网站制作软件培训wordpress中文版安装教程
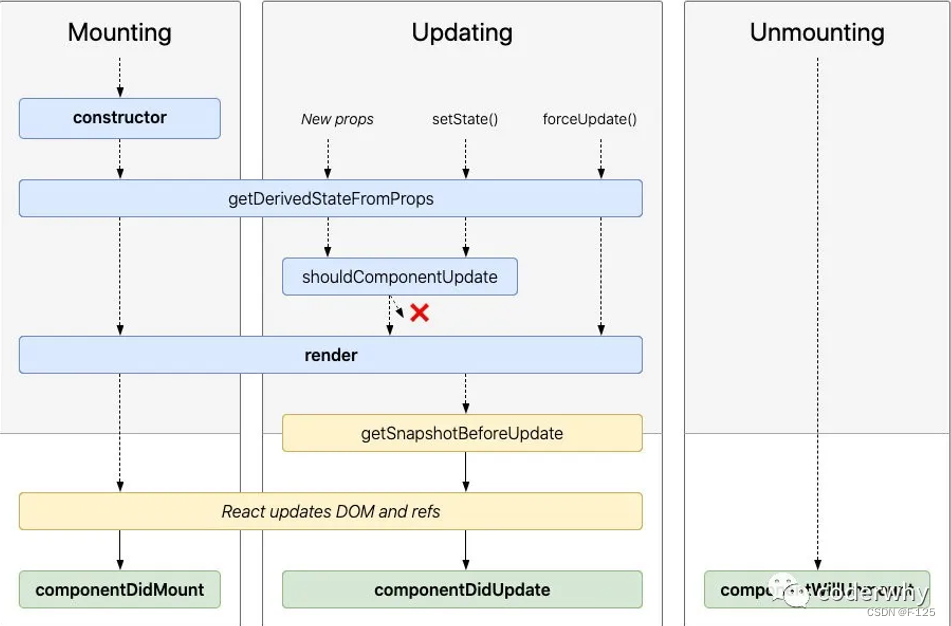
在React的类组件中,从组件创建到组件被挂载到页面中,这个过程react存在一系列的生命周期函数,最主要的生命周期函数是componentDidMount、componentDidUpdate、componentWillUnmount
生命周期图例如下
1. componentDidMount组件挂载
如果你定义了 componentDidMount 方法,React 将会在组件被添加到屏幕上 (挂载) 后调用它。这里是设置数据获取、订阅监听事件或操作 DOM 节点的常见位置。
- 参数:
componentDidMount不需要任何参数; - 返回值:
componentDidMount不应该返回任何值; - 场景:多用于组件中进行网络请求,DOM操作等;
componentDidMount() {console.log("component did mount");}2. componentDidUpdate组件更新
如果你定义了 componentDidUpdate 方法,那么 React 会在你的组件更新了 props 或 state 重新渲染后立即调用它。这个方法不会在首次渲染时调用。
- 参数:
-
prevProps:更新之前的 props。prevProps将会与 this.props 进行比较来确定发生了什么改变; -
prevState:更新之前的 state。prevState将会与 this.state 进行比较来确定发生了什么改变; -
snapshot: 如果你实现了 getSnapshotBeforeUpdate 方法,那么
snapshot将包含从该方法返回的值。否则它将是undefined;
-
-
返回值:
componentDidMount不应该返回任何值; -
注意:如果在组件中定义了shouldComponentUpdate 并且返回值是
false的话,componentDidUpdate将不会被调用。如果在componentDidUpdate中直接调用 setState方法,会造成触发一次发生在浏览器更新屏幕内容之前的额外渲染,在这种情况下,即使 render 会被调用两次,用户也看不到中间状态。这种模式通常会导致性能问题。
componentDidUpdate(prevProps, prevState, snapshot) {console.log("component did update");}3. componentWillUnmount组件卸载
如果你定义了 componentWillUnmount 方法,React 会在你的组件被移除屏幕(卸载)之前调用它。此方法常常用于取消数据获取或移除监听事件。
- 参数:
componentDidMount不需要任何参数; - 返回值:
componentDidMount不应该返回任何值; - 注意:
componentWillUnmount内部的逻辑应该完全“对应”到 componentDidMount 内部的逻辑,例如,如果你在componentDidMount中设置了一个监听事件,那么componentWillUnmount中就应该清除掉这个监听事件,例如定时器任务等。
componentWillUnmount() {console.log("component willUnmount");}4. getSnapshotBeforeUpdate组件快照
getSnapshotBeforeUpdate,React 会在 React 更新 DOM 之前时直接调用它。它使你的组件能够在 DOM 发生更改之前捕获一些信息(例如滚动的位置)。此生命周期方法返回的任何值都将作为参数传递给 componentDidUpdate。
- 参数:
-
prevProps:更新之前的 Props。prevProps将会与 this.props 进行比较来确定发生了什么改变。 -
prevState:更新之前的 State。prevState将会与 this.state 进行比较来确定发生了什么改变。
-
-
返回值:返回你想要的任何类型的快照值,或者是
null。你返回的值将作为第三个参数传递给 componentDidUpdate。
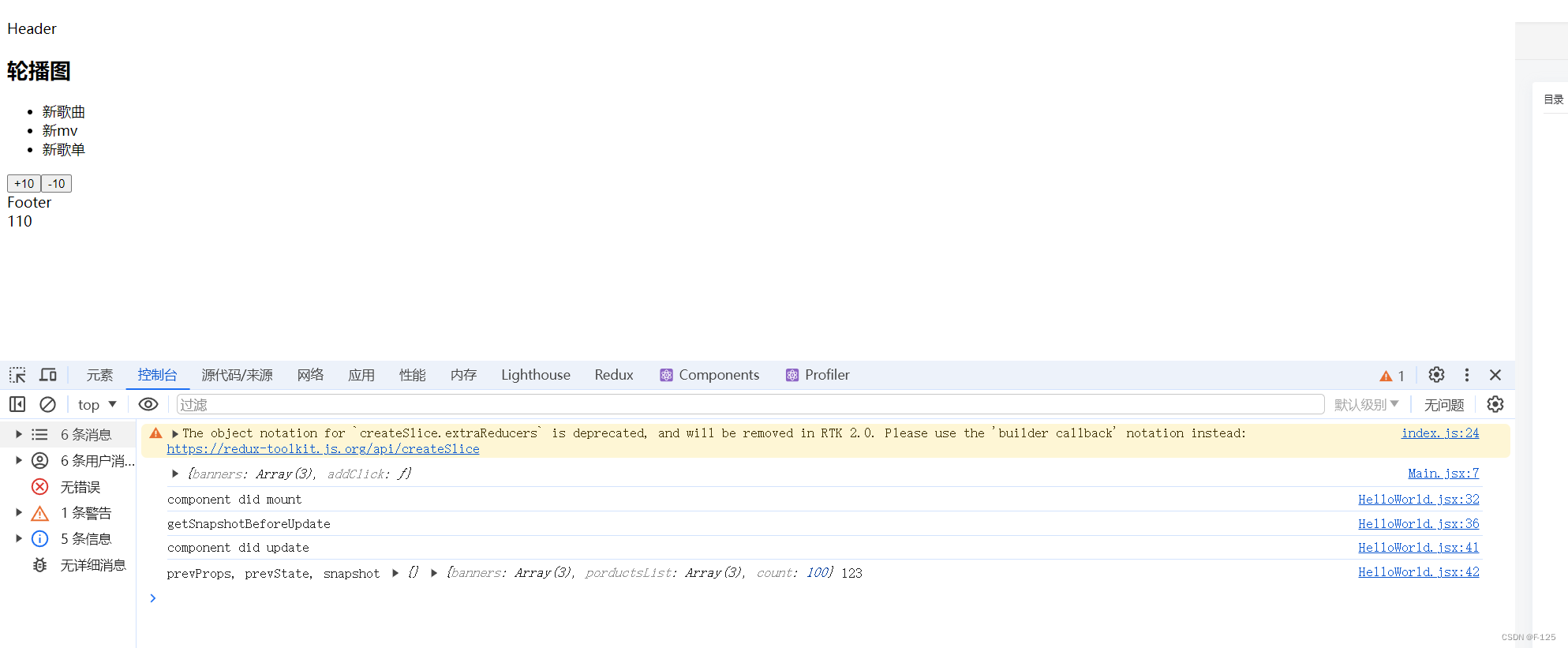
getSnapshotBeforeUpdate(prevProps, prevState) {console.log("getSnapshotBeforeUpdate");return "123"}运行结果:
用例组件App:
class HelloWorld extends React.Component {constructor() {super()this.state = {banners: ['新歌曲','新mv', '新歌单'],porductsList: ['商品','热门', '流行'],count: 100,}}changeCount(count) {this.setState({count: this.state.count + count})}render() {const { banners, porductsList, count} = this.statereturn (<div><Header /><Main banners={banners} addClick={(count) => this.changeCount(count)} /><Footer porductsList={porductsList}/><div>{count}</div></div>)}componentDidMount() {console.log("component did mount");}getSnapshotBeforeUpdate(prevProps, prevState) {console.log("getSnapshotBeforeUpdate");return "123"}componentDidUpdate(prevProps, prevState, snapshot) {console.log("component did update");console.log("prevProps, prevState, snapshot", prevProps, prevState, snapshot); // snapshot 就是 getSnapshotBeforeUpdate 返回的值 123}componentWillUnmount() {console.log("component willUnmount");}
}