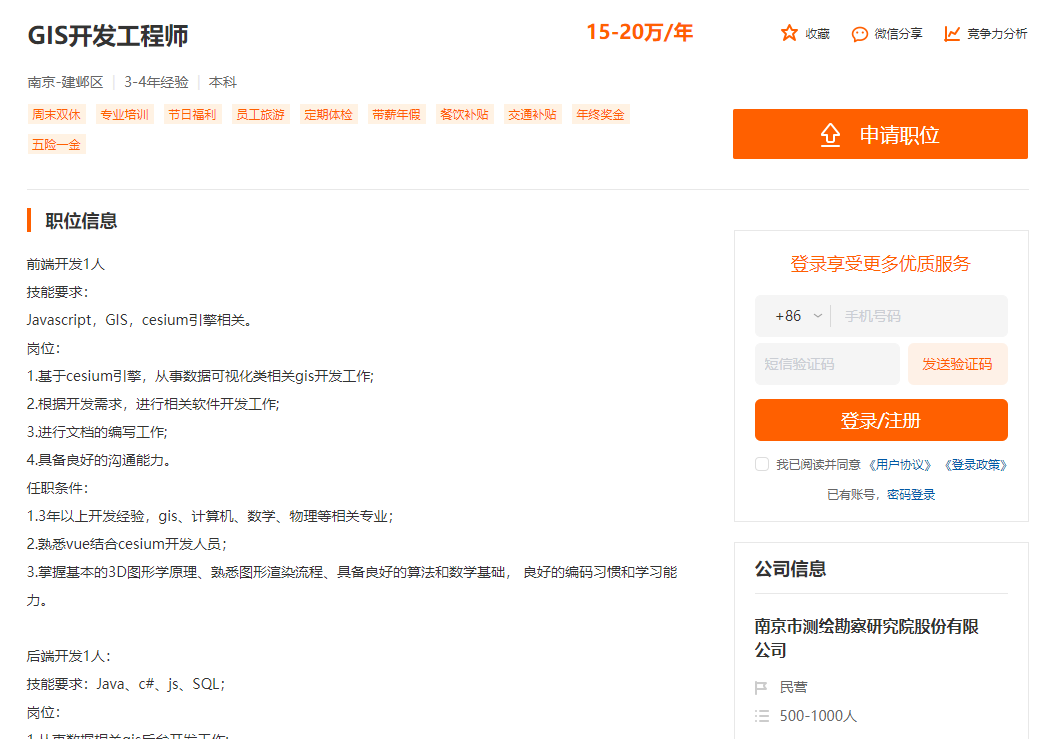
国地规划
这是一家专门为各级政府、企业及相关科研事业单位等提供空间大数据综合技术服务的高新技术企业,具备“智慧+”集成统筹与多场景应用能力和“规划+”空间治理全生态链服务能力,拥有CMMI5、ITSS三级、信息安全管理体系等认证和城乡规划、土地规划、农林行业生态工程设计、工程咨询资信等资质。
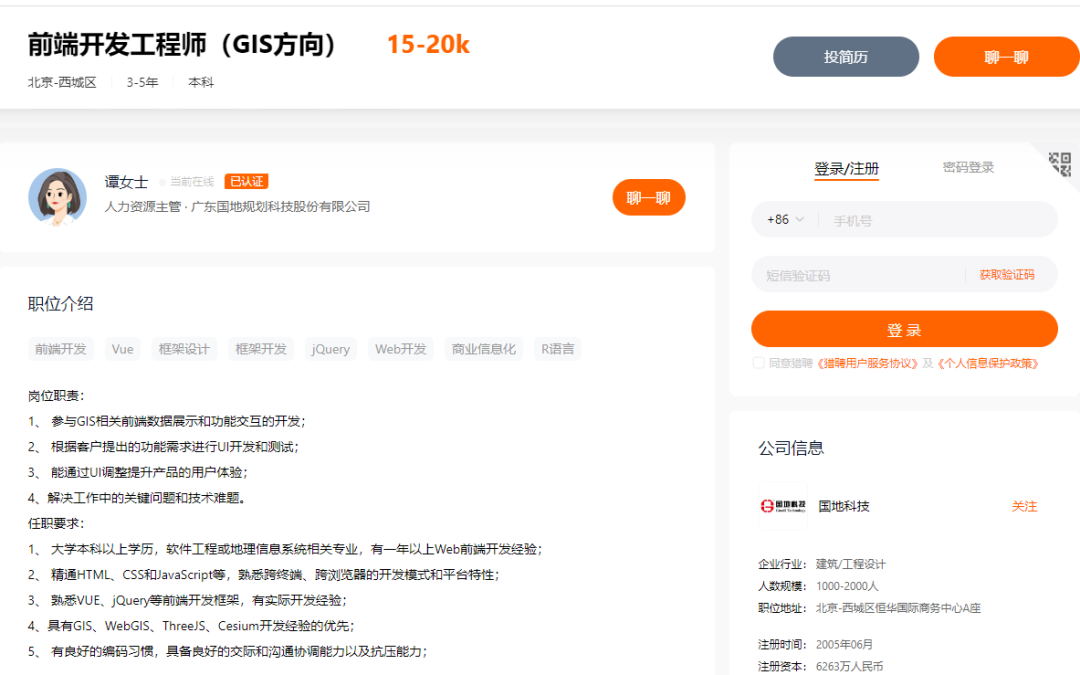
互联网
一些互联网企业例如:百度在线、万维空间、普适导航、立得空间、中兵智能创新研究院、阿里集团、北京潜度等企业赫然在列。
百度在线
从岗位要求就能看出,他们招聘GIS开发的主要目的是研究高精地图和人机共驾地图可视化平台。
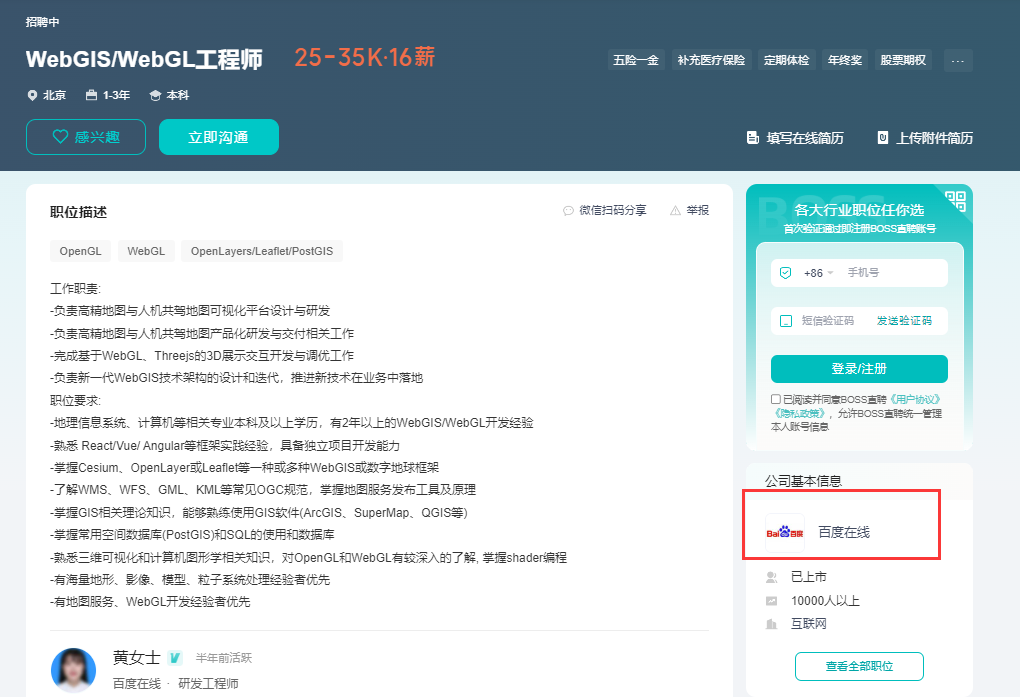
阿里集团
阿里之前我们也讨论过,旗下的高德地图,L7等都是和地图有关的。
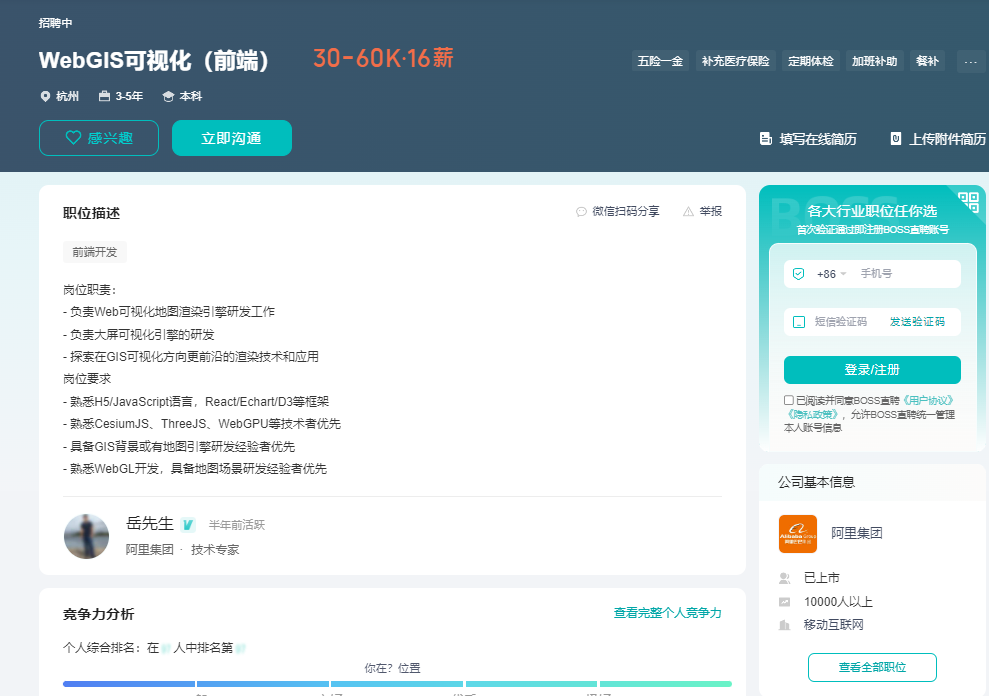
立得空间
立得空间是由武汉大学、两院院士李德仁、国内知名科技投资公司等共同组建的高科技企业。一直引领移动测量、惯性导航、高精度地图、时空大数据等技术的发展潮流,更通过应用与商业模式创新,在智慧城市大数据中心,城市管理、公安、测绘、交通、旅游等行业应用,车联网、智能驾驶&无人驾驶,新零售&新物流之商业智能(BI)、物联网高精度位置服务等领域开创了崭新的应用模式。
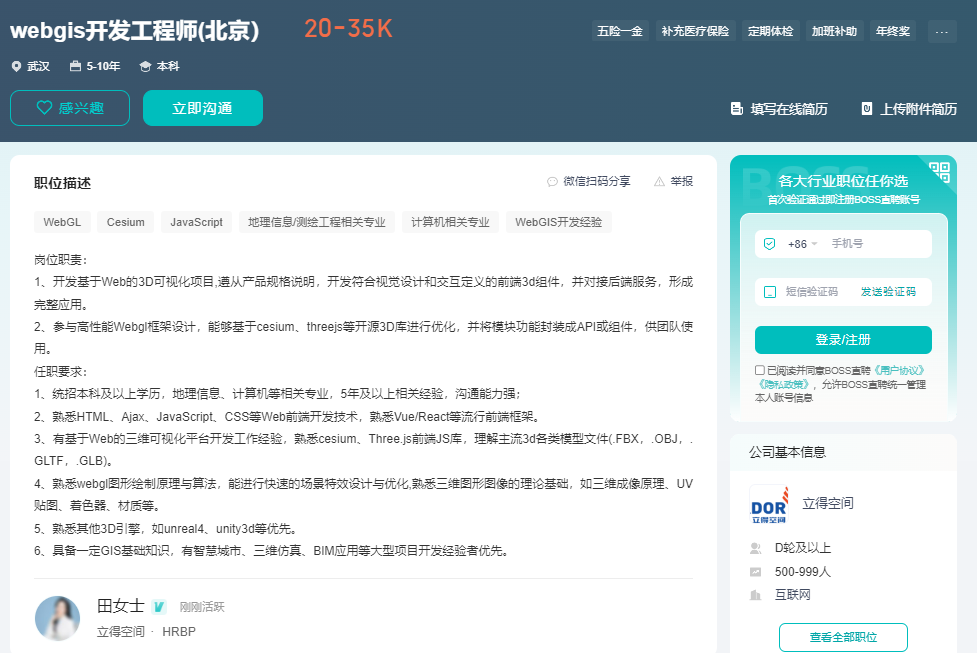
普适导航科技
上海普适导航科技股份有限公司成立于2008年,是一家专业从事卫星AI技术研究与应用的高新技术企业,公司致力于数字化转型背景下行业时空智能感知、时空大数据构建和时空智能认知,推动水务、环保、海洋、海事、农业、应急等行业数字化转型。
又是数字化转型!
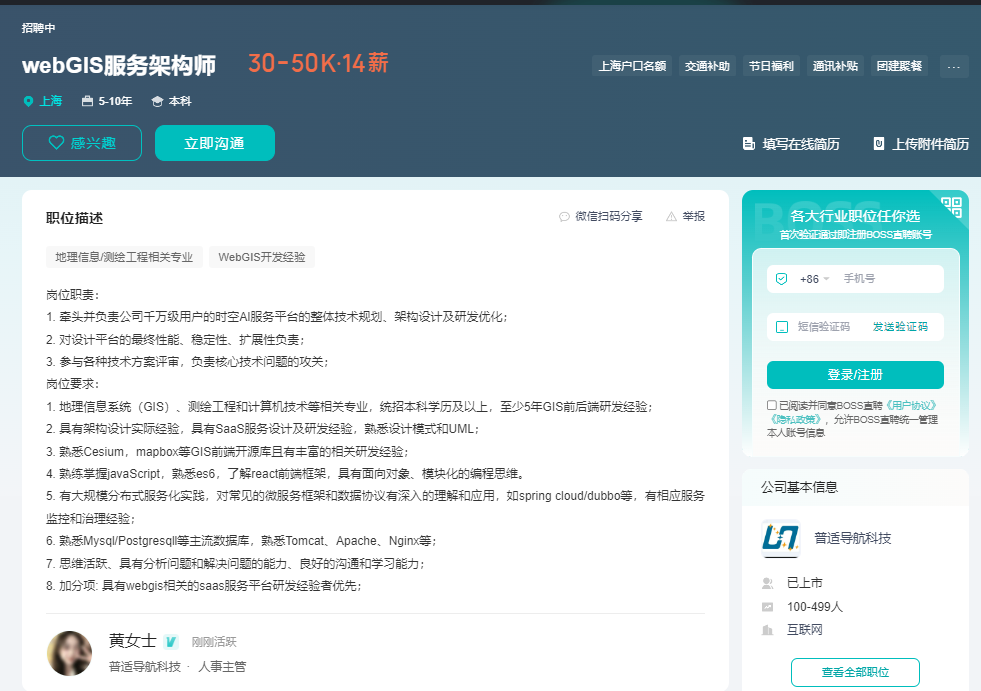
总体上看,IT互联网企业以及GIS头部企业,能开出的薪资还是蛮高的,尤其是大厂。
其他还有很多行业都在招聘WebGIS开发,包括:船舶、通信、电力、新能源、大数据、物流、航天航空等行业。
大都离不开数字化转型和发展,由于篇幅原因,这里就不一一赘述。
新中地GIS开发特训营最新开班日期
| 类别 | 开班时间 | 报名状态 |
| 2402期 | 2024/3/4-2024/7/31 | 已开班,7天免费试听 |
| 2403期 | 2024/4/15-2024/9/10 | 火热预定中 |
| 2404期 | 2024/6/3-2024/11/1 | 可预报名 |
| 2405期 | 2024/7/15-2024/12/12 | 可预报名 |
2024GIS开发特训营免费体验券![]() https://www.wjx.cn/vm/t8TJZp5.aspx#
https://www.wjx.cn/vm/t8TJZp5.aspx#