wordpress的网站怎么让他上线怎样把自己做的网页放在网站里

你可以使用 JMeter 来模拟高并发秒杀场景下的压力测试。这里有一个例子,它模拟了同时有 5000 个用户,循环 10 次的情况。

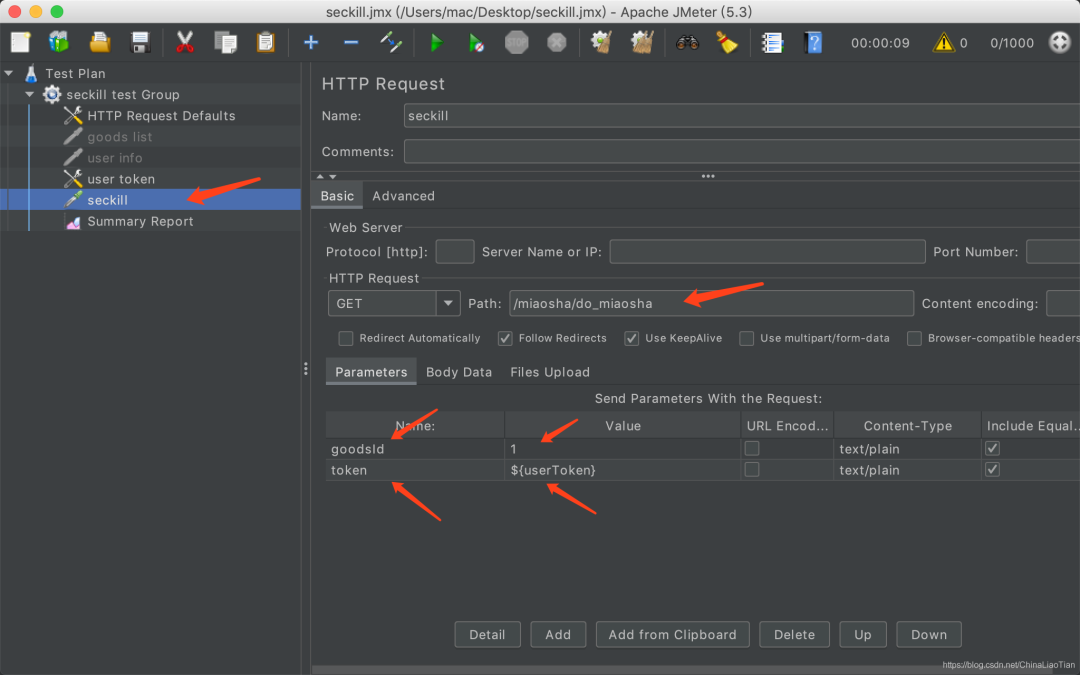
请求默认配置
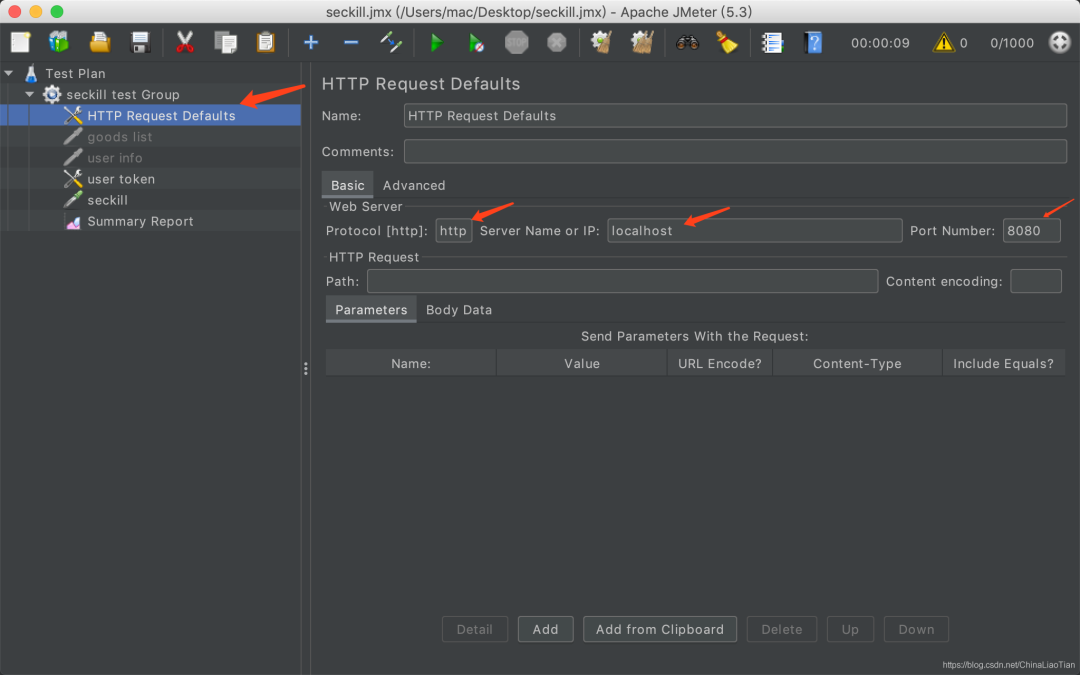
token 配置
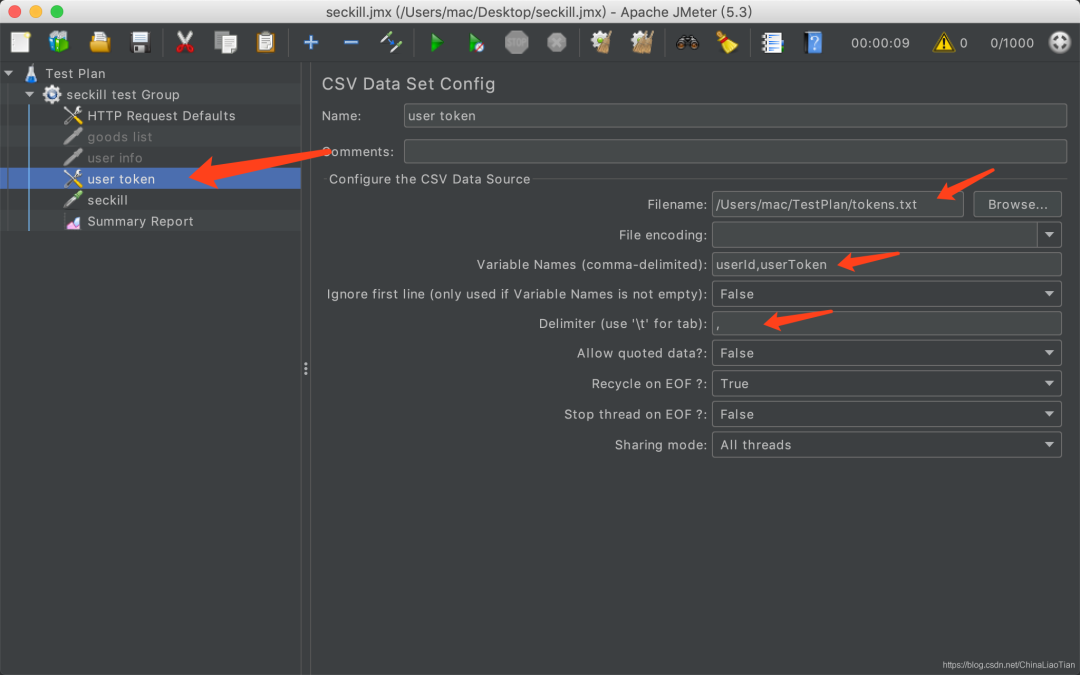

秒杀接口
结果分析

但是,实际企业中,这种压测方式根本不满足实际需求。下面介绍一种分布式压测。
使用场景
单台的JMeter压测能力有限,最大并发压测在1k内的,单机基本满足日常需求了。
但对于有项目来说,需要上万并发的压测,那就需要采用JMeter的分布式压测。
我根据下面思路简单介绍下
JMeter 分布式执行原理:介绍 JMeter 分布式压测的执行原理,包括 master 和 slave 的角色和工作流程。
环境搭建和配置:介绍如何搭建和配置 JMeter 分布式压测环境,包括 master 和 slave 的安装和配置。
测试脚本编写:介绍如何编写 JMeter 测试脚本来模拟秒杀场景。
执行测试和查看结果:介绍如何执行分布式压测并查看测试结果。
要模拟秒杀场景,你需要编写一个 JMeter 测试脚本来模拟用户登录、查看秒杀商品、点击秒杀按钮并下单的过程。
下面是一个简单的例子
添加线程组:添加一个线程组来模拟多个用户同时进行秒杀操作。
添加 HTTP 请求默认值:请求默认值元素来设置服务器名称、端口号和协议等信息。
添加 HTTP Cookie 管理器:管理用户登录后的 Cookie 信息。
添加登录请求:设置请求方法为 POST,路径为登录接口的 URL,并添加用户名和密码等参数。
添加查看秒杀商品请求:秒杀商品的操作。设置请求方法为 GET,路径为查看秒杀商品接口的 URL。
添加点击秒杀按钮请求:在线程组中添加一个 HTTP 请求元素来模拟用户点击秒杀按钮的操作。设置请求方法为 POST,路径为点击秒杀按钮接口的 URL,并添加必要的参数。
下面是具体的配置步骤
JMeter实现分布式并发
配置步骤:
1、master端配置
路径:bin/jmeter.properties,
搜索到remote
其中ip地址是我虚拟机自己设置的固定ip(强烈建议配置固定ip,防止后期连接不上报错,固定ip不会配置的见CC是谁:Linux虚拟机配置静态ip),端口也是在虚拟机配置文件中自己配置的,后面会讲
需要将remote_hosts中的127.0.0.1删除,否则“远程启动所有”时启动不起来
设置成功后在master端看到远程启动中包含了刚才配置的slave,如果看不到可以重启下JMeter
2、slave端配置
路径:bin/jmeter.properties,
搜索到1099,启用端口,保存
3、slave端启动
Jmeter-server(bin目录下)
注意:命令jmeter-server报错
修改命令为,后面ip是本机的ip,再次启动,成功:
./jmeter-server -Djava.rmi.server.hostname=192.168.8.14
4、master执行
配置了多台slave时,直接“远程启动所有”,所有远程服务器会同时启动
注意:若需要压测100,在10台机器,则线程设置10即可,jmeter执行中不会自动负载均衡,每一台服务器都会完整地运行测试计划。
4.1代表拒绝连接,slave
模拟秒杀场景,你需要编写一个 JMeter 测试脚本来模拟用户登录、查看秒杀商品、点击秒杀按钮并下单的过程。
配置步骤:
1、master端配置
路径:bin/jmeter.properties,
搜索到remote
其中ip地址是我虚拟机自己设置的固定ip(强烈建议配置固定ip,防止后期连接不上报错,固定ip不会配置的见CC是谁:Linux虚拟机配置静态ip),端口也是在虚拟机配置文件中自己配置的。
需要将remote_hosts中的127.0.0.1删除,否则“远程启动所有”时启动不起来
设置成功后在master端看到远程启动中包含了刚才配置的slave,如果看不到可以重启下JMeter
2、slave端配置
路径:bin/jmeter.properties,
搜索到1099,启用端口,保存
3、slave端启动
Jmeter-server(bin目录下)
注意:命令jmeter-server报错
修改命令为,后面ip是本机的ip,再次启动,成功:
./jmeter-server -Djava.rmi.server.hostname=192.168.8.14
4、master执行
配置了多台slave时,直接“远程启动所有”,所有远程服务器会同时启动
注意:若需要压测100,在10台机器,则线程设置10即可,jmeter执行中不会自动负载均衡,每一台服务器都会完整地运行测试计划。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
