福建建设银行网站网站设计名称
PART 01 前 言
随着网络技术的发展,从粗犷型到精细化运营型,再到现在的数字化运营,数据变得越来越细分和重要,不仅可以进行策略调整,还可以实现自动化的精细化运营。而数据价值的起点就是埋点,只有合理地埋点,规范地上报,数据才会产生价值。
PART 02 数据埋点的必要性
合理、有效的数据埋点以及客观的数据闭环反馈,可以帮助企业从不同维度分析用户,构建用户数据体系,为企业提供决策、营销、和精细化运营支撑。
决策:实时掌握核心指标,定时定期报表推送,支撑业务决策,应对市场变化。
营销:找寻优质渠道资源,调整营销策略,提升线索转化率,从而提高市场整体ROI。
运营:精准定位不同用户群,个性化营销引导,让用户运营有的放矢。
产品:追踪用户行为,分析核心步骤转化,快速验证改版方案,提升新老用户转化。
PART 03 什么是数据埋点
指针对特定场景的用户行为或事件进行捕获、处理和上报的过程。
在整个过程捕获的所需信息,用以跟踪用户的使用情况,最后分析这一系列数据作为领导决策、产品迭代、营销运营的有效支撑。
埋点方式主要分为三类:代码埋点、可视化埋点和全埋点。
代码埋点:指开发工程师将埋点结合到代码逻辑中,在APP或者界面初始化的时候,初始化第三方数据分析服务商的SDK,然后在某个事件发生时就调用SDK里面相应的数据发送接口发送数据,此种方式是从代码逻辑上捕获用户行为并且上报数据。
可视化埋点:是一种不需要额外去写代码的埋点方式,而是由业务/运营人员通过访问分析平台的埋点圈选功能,“圈”出需要对用户行为进行捕捉的控件,并给出相应的事件命名。当圈选完毕后,这些配置会从平台侧同步到所有用户终端,当终端有触发已圈选的事件,SDK就会按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点:指预先收集用户的所有行为数据,在集成采集SDK后,SDK便直接开始捕捉用户在终端应用上的所有行为数据并全部上报,在后续使用数据的时候就可以从数据库中直接查询。

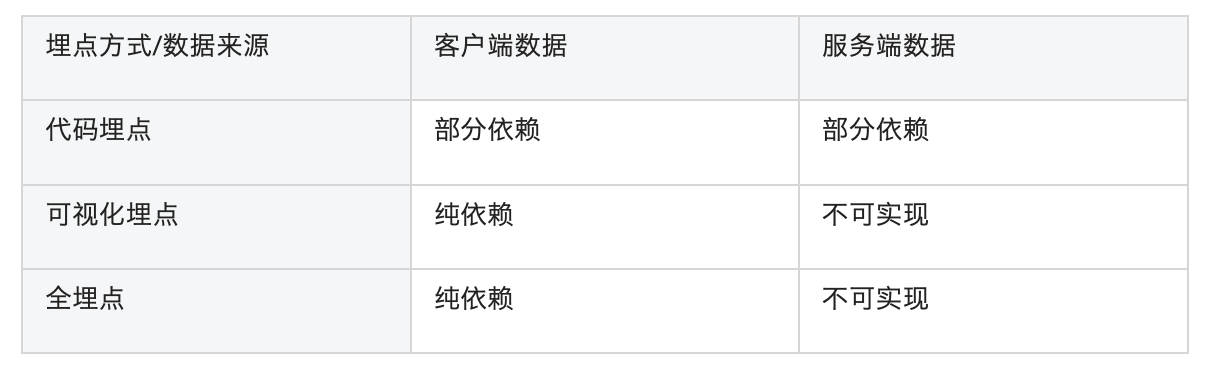
埋点数据来源:
客户端数据:页面/弹窗曝光、点击数据。
服务端数据:安装数据,支付数据,业务数据等。
埋点方式和数据来源的关系如下表所示:
PART 04 用户行为数据埋点设计&方法论
用户行为数据埋点设计&方法论
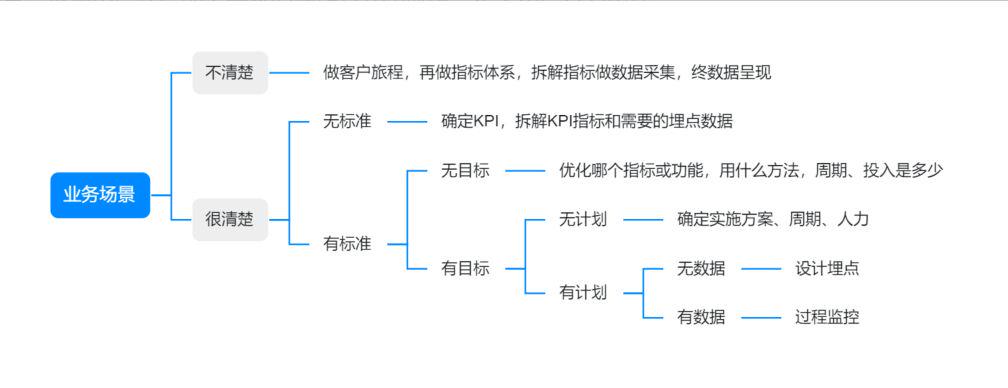
埋点设计流程:

1、事件埋点设计之前,需要先了解业务场景,梳理和确认业务流程、用户操作路径和各种不同的细分场景。根据用户在产品上具象的操作方式和流程,定义用户行为路径。
场景拆解策略:清楚业务,制定标准,规划目标,确定策略,创建计划
清楚业务:设计埋点的前提需要清晰了解客户端的业务场景,不仅需要熟悉用户的操作,不同用户路径下有什么页面,运营位、按钮、弹窗,而且还需要了解产品所有功能,部分或者极少用户使用的业务也要做到心中有数。
制定标准:清楚业务后,需要针对每个业务模块/分类制定目标,根据目标拆解为一个个确定的数据指标,然后把指标细分成一个或者多个埋点事件,即多个埋点事件都能直接影响指标。
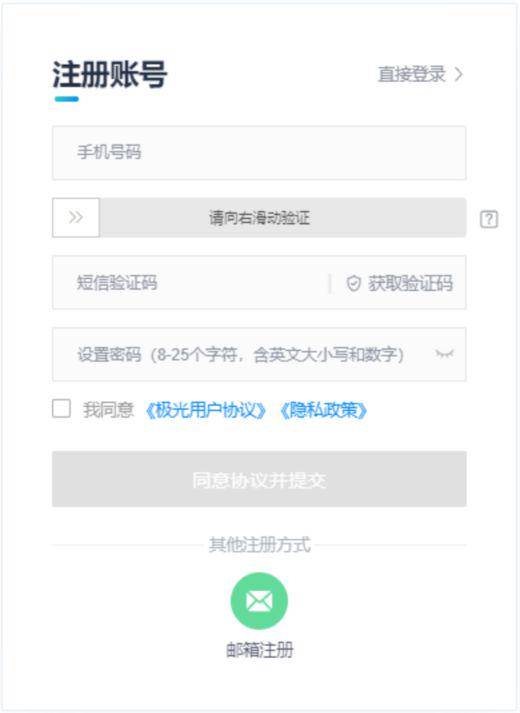
举例:如下图所示,如果需姚需要提升新用户的注册率,需要拆解的埋点事件有:注册页面曝光、注册页_手机号是否输入、注册页_是否右滑验证、注册页_点击获取验证码、注册页_是否发送验证码、注册页_是否输入验证码、注册页_是否输入密码、注册页_是否勾选协议、注册页_提交按钮点击
2、在充分了解终端的业务情况和场景拆解后,输出要提升的指标和特定事件,指标和事件的拆解,可能是一对一或者一对多的关系,即一个指标可能由一个或者多个埋点事件组成;其次,需要充分考虑到这些事件会用于哪些指标的分析,需要上报哪些字段或属性,具体分析时的核心应用的是哪些。指标体系优先级如下图所示:

3、设计埋点事件,针对拆解的业务场景,梳理指标和事件,抽取指标与事件之间的关联,再结合相应的属性,确定要上报的事件、属性以及上报时机等5要素设计埋点事件。
4、埋点实施,开发同事根据埋点设计实施埋点并上报,需要考虑事件埋点方式和事件上报触发逻辑;埋点方式分为:全埋点、代码埋点、可视化埋点三种。
事件上报的触发逻辑可做如下分类:
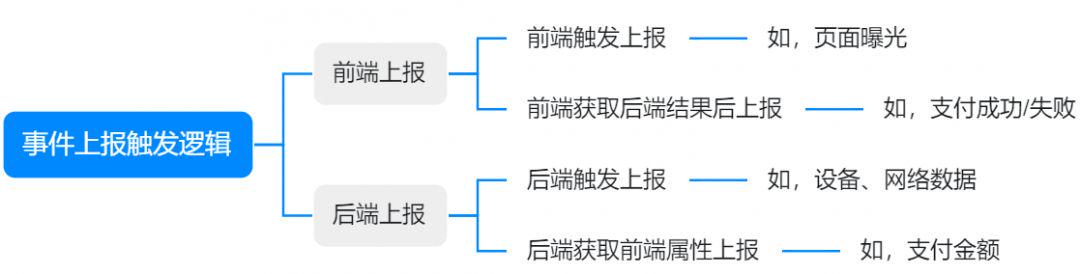
根据业务场景做最优的触发上报逻辑。
5、根据上报的埋点数据,验证埋点的准确性,从流量埋点事件(如点击、曝光)上报到业务、财务指标逐渐递升,汇聚成多流量、内容、业务、财务的数据指标,构建用户全方位的数据指标体系;埋点测试验收应该保证埋点数据正确性、顺序性、完整性:
正确性:最基础的是确认是否有数据上报,其次,检查数据内容与字段是否与埋点设计文档一致;
顺序性:数据上报正确,还需要检查上报的顺序是否正确;
完整性:测试时,针对多场景要全部测试,如申请验证码的各个场景都应该上报。
6、数据清洗、存储、聚合转换、分析;埋点上线,并不意味就结束,重点要观察对应的指标是否准确上报,对业务是否指导作用,与优化前的版本相比较是否有所改善。很多时候可能不能一步到位就把问题解决掉,需要迭代优化,不断通过数据跟踪来修正优化策略,达到最终设计目标。
PART 05 如何做好埋点设计
1、基于业务场景,埋点5要素:
WHO:即参与这个事件的用户是谁,如:用户ID,设备ID
WHEN:即这个事件发生的时间,如:时间戳
WHAT: 描述了一个事件具体是什么,如:事件名称/页面标题名
HOW:即用户从事这个事件的方式,如:上报时机,页面属性
WHERE:IP、国家、省、市区等用户属性,如:IP地址
每个事件上报都必须包含上述5个要素。
举例:某APP需要上报【商城_XX运营位】被点击的埋点事件,如下图所示:
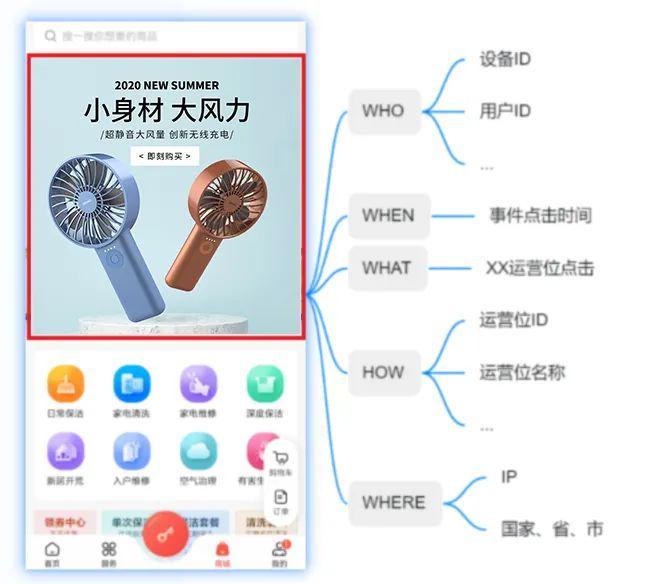
点击事件需要上报的5要素:
①是哪个用户ID/设备ID:用户ID:001,苹果终端
②什么时候点做的:2022年12月16日10时46分05秒或时间戳
③是什么事件:XX运营位点击
④怎么点击的:运营位ID:0A_001,运营位名称:商城_首页轮播
⑤在哪里点击的:IP地址:101.XX.XX.XX
上述5要素合成一条数据上报到数据系统。
2、要上报的埋点,归纳起来总共分为以下三类:
①曝光事件:页面曝光、弹窗曝光、按钮/文案曝光、运营位/banner位曝光等;
举例:某iOS应用,【推荐】栏目,A运营位的曝光数据;
②点击事件:运营位/banner位点击、按钮/文案点击;
举例:某iOS应用,【推荐】栏目,A运营位的点击数据, 并上报运营位的内容id和内容;
③特殊事件/属性:服务端上报;特殊场景,多个不确定选择项上报。
举例:某iOS应用,【我的】栏目-问题反馈页面-问题勾选,具体勾选项数据;
属性值通过枚举上报。
上述举例的埋点设计:

3、埋点的整体原则&规范:
①事件名称尽可能简单、清晰,降低使用门槛;
②同个终端/平台,如多个场景都用到一样的事件,通常建议用属性作为区分;
举例:弹窗,是否确定/取消。该弹窗在三个页面都出现。
埋点设计:

如上例子所示,一个弹窗按钮点击事件,用页面类型(自定义属性)属性作为区分,可用一个埋点上报3个页面的弹窗按钮点击数据。
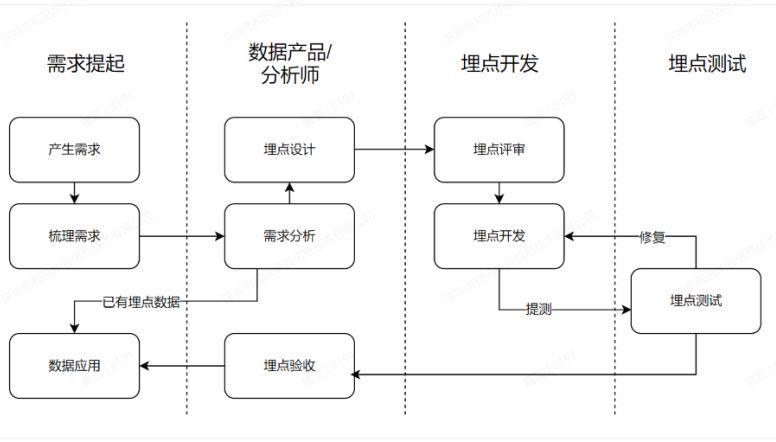
4、数据埋点流程:
PART 06 总结
基于埋点的重要性,在于埋点采集本身,应该被当成独立的研发业务来做,而不只是一个产品研发过程中的附属品,属于可有可无、顺带做一下的任务项。埋点是为了更好地使用数据,而使用数据是为了更好的服务于业务。合理的数据埋点和分析可以帮助企业从不同维度分析用户,构建用户数据体系,为企业提供业务决策、营销转化、产品迭代和精细化运营支撑。
关于极光
极光(Aurora Mobile,纳斯达克股票代码:JG)成立于2011年,是中国领先的客户互动和营销科技服务商。成立之初,极光专注于为企业提供稳定高效的消息推送服务,凭借先发优势,已经成长为市场份额遥遥领先的移动消息推送服务商。随着企业对客户触达和营销增长需求的不断加强,极光前瞻性地推出了消息云和营销云等解决方案,帮助企业实现多渠道的客户触达和互动需求,以及人工智能和大数据驱动的营销科技应用,助力企业数字化转型。