有没有做网站的教程网页设计一单多少钱
循环语句
循环含义
将某代码段重复运行多次,通常有进入循环的条件和退出循环的条件
for循环语句
一般知道循环次数使用for循环
第一类
格式1:
for名称 in 取值次数;do;done;
格式2:
for 名称
in {取值列表}
do
done# 打印20次
for i in {1..20}
do
echo $i
done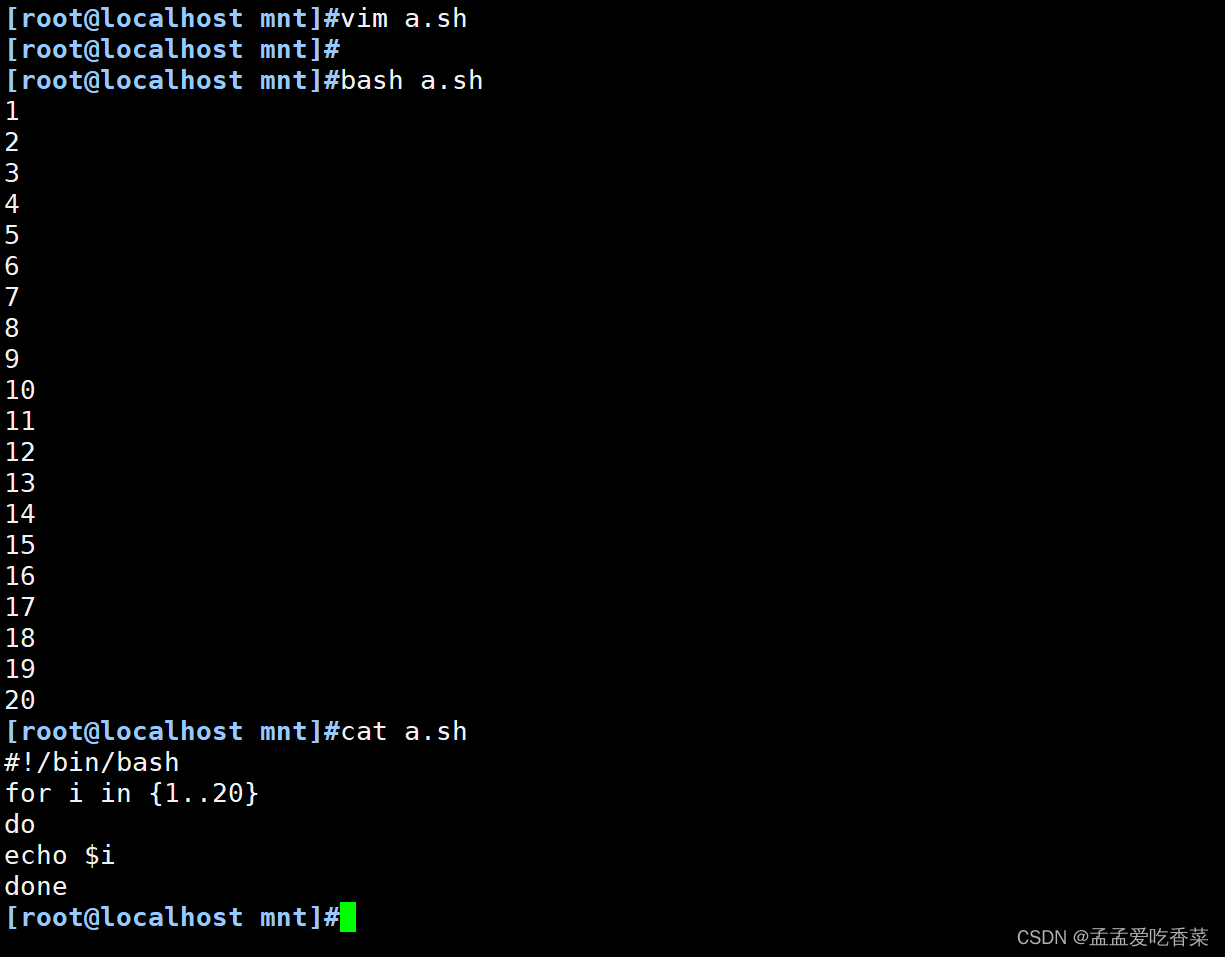
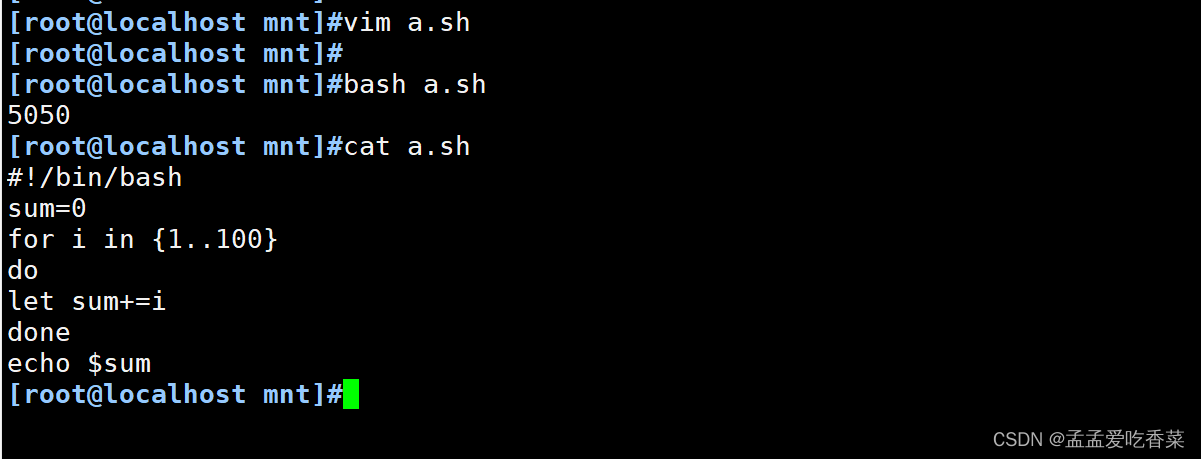
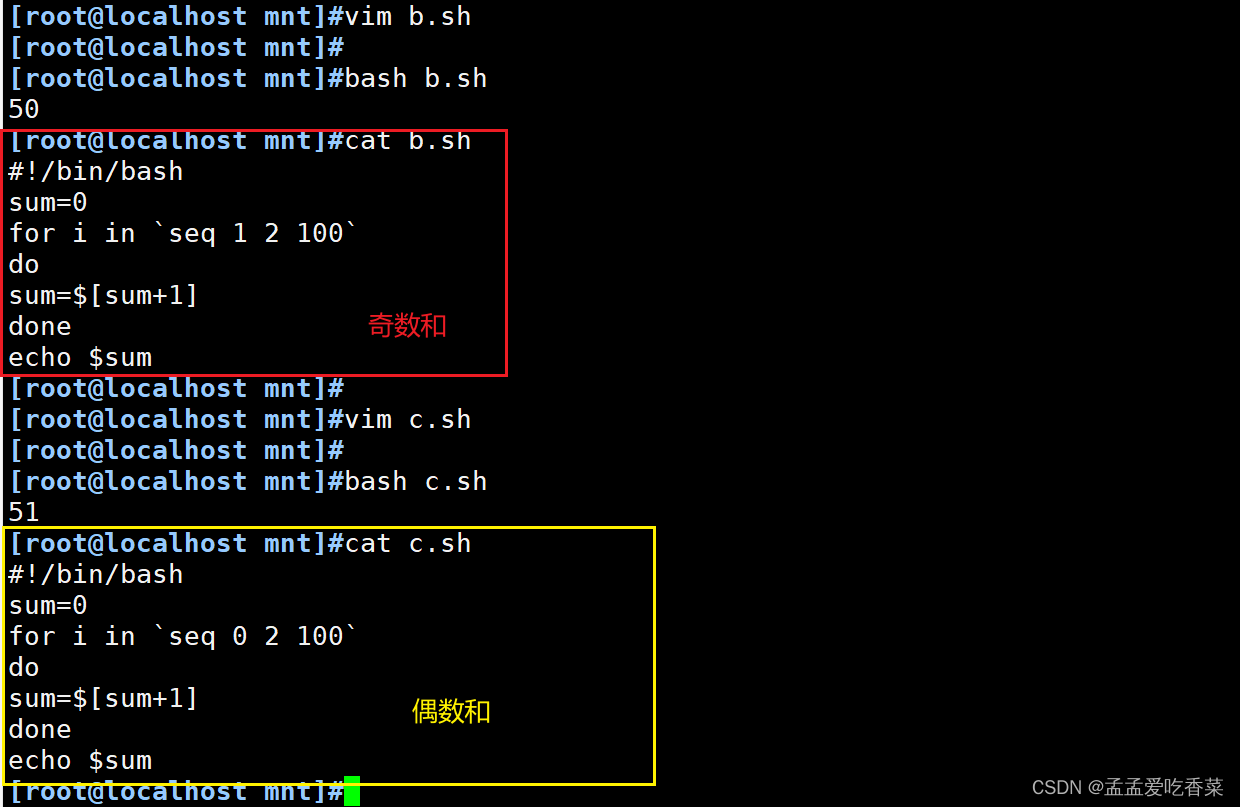
在这里插入代码片#100个数累加
sum=0
for i in {1..100}
do
let sum+=i
done
echo $sum
#奇数和
sum=0
for i in `seq 1 2 100`
do
sum=$[sum+1]
done
echo $sum
#偶数和
将奇数和`seq 1 2 100` 改为 `seq 0 2 100`
第二种
格式1
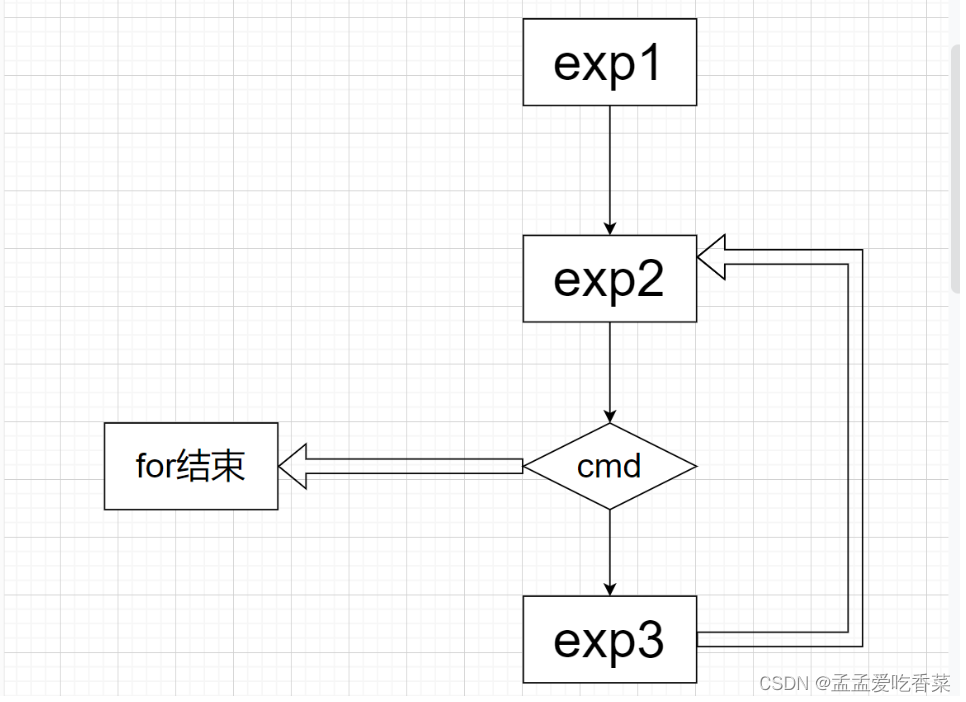
for (( 表达式1; 表达式2; 表达式3 )); do 命令; done
格式2
for ((expr1;expr2;expr3))
do
command
doneexpr1:定义变量并赋初值
expr2:决定是否循环
expr3:决定循环变量如何改变,决定循环什么时候退出
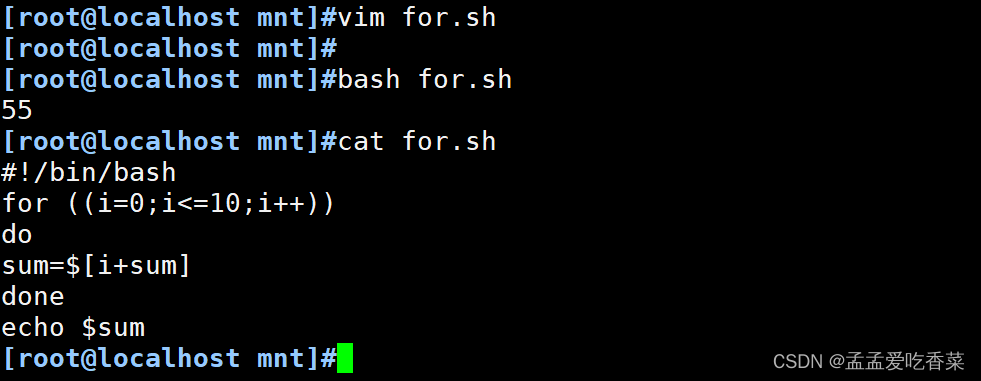
#1到10个数的累加
for ((i=0;i<=10;i++))
do
sum=$[i+sum]
done
echo $sum
#检测网络连通性
for i in {1..254}
do
{
ping -c2 -W1 192.168.65.${i} &>/dev/null #-c2 ping两次,W1超时一秒返回
if [ $? -eq 0 ]
then
echo "host $i is online" >> /data/online.txt
else
echo "host $i is offline">> /data/offline.txt
fi
} & # &后台执行
done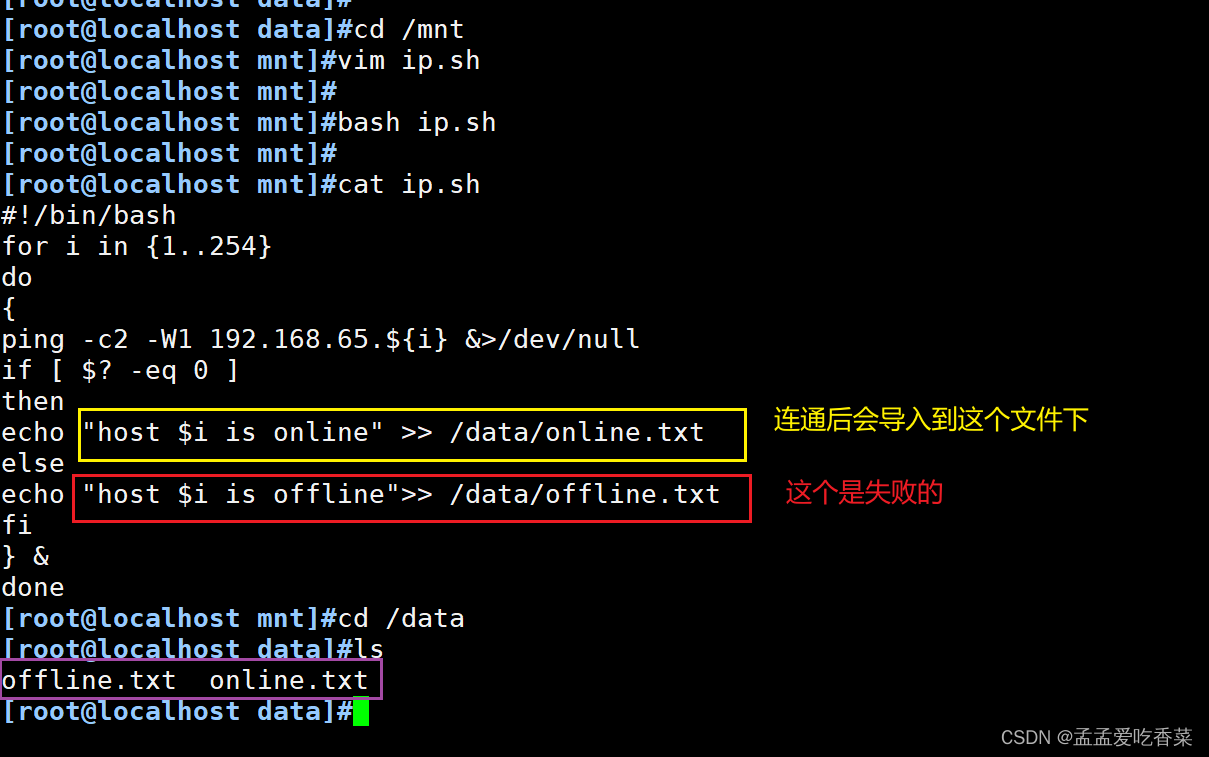
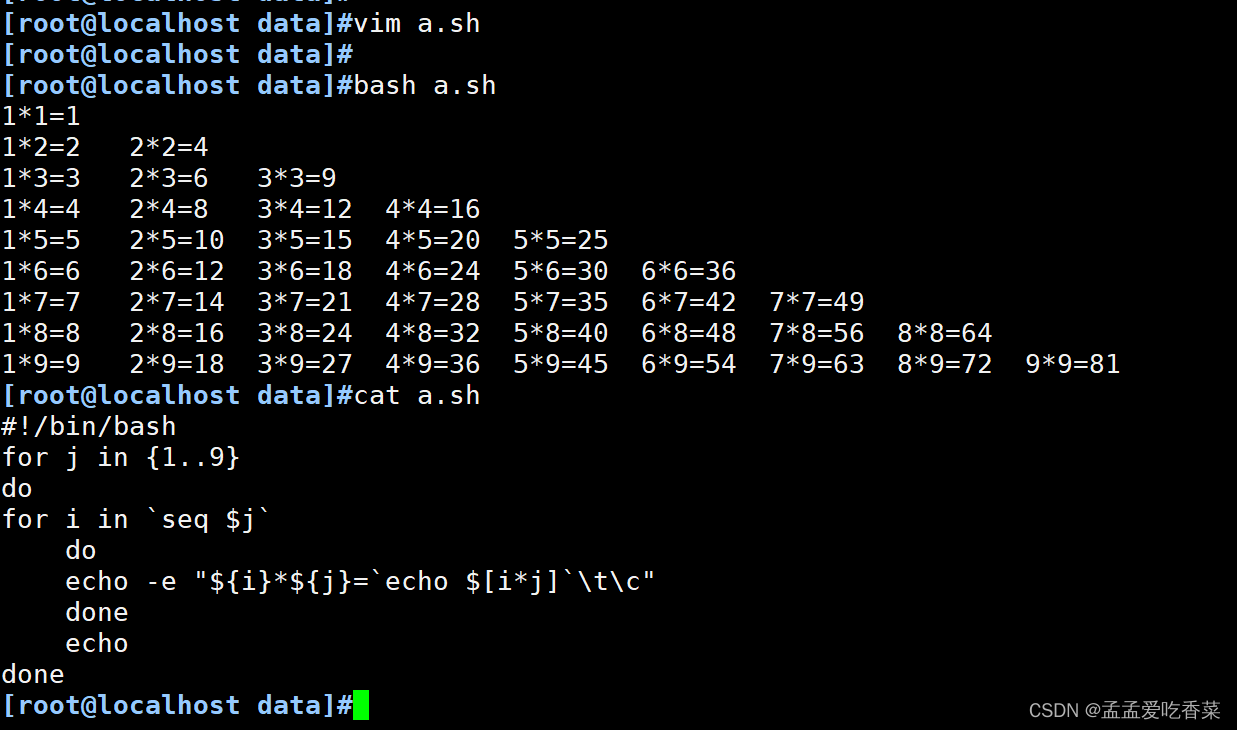
99乘法表
#打印一行*
#!/bin/bash
for i in {1..9}
do
echo -e " * "
done打印正方形
#!/bin/bash
for j in {1..9}
do
for i in {1..9}
do
echo -e " * \c" #\c换行
done
echo #换行
done直角三角形
#!/bin/bash
for j in {1..9}
do
for i in `seq $j`doecho -e "${i}*${j}=`echo $[i*j]`\t\c"doneecho
done#!/bin/bash
for j in {1..9}
do
for i in `seq $j`doecho -e "${i}*${j}=`echo $[i*j]`\t\c" #\t表示对齐doneecho
done
批量添加用户
#!/bin/bash
ulist=$(cat /opt/user.txt)
for uname in $ulist
douseradd $unameecho "123123" |passwd --stdin $uname #免交互设置密码&>/dev/null
done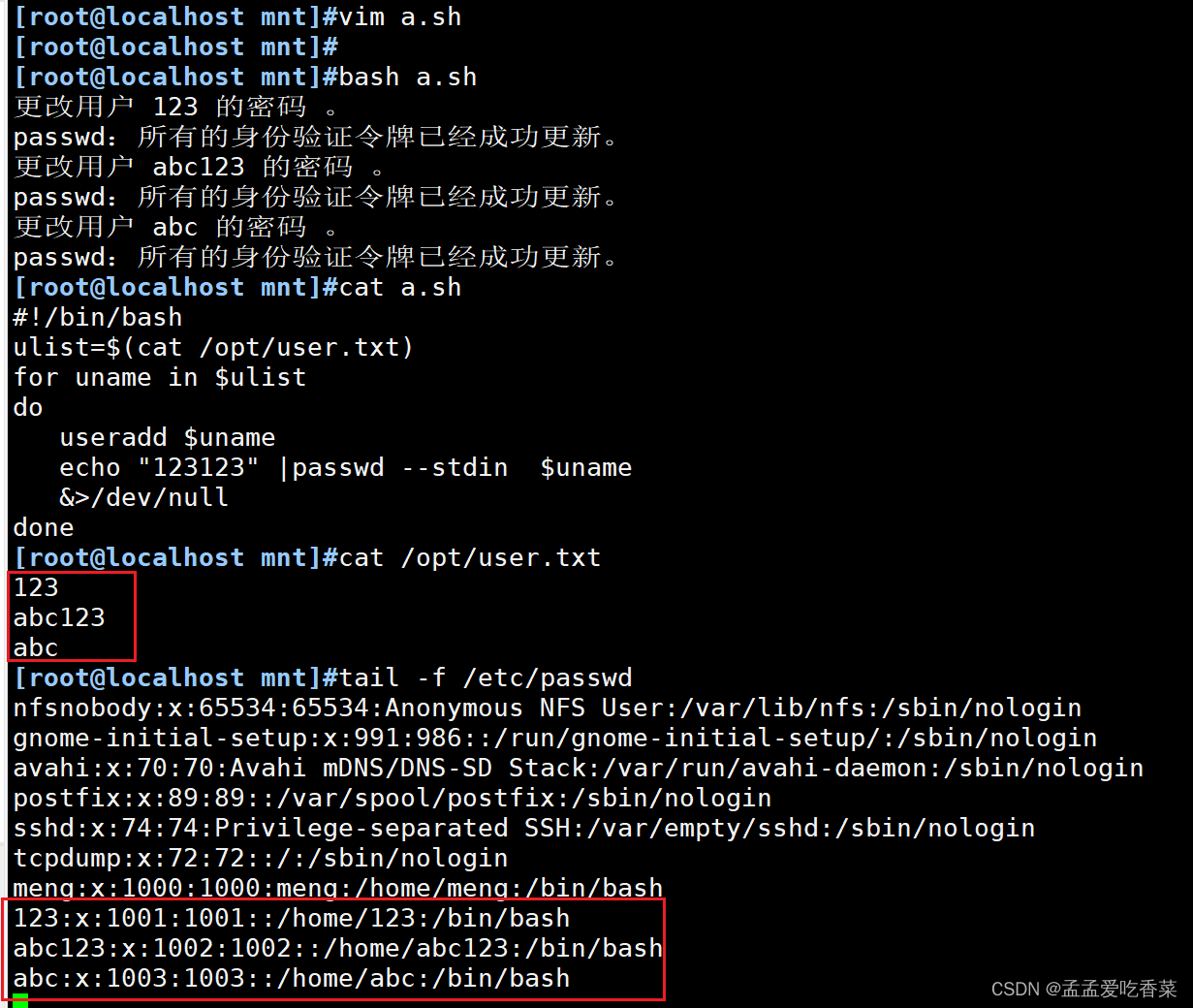
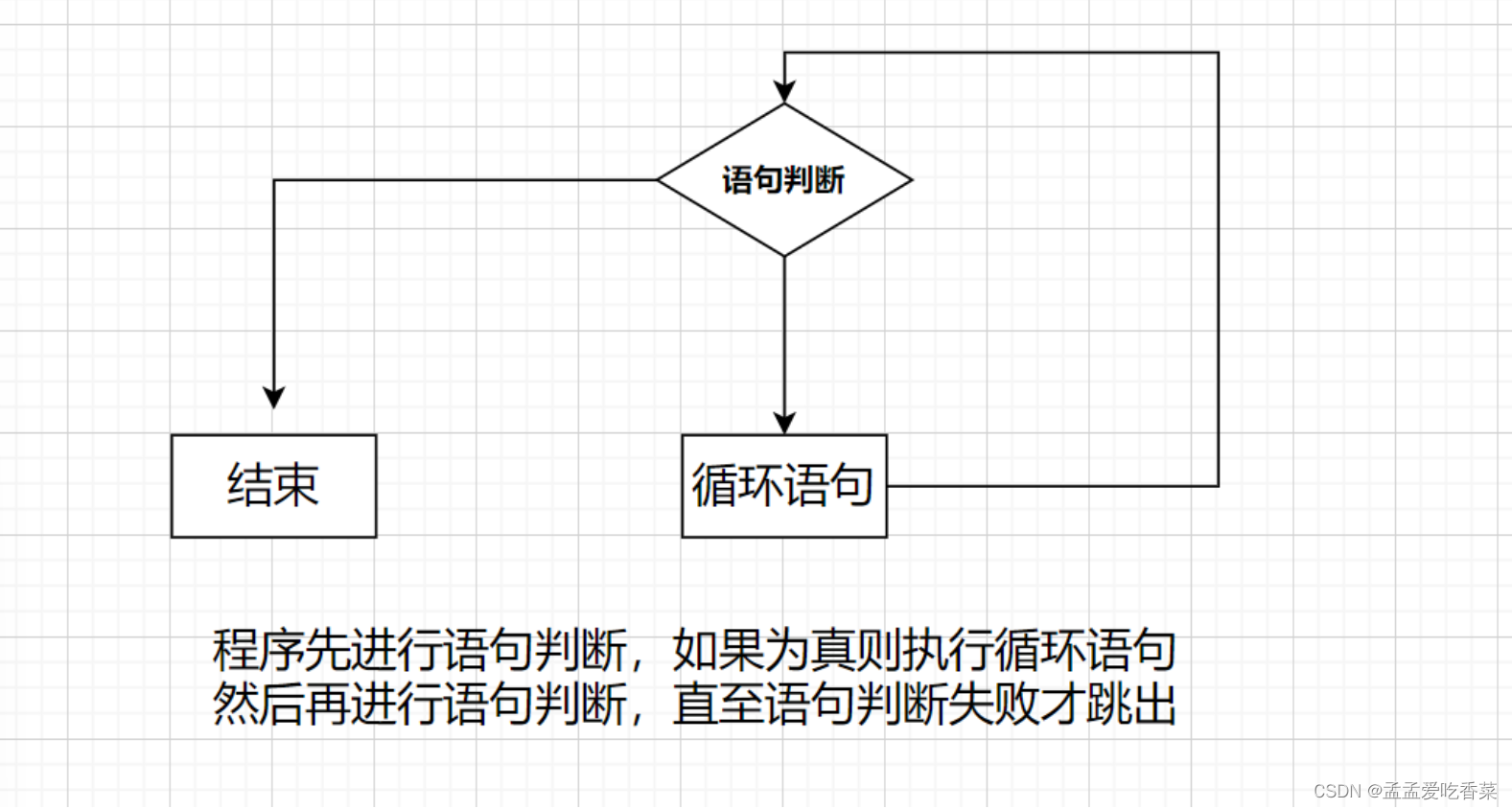
while循环语句
不知道循环次数,知道停止条件时一般使用while
格式
while 判断条件
do
done# 累加
#!/bin/bash
sum=0
i=0
while [ $i -le 100 ]
do
sum=$[i+sum]
let i++
done
echo $sum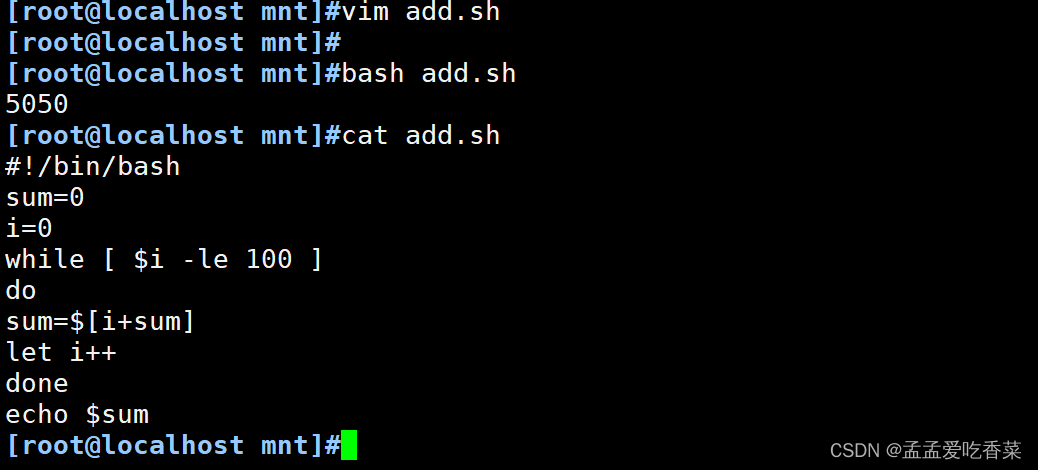
#!/binbash
p=`echo $[PANDOM%1000+1]` #随机生成数
time=0
while true
do
read -p "商品价格" h
let time++
if [ $h -eq $p ]
then
echo "恭喜猜对了,一共猜了${time}"
exit
elif [ $h -gt $p ]
then
echo "您猜的价格高了"
else
echo "您猜的价格低了"
fi
done
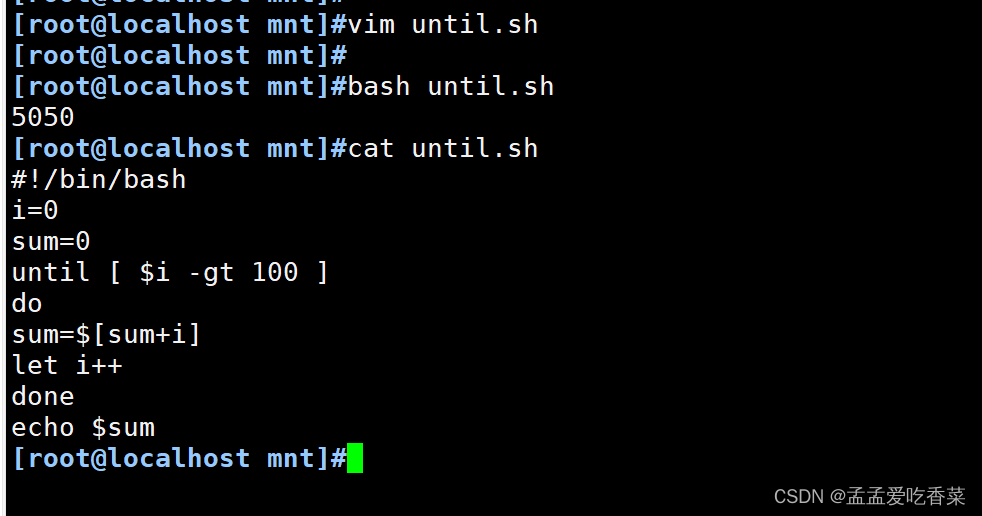
untli循环语句
until 方式的1到100 的累加
#!/bin/bash
i=0
sum=0
until [ $i -gt 100 ]
do
sum=$[sum+i]
let i++
done
echo $sum
[root@localhost data]#bash until.sh
5050
#为指定用户发送在线消息
#若用户不在线(未登录系统),则每1分钟试一次,直至用户登录系统后在发送信息
#用户名与消息通过位置参数传递给脚本
[root@localhost data]#vim test3.sh
#!/bin/bash
username=$1
if [ $# -lt 1 ]
then
echo"请在脚本后输入 用户名和发送信息"
exit 1
fiif grep "^$username" /etc/passwd &>/dev/nu11
then :
else
echo "用户不存在"
exit 1
fiuntil who |grep $username &>/dev/nu11
do
echo "用户不在线"
sleep 5
donemes=$2
echo $mes |write $username
[root@localhost data]#bash test3.shrep "^$username" /etc/passwd &>/dev/nu11
then :
else
echo "用户不存在"
exit 1
fiuntil who |grep $username &>/dev/nu11
do
echo "用户不在线"
sleep 5
donemes=$2
echo $mes |write $username
[root@localhost data]#bash test3.sh
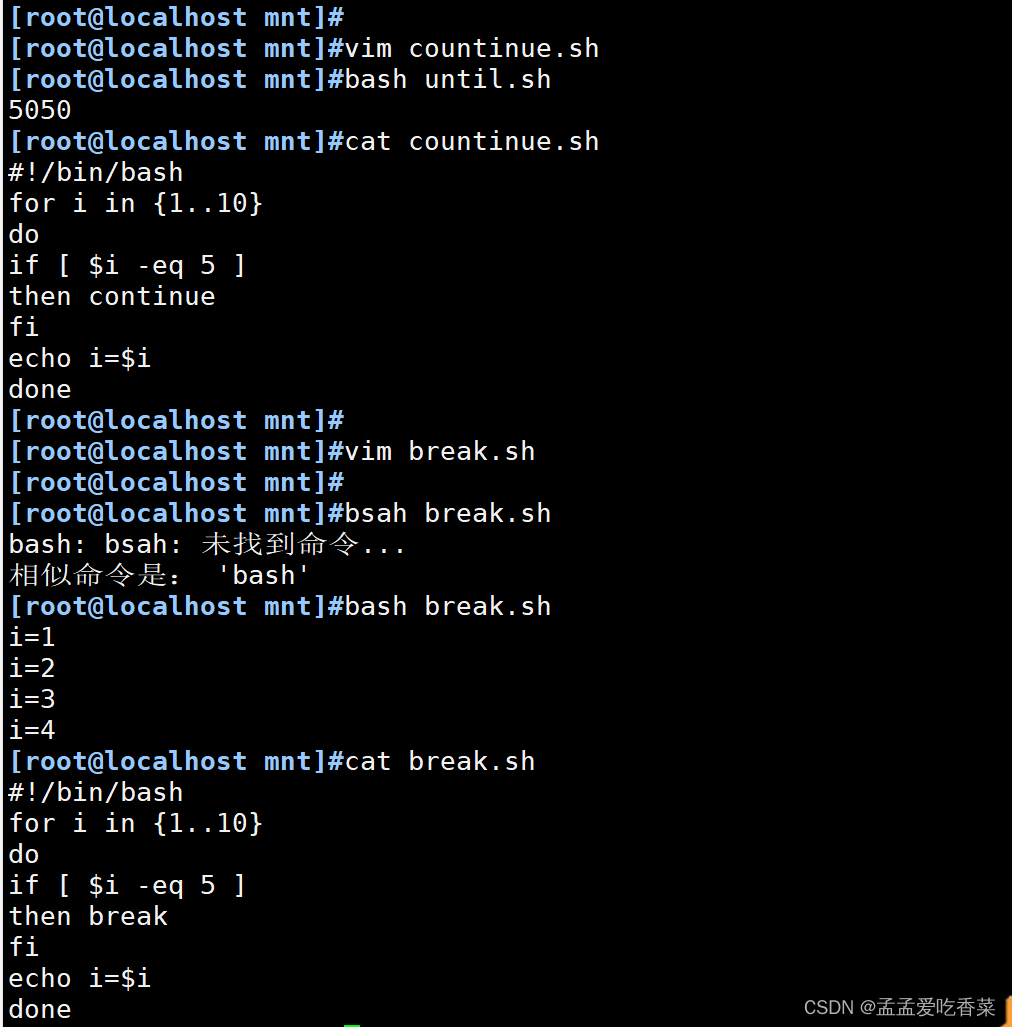
双循环和跳出循环
- break跳出单个循环后面加数字2则代表跳出两层循环
- continue终止某次循环中的命令,但是不会完全终止命令
#本层循环
#!/bin/bash
for i in {1..10}
do
if [ $i -eq 5 ]
then continue
fi
echo i=$i
done#本层循环
#!/bin/bash
for i in {1..10}
do
if [ $i -eq 5 ]
then break
fi
echo i=$i
done