郴州网站制作公司哪家好网络服务提供者不得在什么时间
目录
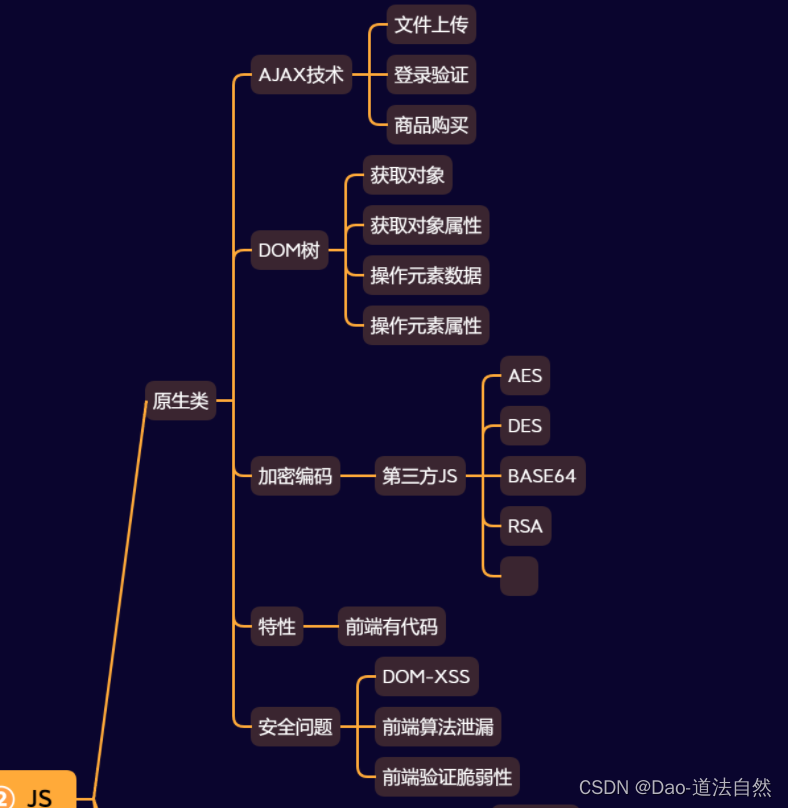
JS原生开发-DOM树-用户交互
JS导入库开发-编码加密-逆向调试
思维导图
JS知识点:
功能:登录验证,文件操作,SQL操作,云应用接入,框架开发,打包器使用等
技术:原生开发,DOM,常见库使用,框架开发(Vue,NodeJS),打包器(Webpack)等
安全:原生开发安全,NodeJS安全,Vue安全,打包器Webpack安全,三方库安全问题等
JS原生开发-DOM树-用户交互
DOM :文档操作对象浏览器提供的一套专门用来操作网页代码内容的功能,实现自主或用户交互动作反馈
- 在Web开发中,浏览器将HTML文档解析为DOM树的结构。DOM树由节点(Nodes)组成,节点可以是元素节点、文本节点、注释节点等。每个节点都有与之相关联的属性、方法和事件。
- 通过使用DOM,您可以通过JavaScript或其他支持DOM的编程语言来访问和操作HTML文档的内容、结构和样式。您可以使用DOM提供的方法和属性来选择元素、修改元素的属性和内容、添加或删除元素,以及响应用户交互等。
安全问题:本身的前端代码通过DOM技术实现代码的更新修改,但是更新修改如果修改的数据可以由用户来指定,就会造成DOM-XSS攻击!
1、获取对象
标签:直接写
Class:加上符号.
id:加上符号#
<h1 id="myHeader" onclick="getValue()">这是标题</h1> document.querySelector('h1') document.querySelector('.id') document.querySelector('#myHeader')2、获取对象属性
<h1 id="myHeader" onclick="getValue()">这是标题</h1> const h1=document.querySelector('h1') const id=h1.id console.log(id)2、操作元素数据
innerHTML 解析后续代码
innerText 不解析后续代码
3、操作元素属性
可以通过 js 修改页面元素的内容属性文本等,如下修改了页面中图片的 src,实现了图片的变换
className src id等 <img src="iphone.jpg" width="300" height="300"></img> const src=document.querySelector('img') src.src='huawei.png
随便下载两张照片放到之前的 js 目录下
创建 dom.html, 内容如下:演示获取图片 src 和标签文本
<h1 id="myHeader" onclick="update1()">这是H1</h1>
<img src="iphone.jpg" width="300" height="300"><br>
<button onclick="update()">刷新</button>
<script>function update(){const img=document.querySelector('img');console.log(img.src);}function update1(){const h1=document.querySelector('h1');console.log(h1.innerText);}
</script>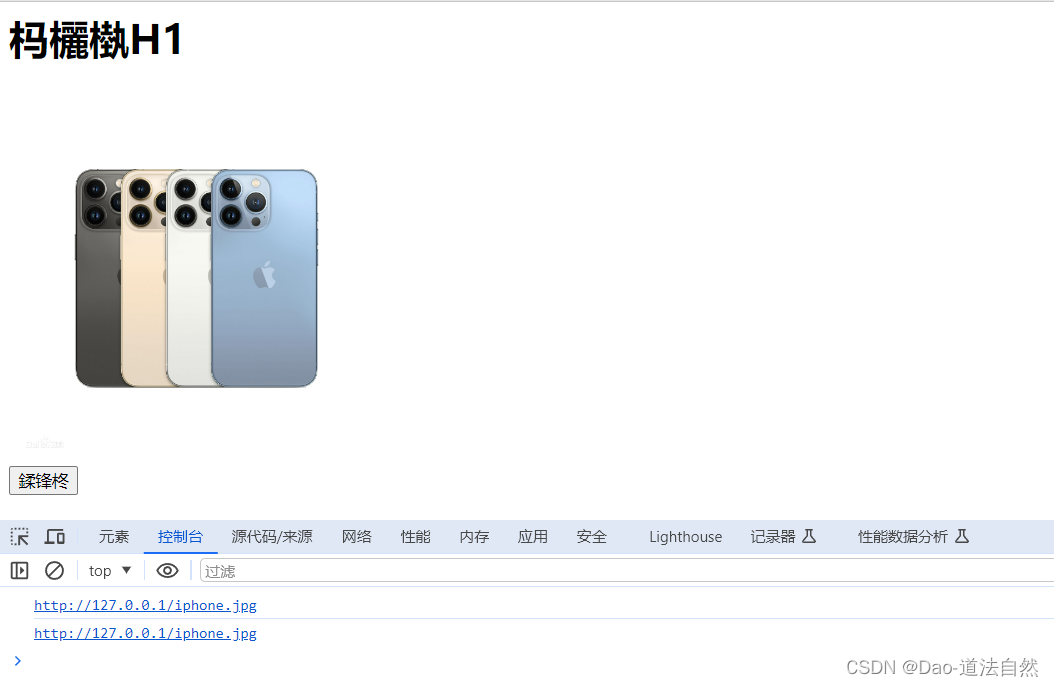

这里开始演示点击刷新修改图片和点击文本修改标签文本
<!--<h1 id="myHeader" onclick="update1()">这是标题</h1>--><!--<img src="iphone.jpg" width="300" height="300"><br>--><!--<button onclick="update()">刷新</button>--><!--<script>-->
<!-- function update(){-->
<!-- const s=document.querySelector('img')-->
<!-- s.src="javascript:alert(‘XSS’);"-->
<!-- //如果这里huawei.png为一个变量由用户传递决定,那么就会造成DOM XSS-->
<!-- }--><!-- function update1(){-->
<!-- const s=document.querySelector('h1')-->
<!-- //s.innerText="这是小迪<br>"-->
<!-- s.innerHTML='<img src=# onerror="alert(1)">'-->
<!-- console.log(str)-->
<!-- }-->
<!--</script>--><!--<h1 id="myHeader" onclick="update1()">这是H1</h1>--><!--<img src="iphone.jpg" width="300" height="300"><br>--><!--<button onclick="update1()">刷新</button>--><!--<script>-->
<!-- function update(){-->
<!-- const img=document.querySelector('img');-->
<!-- console.log(img.src);-->
<!-- }-->
<!-- function update1(){-->
<!-- const h1=document.querySelector('h1');-->
<!-- console.log(h1.innerText);-->
<!-- }--><!--</script>-->
<h1 id="myHeader" onclick="update1()">这里是SuYou</h1><img src="iphone.jpg" width="300" height="300"><br><button onclick="update()">刷新</button><script>function update(){const img=document.querySelector('img');img.src = 'huawei.png';console.log(img.src);}function update1(){const h1=document.querySelector('h1');const str = h1.innerText;console.log(str);// 迪总是置换了文本,我让它点一下左移一下,小把戏,见笑见笑const first = str[0];var remain = str.substring(1,str.length);var new_str = remain + first;h1.innerText = new_str; // innerText不解析后续代码,只是当文本// h1.innerHTML = '<h3>' + new_str + '</h3>'; // innerHTML不解析后续代码,只是当文本}</script>此时点击 h1 刷新标题内容,点击刷新按钮,刷新照片

安全问题:本身的前端代码通过DOM技术实现代码的更新修改,但是更新修改如果修改的数据可以由用户来指定,就会造成DOM-XSS攻击!
如 update 中的 img.src, 如果这里的 huawei.png 为一个变量,可以由用户传递决定,那么就可能会造成 DOM XSS, 如下
<h1 id="myHeader" onclick="update1()">这是标题</h1><img src="iphone.jpg" width="300" height="300"><br><button onclick="update()">刷新</button><script>function update(){const s=document.querySelector('img')s.src="javascript:alert(‘XSS’);"//如果这里huawei.png为一个变量由用户传递决定,那么就会造成DOM XSS}function update1(){const s=document.querySelector('h1')//s.innerText="这是小迪<br>"s.innerHTML='<img src=# onerror="alert(1)">'console.log(str)}
</script>点击刷新:可见浏览器进行了过滤拦截

点击标题,绕过
update1 函数通过 innerHTML 插入带有 onerror 事件的 img 元素,这可能导致 XSS(跨站脚本攻击)漏洞。在实际应用中,需要谨慎处理用户提供的内容,以防止安全漏洞。

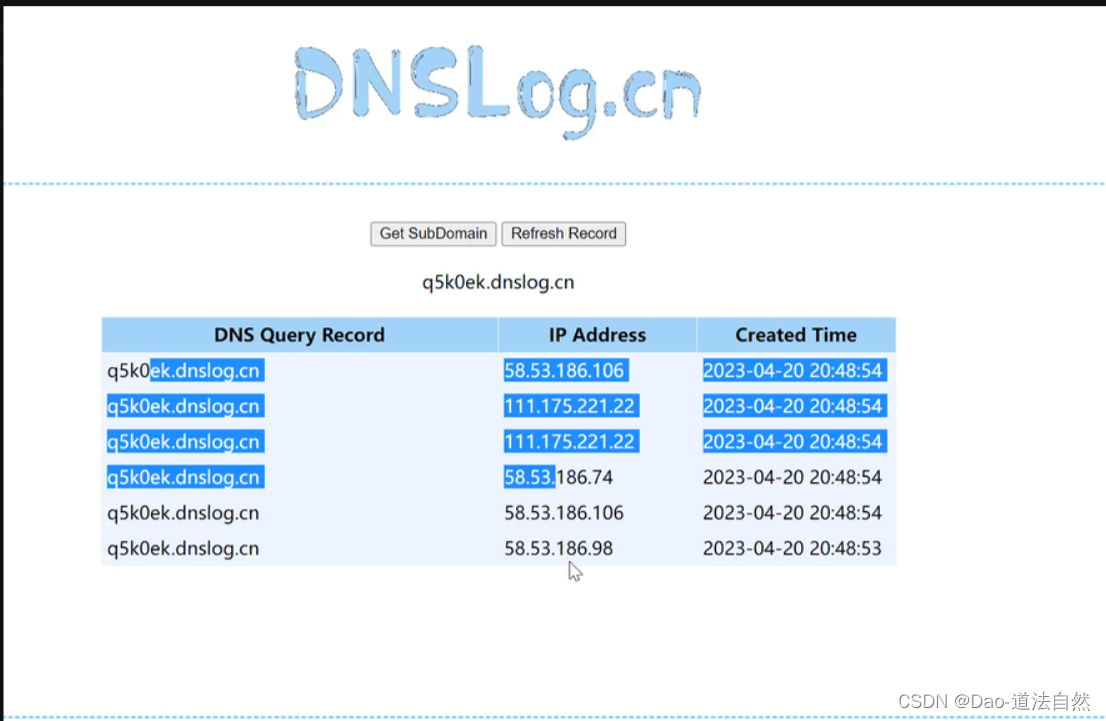
实测:网易云翻译:可以使用带外dns,造成数据库ip泄露
发现输入后即使不点翻译,页面仍然发生变化,猜测有 js
参数可控,并且做了替换,怀疑可以是DOM XSS
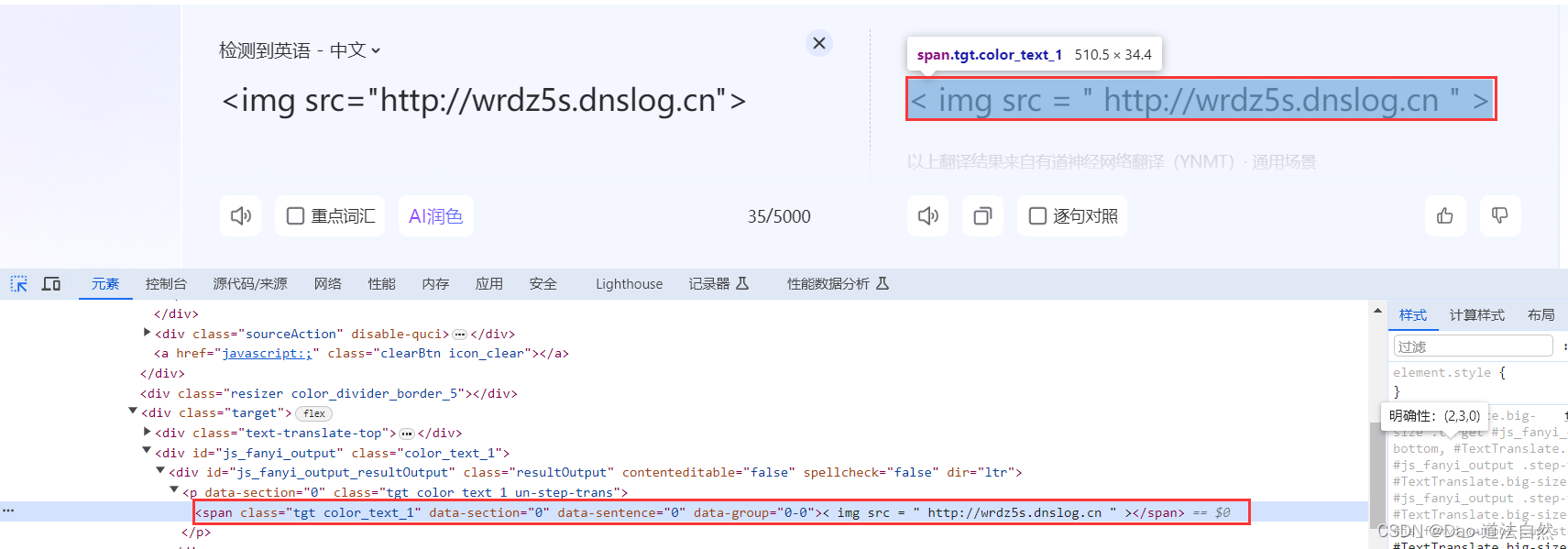
测试时使用 dnslog,在输入内容中添加。dnslog.cn 是 dnslog 生成的域名,自行替换
<img src="http://dnslog.cn">在浏览器开发者工具 network 中发现页面确实向 dnslog.cn 发送了请求。
在 source 中搜索关键字 querySelector 发现可疑 js 文件 translate.js
直接在翻译中输入 img 标签会被实体化,即被过滤,但是当鼠标放到右侧滑过之后,左侧 img 标签成功执行,可能是使用了 js 鼠标滑过事件 (盲猜一波类似 mouseover 之类的事件),从左到右被过滤了,从右到左没有,所以导致了成功执行



JS导入库开发-编码加密-逆向调试
md5
<!-- 引入 md5.js 脚本 --> <script src="js/md5.js"></script><!-- JavaScript 代码 --> <script>// 定义字符串变量var str1 = 'xiaodi jichu No1';// 使用 md5.js 中的 md5 函数对字符串进行加密var str_encode = md5(str1);// 输出加密后的字符串到控制台console.log(str_encode); </script>输出:afe5119ec0ab46b55432fc5e24f1dc62
SHA1
<!-- 引入 crypto-js.js 脚本 --> <script src="js/crypto-js.js"></script><!-- JavaScript 代码 --> <script>// 定义字符串变量var str1 = 'xiaodisec';// 使用 CryptoJS.SHA1 函数对字符串进行 SHA-1 加密,并将结果转为字符串var str_encode = CryptoJS.SHA1(str1).toString();// 输出加密后的字符串到控制台console.log(str_encode); </script>输出:ce22eaa1c5ebd3dfb3f4474b66f6d3612d4cb3ee
HMAC
<!-- 引入 crypto-js.js 脚本 --> <script src="js/crypto-js.js"></script><!-- JavaScript 代码 --> <script>// 定义密钥和字符串变量var key = 'key';var str1 = 'xiaodisec';// 使用 CryptoJS.HmacSHA256 函数生成 HMAC-SHA256 散列var hash = CryptoJS.HmacSHA256(key, str1);// 将散列结果转为十六进制字符串var str_encode = CryptoJS.enc.Hex.stringify(hash);// 输出加密后的字符串到控制台console.log(str_encode);// 输出示例:'11a7960cd583ee2c3f1ed910dbc3b6c3991207cbc527d122f69e84d13cc5ce5c' </script>输出:08ac6dc8773bd34dcadeffb2b90a8b8f5be9453a9dce7cf09d4da2fcb363d9e7
AES
<script src="js/crypto-js.js"></script> <script type="text/javascript">var aseKey = "12345678" // 定制秘钥,长度必须为:8/16/32位, 长度不一致也没问题var message = "xiaodisec"; // 需要加密的内容// 加密 DES/AES切换只需要修改 CryptoJS.AES <=> CryptoJS.DESvar encrypt = CryptoJS.AES.encrypt(message, CryptoJS.enc.Utf8.parse(aseKey), // 参数1=密钥, 参数2=加密内容{mode: CryptoJS.mode.ECB, // 为DES的工作方式padding: CryptoJS.pad.Pkcs7 // 当加密后密文长度达不到指定整数倍(8个字节、16个字节)则填充对应字符}).toString(); // toString=转字符串类型console.log(encrypt);var decrypt = CryptoJS.AES.decrypt(encrypt, CryptoJS.enc.Utf8.parse(aseKey), // 参数1=密钥, 参数2=解密内容{mode: CryptoJS.mode.ECB,padding: CryptoJS.pad.Pkcs7}).toString(CryptoJS.enc.Utf8); // toString=转字符串类型,并指定编码console.log(decrypt); // "xiaodisec" </script>输出:g4ohopaiYA34XXLsV92Udw== xiaodisec
DES
<script src="js/crypto-js.js"></script> <script type="text/javascript">var aseKey = "12345678" // 定制秘钥,长度必须为:8/16/32位, 长度不一致也没问题var message = "xiaodisec"; // 需要加密的内容// 加密 DES/AES切换只需要修改 CryptoJS.AES <=> CryptoJS.DESvar encrypt = CryptoJS.DES.encrypt(message, CryptoJS.enc.Utf8.parse(aseKey), // 参数1=密钥, 参数2=加密内容{mode: CryptoJS.mode.ECB, // 为DES的工作方式padding: CryptoJS.pad.Pkcs7 // 当加密后密文长度达不到指定整数倍(8个字节、16个字节)则填充对应字符}).toString(); // toString=转字符串类型console.log(encrypt); // 控制台打印 CDVNwmEwDRM//解密var decrypt = CryptoJS.DES.decrypt(encrypt, CryptoJS.enc.Utf8.parse(aseKey), // 参数1=密钥, 参数2=解密内容{mode: CryptoJS.mode.ECB,padding: CryptoJS.pad.Pkcs7}).toString(CryptoJS.enc.Utf8); // toString=转字符串类型,并指定编码console.log(decrypt); // 控制台打印 "i am xiaozhou ?"</script>输出:WVSwdlodMcV2n1FH72uXgw== xiaodisec
RSA
<script src="js/jsencrypt.js"></script> <script type="text/javascript">// 公钥 私匙是通过公匙计算生成的,不能盲目设置var PUBLIC_KEY = '-----BEGIN PUBLIC KEY-----MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALyBJ6kZ/VFJYTV3vOC07jqWIqgyvHulv6us/8wzlSBqQ2+eOTX7s5zKfXY40yZWDoCaIGk+tP/sc0D6dQzjaxECAwEAAQ==-----END PUBLIC KEY-----';//私钥var PRIVATE_KEY = '-----BEGIN PRIVATE KEY-----MIIBVQIBADANBgkqhkiG9w0BAQEFAASCAT8wggE7AgEAAkEAvIEnqRn9UUlhNXe84LTuOpYiqDK8e6W/q6z/zDOVIGpDb545NfuznMp9djjTJlYOgJogaT60/+xzQPp1DONrEQIDAQABAkEAu7DFsqQEDDnKJpiwYfUE9ySiIWNTNLJWZDN/Bu2dYIV4DO2A5aHZfMe48rga5BkoWq2LALlY3tqsOFTe3M6yoQIhAOSfSAU3H6jIOnlEiZabUrVGqiFLCb5Ut3Jz9NN+5p59AiEA0xQDMrxWBBJ9BYq6RRY4pXwa/MthX/8Hy+3GnvNw/yUCIG/3Ee578KVYakq5pih8KSVeVjO37C2qj60d3Ok3XPqBAiEAqGPvxTsAuBDz0kcBIPqASGzArumljkrLsoHHkakOfU0CIDuhxKQwHlXFDO79ppYAPcVO3bph672qGD84YUaHF+pQ-----END PRIVATE KEY-----';//使用公钥加密var encrypt = new JSEncrypt();//实例化加密对象encrypt.setPublicKey(PUBLIC_KEY);//设置公钥var message = 'xiaodisec' // 需要加密的数据var encrypted = encrypt.encrypt(message);//对指定数据进行加密console.log(encrypted) // 'JQ83h8tmJpsSZcb4BJ3eQvuqIAs3ejepcUUnoFhQEvum8fA8bf1Y/fG+DO1bSIVNJF6EOZKe4wa0njv6aOar9w=='//使用私钥解密var decrypt = new JSEncrypt(); // 创建解密对象decrypt.setPrivateKey(PRIVATE_KEY); //设置私钥var uncrypted = decrypt.decrypt(encrypted); //解密 'xiaodisec'console.log(uncrypted); </script>输出:Fw1H5KoC6zZnwAzLee8z5ubmQYSqaVqu711VI+NBavYT9bkWpzxUtZHmbSUvLbuCblPO96NdfoQHtPe9TURo6A== xiaodisec
‘admin’ OR 1=1 — ‘的含义
首先,让我们逐步解析这个语句的含义。在MySQL中,’admin’表示一个字符串常量,OR关键字表示逻辑或运算符,而1=1是一个恒定为真的条件。最后的’– ‘表示注释,使得引号后的内容成为注释而不被解析。
换句话说,这个语句在条件中使用了1=1,这个条件总是为真,因此结果总是返回真。这就可以绕过许多条件验证,让用户以admin的身份执行相关操作。
举个例子,假设SQL语句如下:
SELECT * FROM users WHERE username = 'admin' OR 1=1 -- ' AND password = '123456'这个语句的意图是从users表中选择username为’admin’且password为’123456’的记录。然而,由于’admin’ OR 1=1 — ‘这个条件恒为真,实际上会选择所有的记录,而不仅仅是admin账户。
若 payload 的测试数据为 admin ‘1=1, 但网站接受的是加密数据,你直接发明文过去,肯定是没用效果的,需要将 payload 也以相同的加密算法加密发送才会有效
逆向调试加密算法
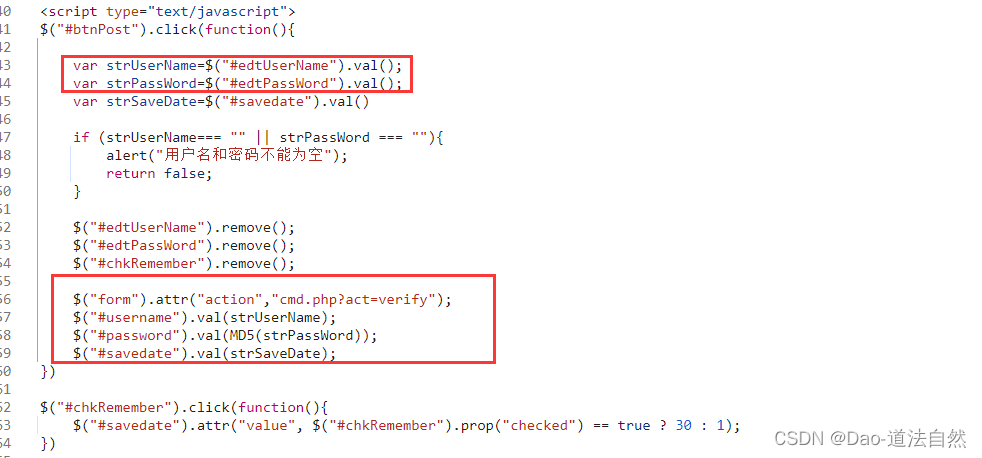
打开页面,选择密码右击鼠标打开检查,找到相关id值edtPassWord,并进行搜索$("#btnPost").click(function() 加#后证明是想取id值中的edtPassWord
加密方式
分析代码过程:发出疑问如果加密格式不显示出来,怎样判断加密的方式是什么?
可以借助检查的控制台,尝试输入获取加密后的密码值,再和提交表单的加密值进行比对,若一致则证明识别出。(一般安全防护比较强的,不会把运行的所以东西全加载到浏览器上)


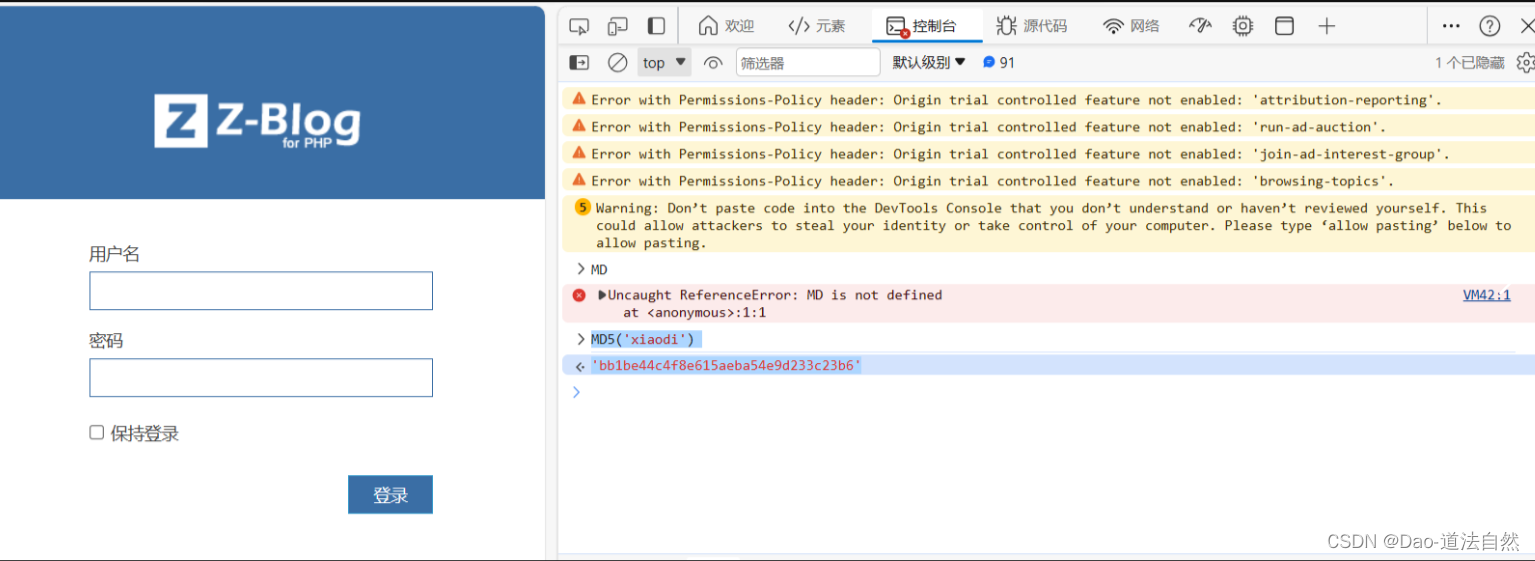

断点调试:一般安全防护比较强的,不会把运行的所有东西全加载到浏览器上,所以要执行断点调试
https://my.sto.cn/
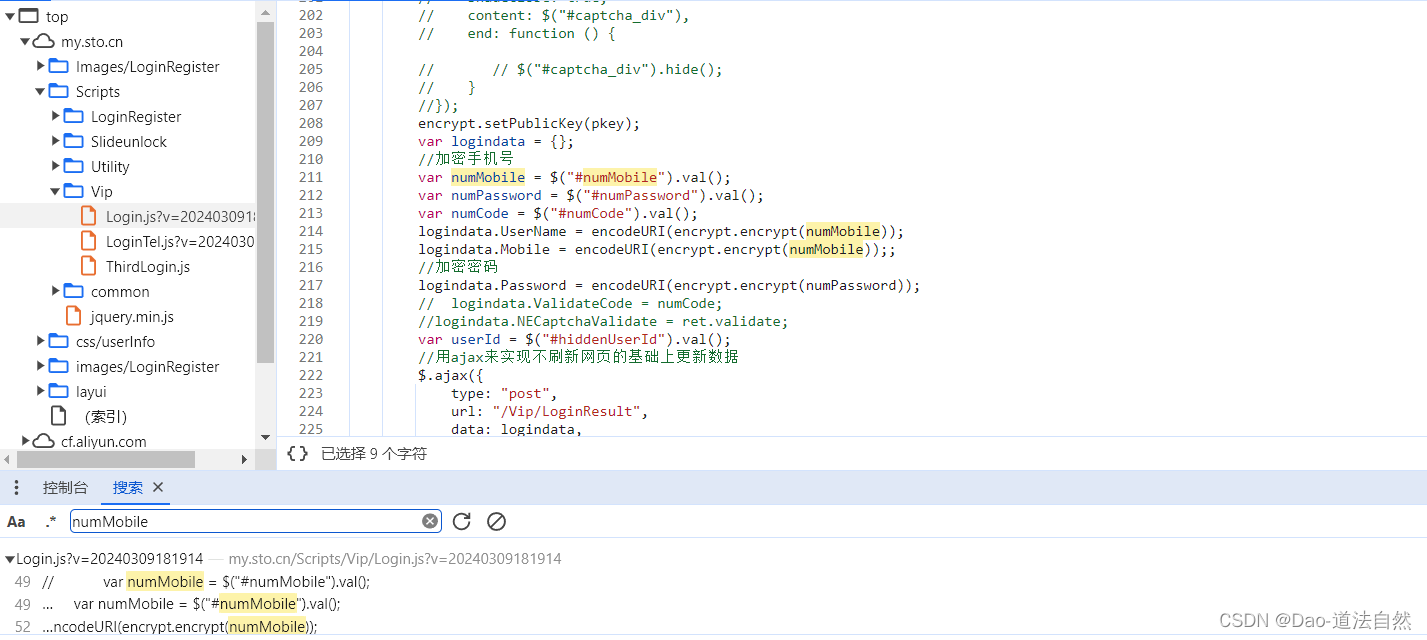
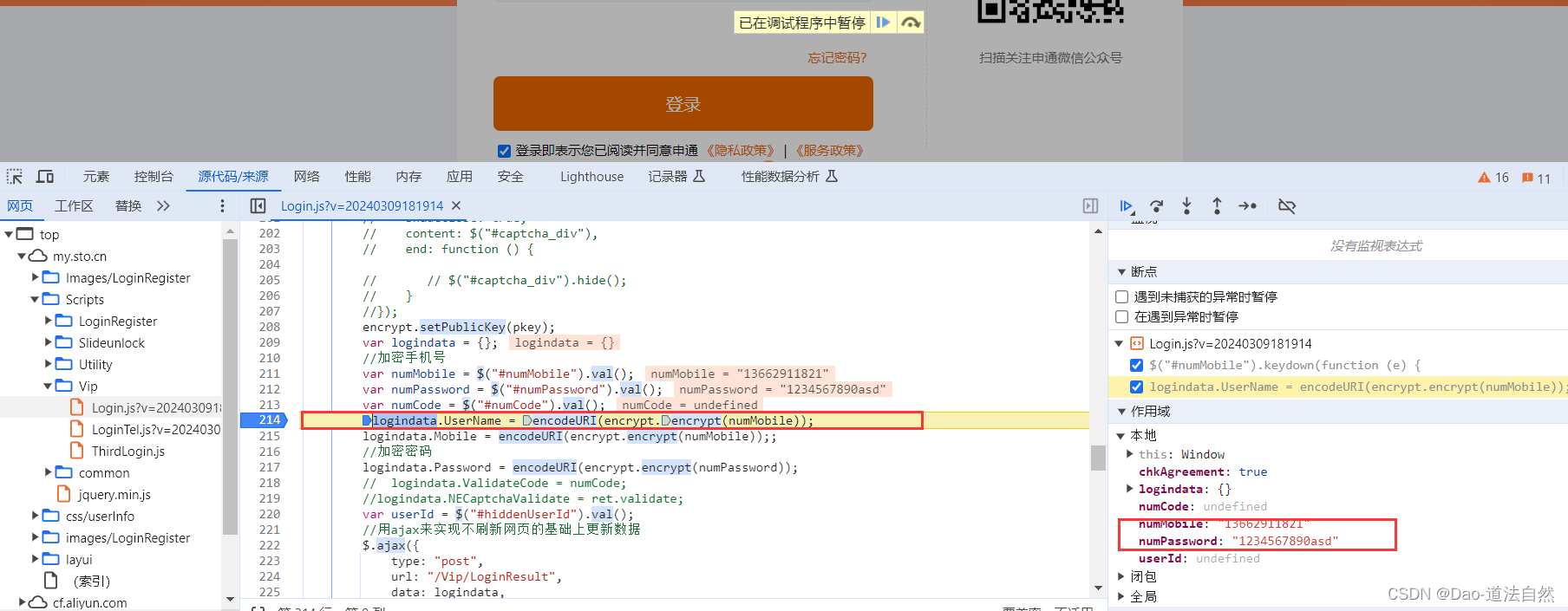
打开页面,选择密码右击鼠标打开检查找到相关id值numPassword并进行搜索
找到密码的加密格式,但是没有明文展现出来
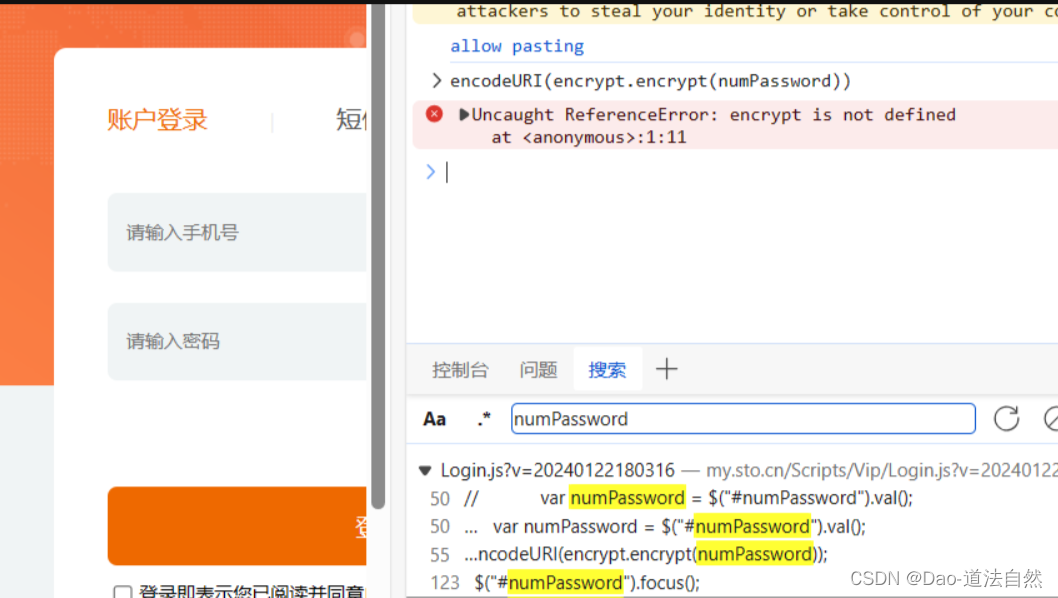
采用之前的方式在控制台中输入相应的代码encodeURI(encrypt.encrypt(numPassword))报错encrypt is not defined,有一些文件只在服务器本地执行,不会加载到浏览器中
说明这部分文件是放在浏览器上的,并不是在本地的,只有用到的时候才会传输到本地执行
必须采用调试断点的方式来,通过服务器获取其执行文件,然后修改对应的返回密文即可
对应地方打上断点,点击登录,进入断点调试,发现右侧出现输入的账号密码内容
点击最右侧按钮,进入调试,再次打开控制台,并输入encodeURI(encrypt.encrypt(numPassword))发现成功回显加密后的密码
这时候可以执行是因为加密的文件已经被放入浏览器的内存中

思维导图