广州网站制网站备案后可以修改吗
官网http://www.msa-alliance.cn/col.jsp?id=120
首先到官网注册账号,申请下载相关sdk和授权证书
2.把 oaid_sdk_x.x.x.aar 拷贝到项目的 libs 目录,并设置依赖,其中x.x.x 代表版本号
3.supplierconfig.json 拷贝到项目 assets 目录下,并修改里边对应内容,特别是需要设置 appid 的部分。需要设置 appid 的部分需要去对应厂商的应用商店里注册自己的 app。需要注意的是,其中 label 部分内容无需修改,不用增加应用商店。
4.将证书文件(应用包名.cert.pem)拷贝到项目 assets 目录下
证书需要填写 example_batch.csv 后发送到 msa@caict.ac.cn 申请,注意每个包名对应一个签名,申请时需要将所需申请的全部包名填写到表格中。
证书有效期一年,为避免证书过期影响 APP 获取 ID,建议证书信息可以从后台服务器获取,或者当调用 oaid SDK 接口提示证书无效时,调用后台接口及时更新证书信息,并且快到期时及时提前重新申请证书。
5.设置依赖
implementation files(‘libs/oaid_sdk_x.x.x.aar’)6.设置 gradle 编译选项,开发者可以根据自己对平台的选择进行合理配置
ndk {abiFilters 'armeabi-v7a', 'x86', 'arm64-v8a', 'x86_64'
}考虑到 sdk 兼容性,sdk 包默认集成了常用 abi 的 so,包括 armeabi-v7a, arm64-v8a, x84, x84_64 共四种。如果需要减小 SDK 体积,可以使用压缩工具打开 aar 文件,手动删除多余的架构。
7.设置混淆
# sdk
-keep class com.bun.miitmdid.** { *; }
-keep interface com.bun.supplier.** { *; }
# asus
-keep class com.asus.msa.SupplementaryDID.** { *; }
-keep class com.asus.msa.sdid.** { *; }
# freeme
-keep class com.android.creator.** { *; }
-keep class com.android.msasdk.** { *; }
# huawei
-keep class com.huawei.hms.ads.** { *; }
-keep interface com.huawei.hms.ads.** {*; }
# lenovo
-keep class com.zui.deviceidservice.** { *; }
-keep class com.zui.opendeviceidlibrary.** { *; }
# meizu
-keep class com.meizu.flyme.openidsdk.** { *; }
# nubia
-keep class com.bun.miitmdid.provider.nubia.NubiaIdentityImpl
{ *; }
# oppo
-keep class com.heytap.openid.** { *; }
# samsung
-keep class com.samsung.android.deviceidservice.** { *; }
# vivo
-keep class com.vivo.identifier.** { *; }
# xiaomi
-keep class com.bun.miitmdid.provider.xiaomi.IdentifierManager
{ *; }
# zte
-keep class com.bun.lib.** { *; }
# coolpad
-keep class com.coolpad.deviceidsupport.** { *; }8.代码调用
a、在 application 类中初始化 SDK 包
System.loadLibrary("msaoaidsec");b、加载证书内容
MdidSdkHelper.InitCert (Context context, String certContent);c、调用方法获取补充标识符,示例代码详见附件 DemoHelper.java
//获取部分 id 信息
int code = MdidSdkHelper.InitSdk(cxt, isSDKLogOn, isGetOAID,
isGetVAID, isGetAAID, IIdentifierListener);
//获取全部 id 信息
int code = MdidSdkHelper.InitSdk(cxt, isSDKLogOn,
IIdentifierListener);以上就是官网给出的一个sdk的集成与调用,比较简单
这次主要分享的是部分机型在“支持的机型且被限制获取OAID”的前提下的操作方法:
①小米:手机系统设置--隐私保护--保护隐私(顶部)--防追踪--虚拟身份ID(最底部)--虚拟身份ID授权管理--“应用名”,这个页面的开关是否打开,打开后重启APP。
②华为:手机系统设置--隐私--广告与隐私--限制广告追踪,这个页面的开关是否关闭,关闭后重启APP。
③VIVO:手机系统设置-安全与隐私-更多安全设置-广告与隐私(或根据兴趣内容推荐)-个性化广告推荐,这个页面的开关是否打开,打开后重启APP。
④OPPO/真我:手机系统设置-隐私-设备标识与广告-限制广告跟踪,这个页面的开关是否关闭,关闭后重启APP。(因系统缓存,以上操作完成后仍可能存在相关问题,请关闭开关2小时后重试)
⑤魅族:手机系统设置-隐私和权限-应用跟踪控制-允许“应用名”应用跟踪,打开后重启APP。
⑥荣耀:手机系统设置-应用-应用管理-HMS Core-右上角设置齿轮图标-广告-限制广告跟踪,这个页面的开关是否关闭,关闭后重启APP。
⑦一加:手机系统设置-隐私-广告-“选择停用广告个性化功能“开关关闭,关闭后重启APP。(若以上操作完成后仍可能存在相关问题,请参考OPPO手机的设置方式)
⑧联想:手机系统设置-搜索“安全和隐私”--限制广告跟踪,这个页面的开关是否关闭,关闭后重启APP。
以上方式都是真机实测过的
还有一种开源的替代方式CNAdID,我还没试过,有兴趣的同学可以尝试一下
其中 OAID 是由手机厂联盟提供的广告跟踪标示,CNAdID 是数字联盟“可信 ID ”的免费版
https://gitee.com/shuzilmopensource/Get_Oaid_CNAdid
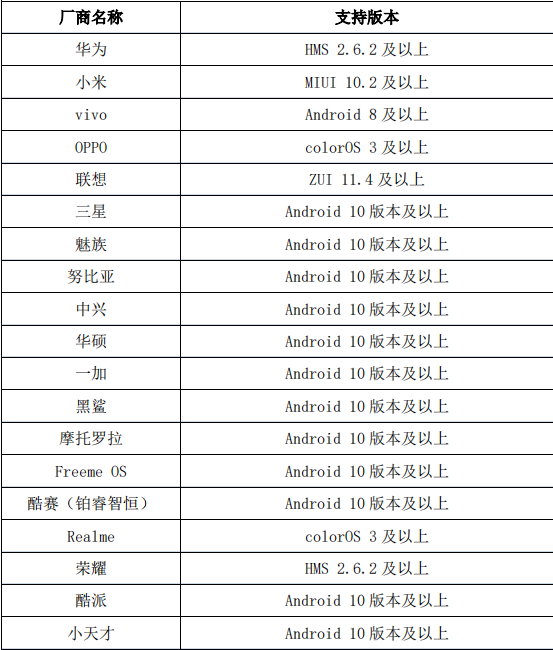
OAID 目前提供以下设备的获取方式:
CNAdID 目前提供安卓全平台获取方式。