网站建设技术支持祥云平台茶叶电子商务网站开发技术支持
Chrome浏览器开发者工具默认的字体太小,想要修改但没有相关设置。
外观——字体可以自定义字体,但大小不可以调整。
github上有人给出了方法
整理为中文教程:
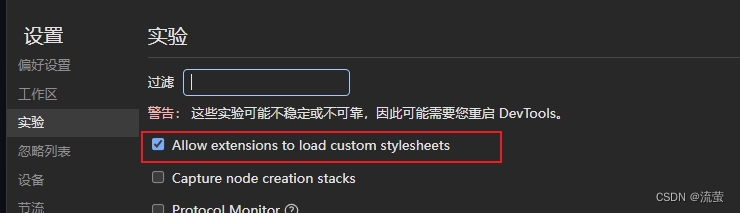
1.打开浏览器开发者工具,点开设置——实验,勾上红框设置
2.在电脑上建立一个文件夹,然后建一个devtools.html文件,内容:
<html>
<head></head>
<body><script src="devtools.js"></script></body>
</html>3.再建立一个devtools.js文件,内容:
var x = new XMLHttpRequest();
x.open('GET', 'style.css');
x.onload = function() {chrome.devtools.panels.applyStyleSheet(x.responseText);
};
x.send();4.再建立一个style.css文件,内容:
/* 元素和console里的字体 */
:host-context(.platform-windows) .monospace,
:host-context(.platform-windows) .source-code,
.platform-windows .monospace,
.platform-windows .source-code {font-size: 14px !important;font-family: GeistMono NFM, monospace !important;
}/* 没改成功 */
:host-context(.platform-windows) .cm-editor,
.platform-windows .cm-editor
{font-size: 14px !important;font-family: SauceCodePro NFM, monospace !important;
}/* 网络——预览里面的字体 */
:host-context(.platform-windows) .network-item-view .cm-content .cm-line,
.platform-windows .network-item-view .cm-content .cm-line
{font-size: 14px !important;font-family: SauceCodePro NFM, monospace !important;
}/* 网络——预览里面的行高 */
:host-context(.platform-windows) span.name-and-value,
.platform-windows span.name-and-value
{line-height: 17px;
}/* 网络——请求的地址 */
:host-context(.platform-windows) .network-log-grid .name-column,
.platform-windows .network-log-grid .name-column
{font-size: 14px !important;/*font-family: SauceCodePro NFM, monospace !important;*/font-family: GeistMono NFM, monospace !important;
}.monospace,
.source-code {font-size: 14px !important;font-family: SauceCodePro NFM, monospace !important;
}::shadow .monospace,
::shadow .source-code {font-size: 14px !important;font-family: SauceCodePro NFM, monospace !important;
}5.再建立一个manifest.json文件,内容:
{"name": "Custom Chrome Devtools Theme","version": "1.0.0","description": "A customized theme for Chrome Devtools.","devtools_page": "devtools.html","manifest_version": 2
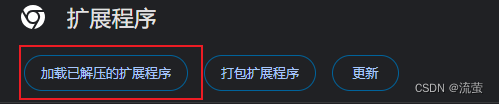
}6.然后打开Chrome的管理扩展程序页面,勾选右上角的开发者模式,然后点击加载已解压的扩展程序,选择刚刚建立的文件夹就可以了。
打开浏览器开发者工具后,可以再按 Ctrl+Shift+i 打开新的开发者工具,用于查看开发者工具各个元素的结构,用于构建你想要修改的地方的selector。