南通网站定制企业本网站立足于海外服务器
GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
目录
- GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比
- 预测效果
- 基本介绍
- 程序设计
- 参考资料
预测效果







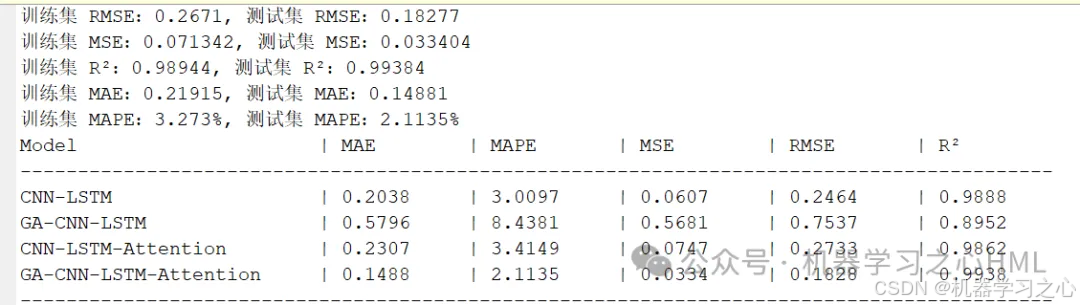
基本介绍
基于GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比(仅运行一个main即可)
Matlab代码,每个模型的预测结果和组合对比结果都有!
1.无需繁琐步骤,只需要运行一个main即可一键出所有图像。
2.程序已经调试好,无需更改代码替换数据集即可运行!!!数据格式为excel!
3.GA优化参数为:隐藏层节点数,学习率,正则化系数。
4.遗传算法(Genetic Algorithm,GA)是一种模拟自然选择和遗传机制的优化搜索算法,由美国的 John holland于20世纪70年代提出。它通过模拟生物进化过程中的染色体基因的交叉、变异等过程,将问题的求解过程转换成计算机仿真运算,以搜索最优解。。
5.运行环境要求MATLAB版本为2023b及其以上。
评价指标包括:R2、MAE、MSE、RPD、RMSE等,图很多
代码中文注释清晰,质量极高,赠送测试数据集,可以直接运行源程序。替换你的数据即可用 适合新手小白
程序设计
- 完整代码私信回复GA-CNN-LSTM-Attention、CNN-LSTM-Attention、GA-CNN-LSTM、CNN-LSTM四模型多变量时序预测一键对比。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行%% 导入数据
result = xlsread('数据集.xlsx');%% 数据分析
num_samples = length(result); % 样本个数
kim = 2; % 延时步长(前面多行历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
nim = size(result, 2) - 1; % 原始数据的特征是数目%% 划分数据集
for i = 1: num_samples - kim - zim + 1res(i, :) = [reshape(result(i: i + kim - 1 + zim, 1: end - 1)', 1, ...(kim + zim) * nim), result(i + kim + zim - 1, end)];
end%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征长度%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, -1, 1);%将训练集和测试集的数据调整到0到1之间
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, -1, 1);% 对测试集数据做归一化
t_test = mapminmax('apply', T_test, ps_output);%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, f_, 1, 1, M));
p_test = double(reshape(p_test , f_, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test )';%% 数据格式转换
for i = 1 : MLp_train{i, 1} = p_train(:, :, 1, i);
endfor i = 1 : NLp_test{i, 1} = p_test( :, :, 1, i);
enddisp('----------运行CNN-LSTM模型----------');
%% CNN-LSTM参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/128577926?spm=1001.2014.3001.5501
[2] https://blog.csdn.net/kjm13182345320/article/details/128573597?spm=1001.2014.3001.5501