初二做网站的首页模板网站设计怎么做图片透明度
npm ERR! code EPERM npm ERR! syscall unlink npm ERR!错误解决方法
- 1、问题描述
- 2、解决方法
1、问题描述
由于之前电脑系统的原因,电脑重置了一下,之前安装的环境都没了,然后在重新安装node.js后在使用npm安装时总是报如下错误:
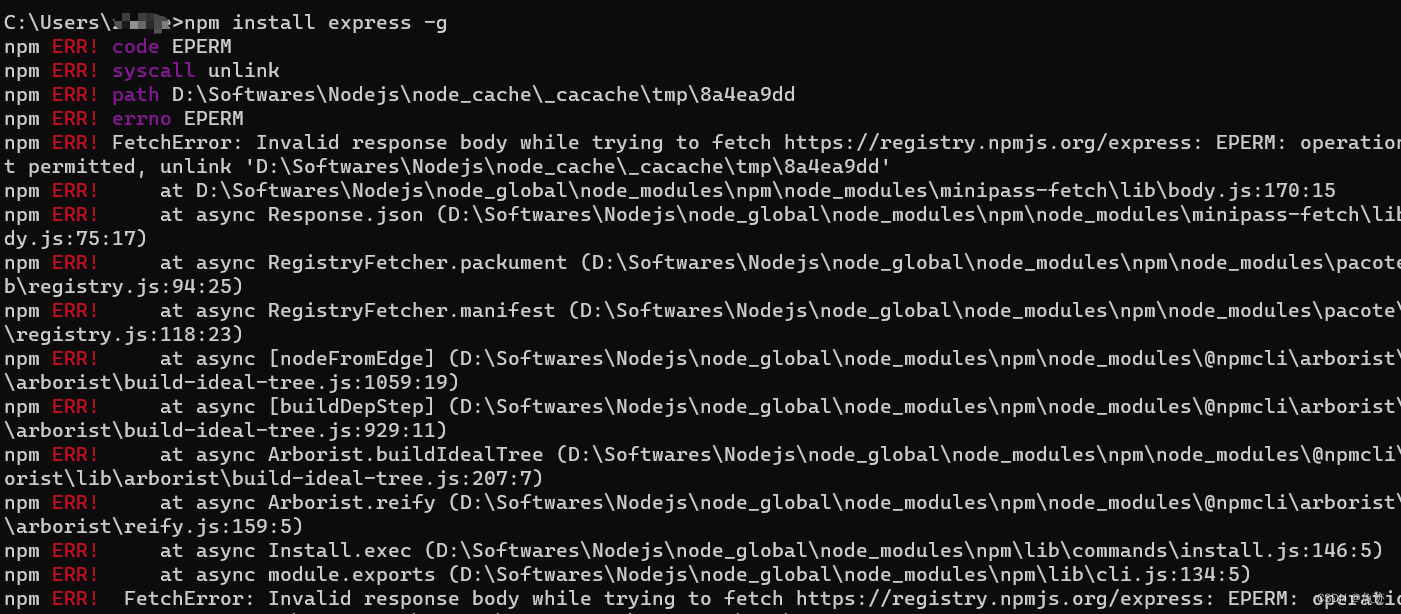
2、解决方法

这里的错误信息中,显示操作被操作系统拒绝,可能是因为文件正在使用中,或者缺少访问权限。所以我才用的方法是先查看node.js安装的文件夹所具有的权限,如下图所示:
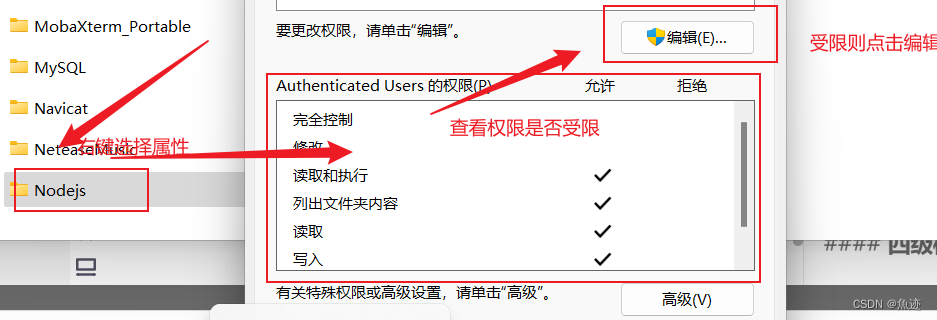
点击编辑后允许一列全选,然后点击应用,等待完成即可。
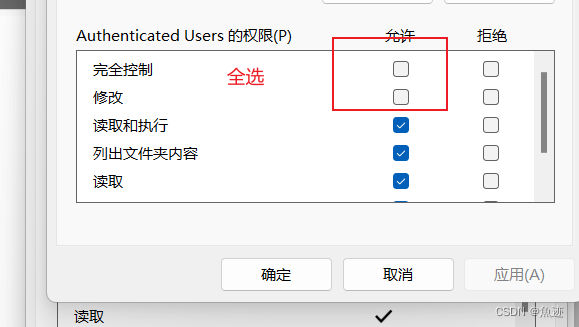
等待完成即可。
之后重新使用npm安装看能否成功。

这里可以看到能够成功安装,问题成功解决。