建设网站女装名字大全微信商城网站
今天我要和大家分享的是关于d3dcompiler_43.dll丢失的解决方法。我相信很多网友在使用电脑时都遇到过这个问题,那么接下来就让我们一起来探讨一下如何解决这个问题吧!
首先,让我们来了解一下d3dcompiler_43.dll文件的总体介绍。d3dcompiler_43.dll是一个动态链接库文件,它是DirectX的一个组件,主要负责图形渲染和多媒体处理。当我们的电脑中这个文件丢失时,可能会导致一些游戏或者软件无法正常运行。

那么,面对这个问题,我们应该如何解决呢?下面我将为大家介绍6种不同的解决方法:
方法一:重新启动电脑计算机。有时候电脑出现一些文件错误故障,是由于电脑突然过热导致我们需要重启一下电脑然后再检查是否解决了问题。
方法二:下载一个dll修复工具,使用dll修复工具进行修复操作非常简单(亲测可以修复),它可以自动检测电脑缺失或者损坏的dll文件,如果d3dcompiler_43.dll缺失,dll修复工具检测到以后,便会自动安装d3dcompiler_43.dll文件。
使用DLL修复工具进行一键修复。您可以在浏览器顶部网页搜索:dll修复文件.site【按回车键进入站点】,下载一个dll修复程序工具,这个程序是可以修复百分之百dll丢失的问题。
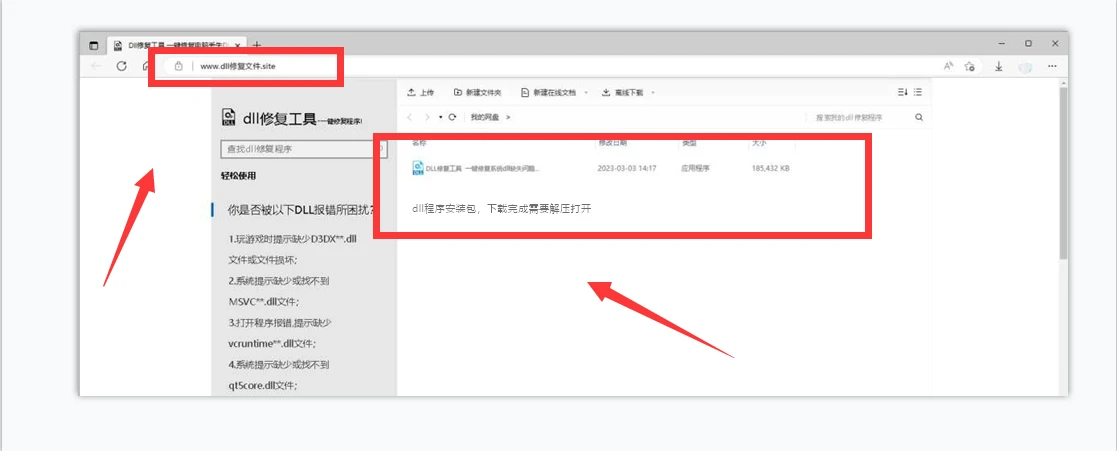
DLL 修复工具可以帮助你恢复 dll 文件。工具会自动检测你的系统中的 DLL 文件,并尝试修复任何损坏或丢失的文件。,下载到电脑上的文件一般是压缩包的形式,需要先把文件解压,然后安装后点击修复【立即修复】然后运行它来修复 dll 文件。
提示修复完成,再测试打开一下出现dll丢失的软件,即可正常打开运行(如果还是提示重启一下电脑即可)

方法三:重新安装DirectX。我们可以从官方网站下载最新版本的DirectX安装包,然后进行安装。安装完成后,重新启动电脑,检查是否解决了问题。
方法四:更新显卡驱动。我们可以访问显卡制造商的官方网站,下载最新的驱动程序并进行安装。这样可以确保我们的显卡驱动是最新的,避免因为驱动问题导致文件丢失。

方法五:使用系统还原功能。如果问题出现之前,我们创建过系统还原点,那么我们可以通过系统还原来恢复到问题出现之前的状态,从而解决文件丢失的问题。
方法六:重装系统。如果以上方法都无法解决问题,那么最后的选择就是重装系统。虽然这样会导致我们的个人数据丢失,但是可以彻底解决文件丢失的问题。

接下来,我们来分析一下d3dcompiler_43.dll丢失的原因。一般来说,这个文件丢失的原因有以下几种:1. 系统感染病毒或者恶意软件;2. 系统文件损坏或者误删;3. DirectX安装不完整或者版本不兼容;4. 软件之间的冲突;5. 硬件故障等。当然,具体原因还需要我们根据实际情况来判断。
总之,面对d3dcompiler_43.dll丢失的问题。希望我的分享对大家有所帮助,谢谢大家!