信丰网站建设微网站建设难不难
代码仓库:还没弄
目录
- 网站介绍
- 安装步骤
- 1. 准备云服务器
- 2. 准备域名(可跳过)
- 3. 安装1panel面板
- 4. 服务器开放端口
- 5. 进入1panel面板
- 6. 安装并启动软件(服务器和面板开放端口)
- 7. 打包并上传项目
- 7.1 打包 Java项目(springboot )项目并上传(端口我设置的是9090)
- 7.2 打包 vue 项目并上传(端口我设置的是8200)
- 8. 上传 并 创建Java运行环境(服务器和面板开放端口)
- 9. 上传 并 添加网站 - 静态网站(vue)(服务器和面板开放端口)
- 10. 数据库配置
- 11. 修改项目里的数据库配置 并 重启Java服务
- 12. 刷新对应网站,即可访问
网站介绍
仿照别人项目做了个基于 springboot 和 vue 的网站,在腾讯云服务器上,通过 宝塔面板 部署了该项目。
项目的技术栈:Vue3、Vite5、Axios、Element Plus、Wangeditor5、Highlightjs、Spring Boot2、Mybatis、MySQL8
安装步骤
1. 准备云服务器
买一个低配置的云服务器就行,哪家的都行
选择常见linux的发型版本,centos、debian、ubuntu 啥的都行
2. 准备域名(可跳过)
买个普通的域名,并接上服务器
国内域名需要备案,尽量写:个人学习项目,这样容易过
3. 安装1panel面板
前往1panel官网,准备安装
https://repository-proxy.fit2cloud.com/1panel/index.html
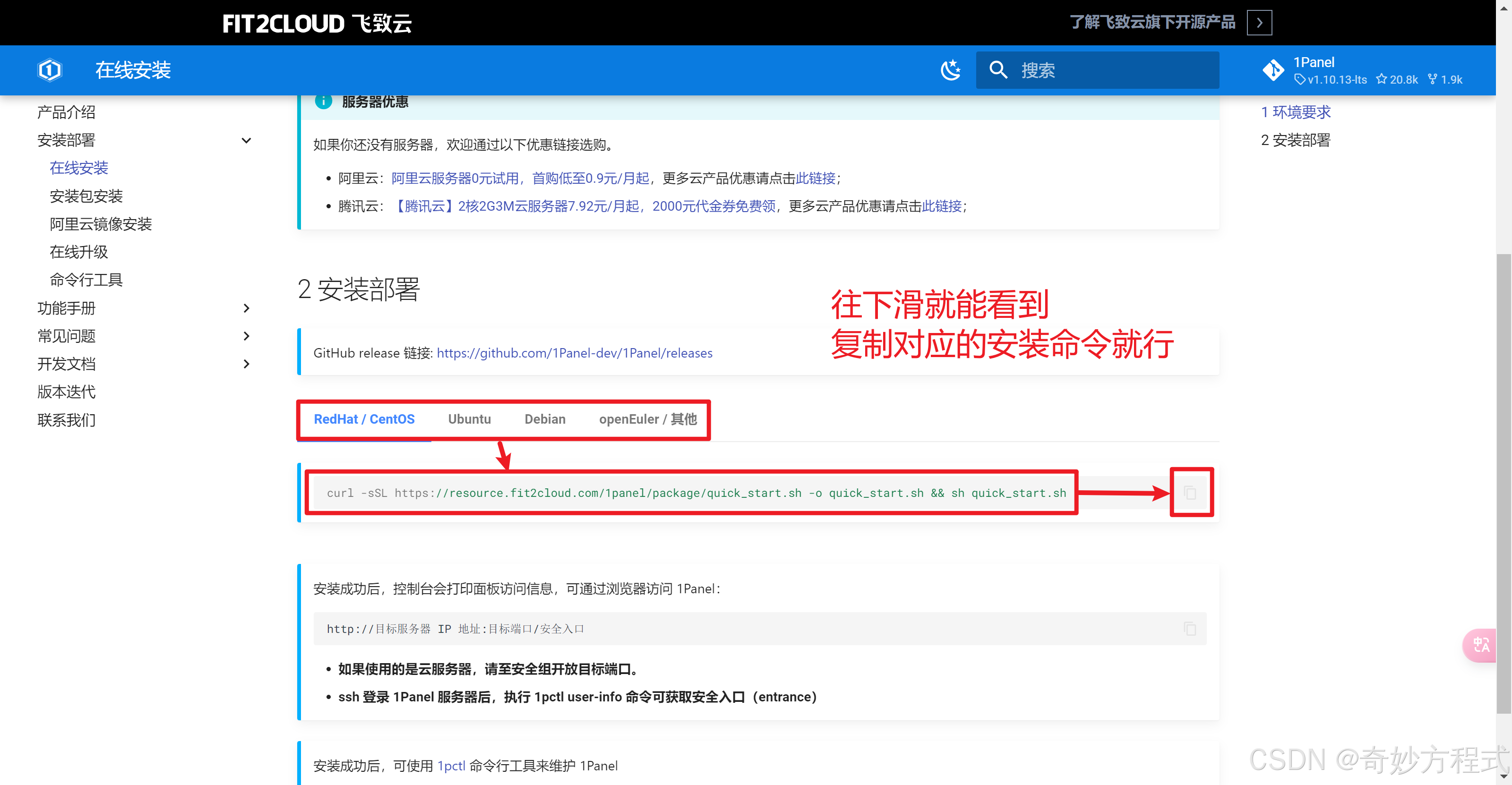
进入云服务器控制台,登录终端,并切换到root用户,再粘贴安装命令,进行安装
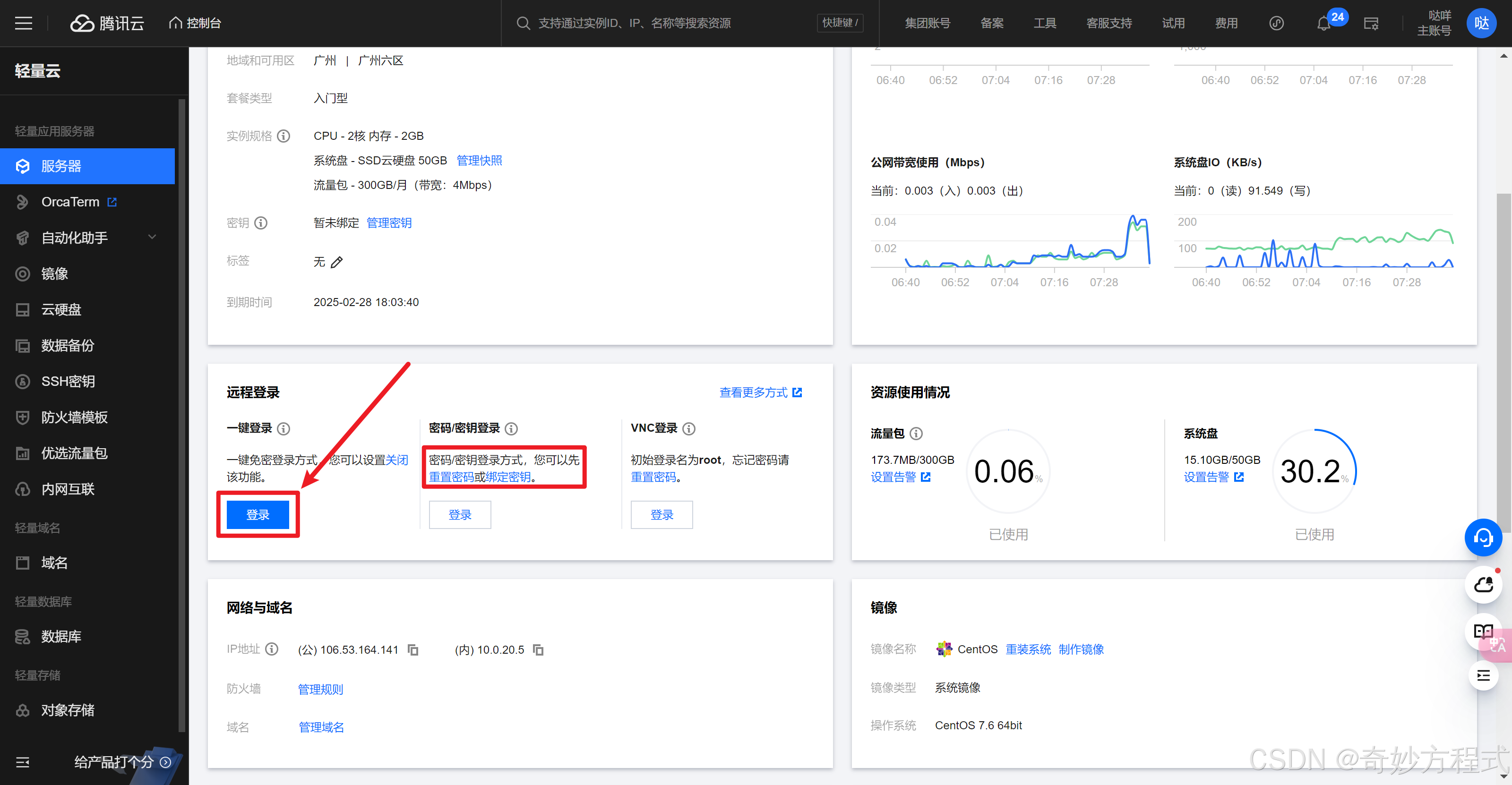
密码要是不知道or忘了,可去云服务器重置密码(上图红框处)
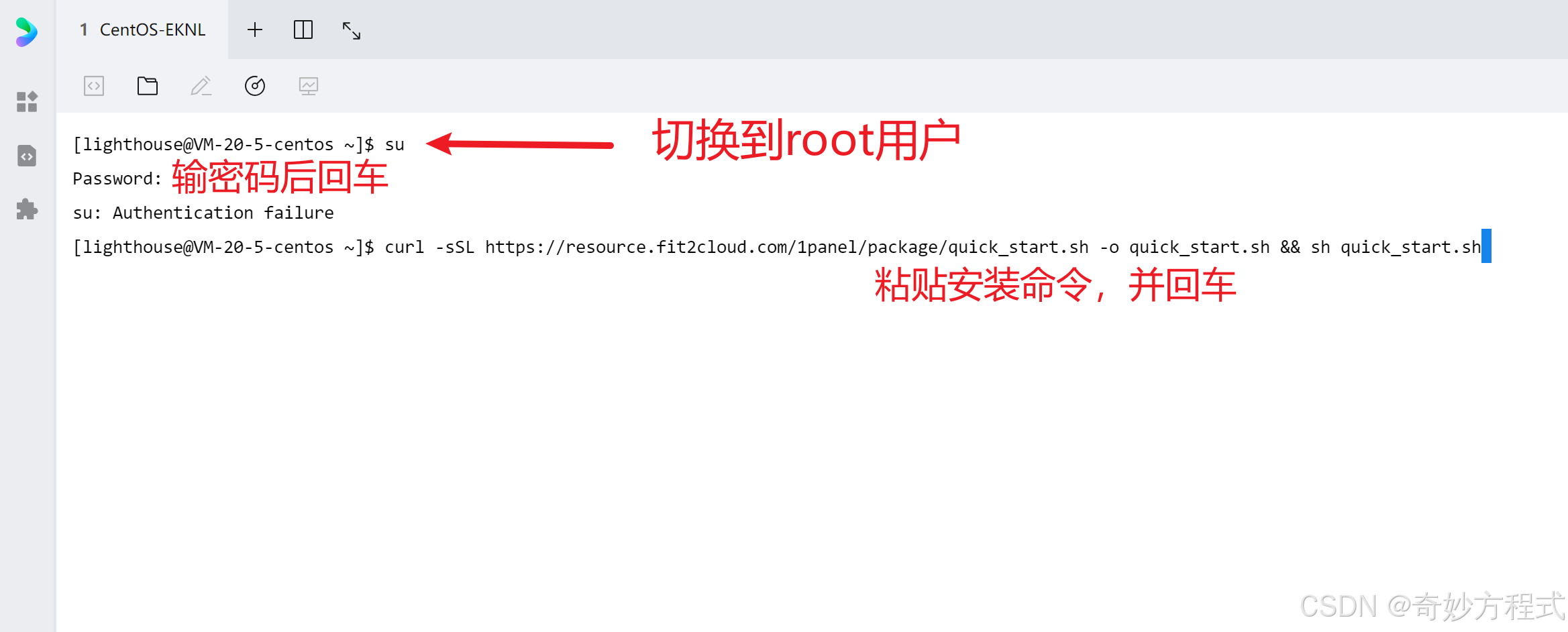
等待安装完成(约几分钟)
期间会要求配置一些选项,如文件保存路径、面板端口号、面板登录账号和密码
建议修改成好记忆的,当然也可以无脑回车按默认的来。不过不论如何,都建议保存到某个文件中,以防忘记。
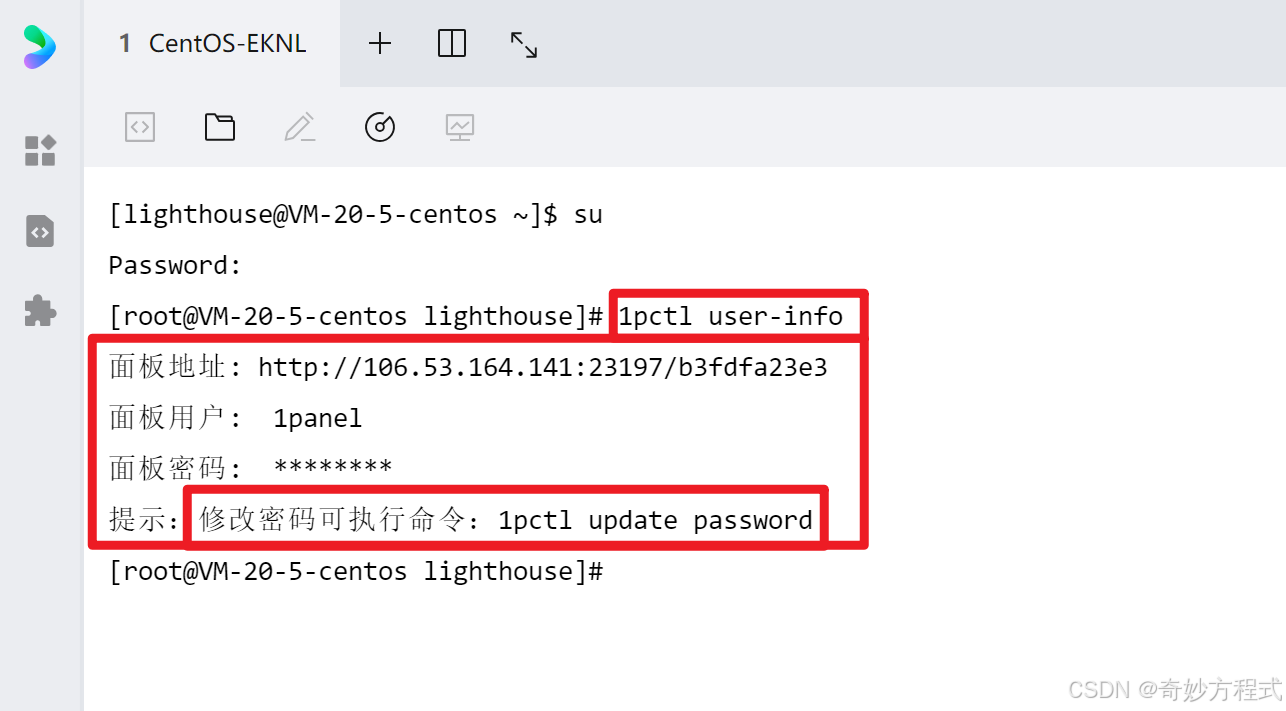
如果你忘了面板信息也没事,登录终端,切换到root用户,输入以下命令
1pctl user-info
即可查看
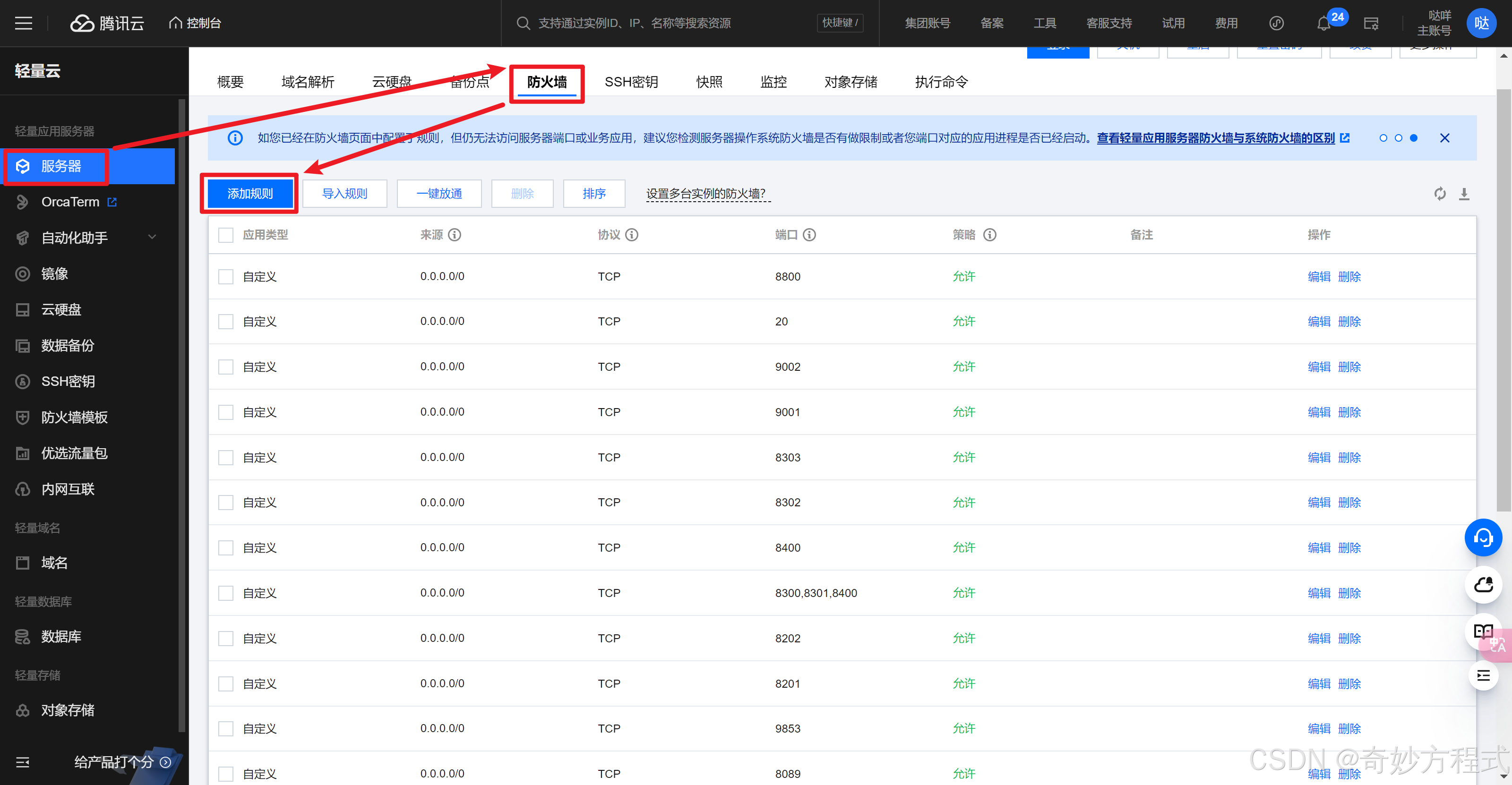
4. 服务器开放端口
上面设置的端口号(假定是22),要在服务器那开放端口
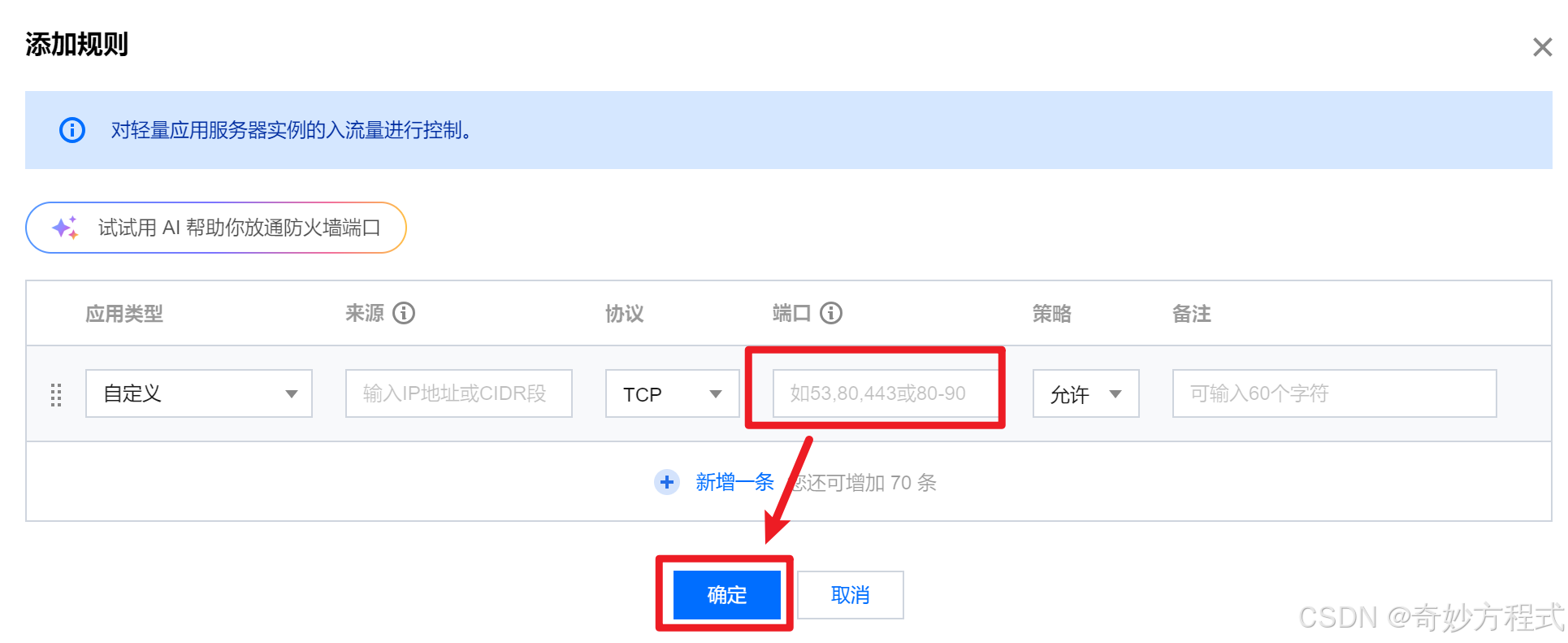
写入22(假定是),然后保存
5. 进入1panel面板
访问面板地址,并输入用户名和密码。登录前后还需要同意协议

6. 安装并启动软件(服务器和面板开放端口)
先配置镜像加速,否则可能会安装失败
应用商店 - 已安装 - 快速跳转 - 镜像加速 - 设置
https://docker.1panel.live
https://ghcr.nju.edu.cn
https://docker.nju.edu.cn
返回应用商店 - 安装 OpenResty、MySQL、phpMyAdmin 这三款软件,并启动
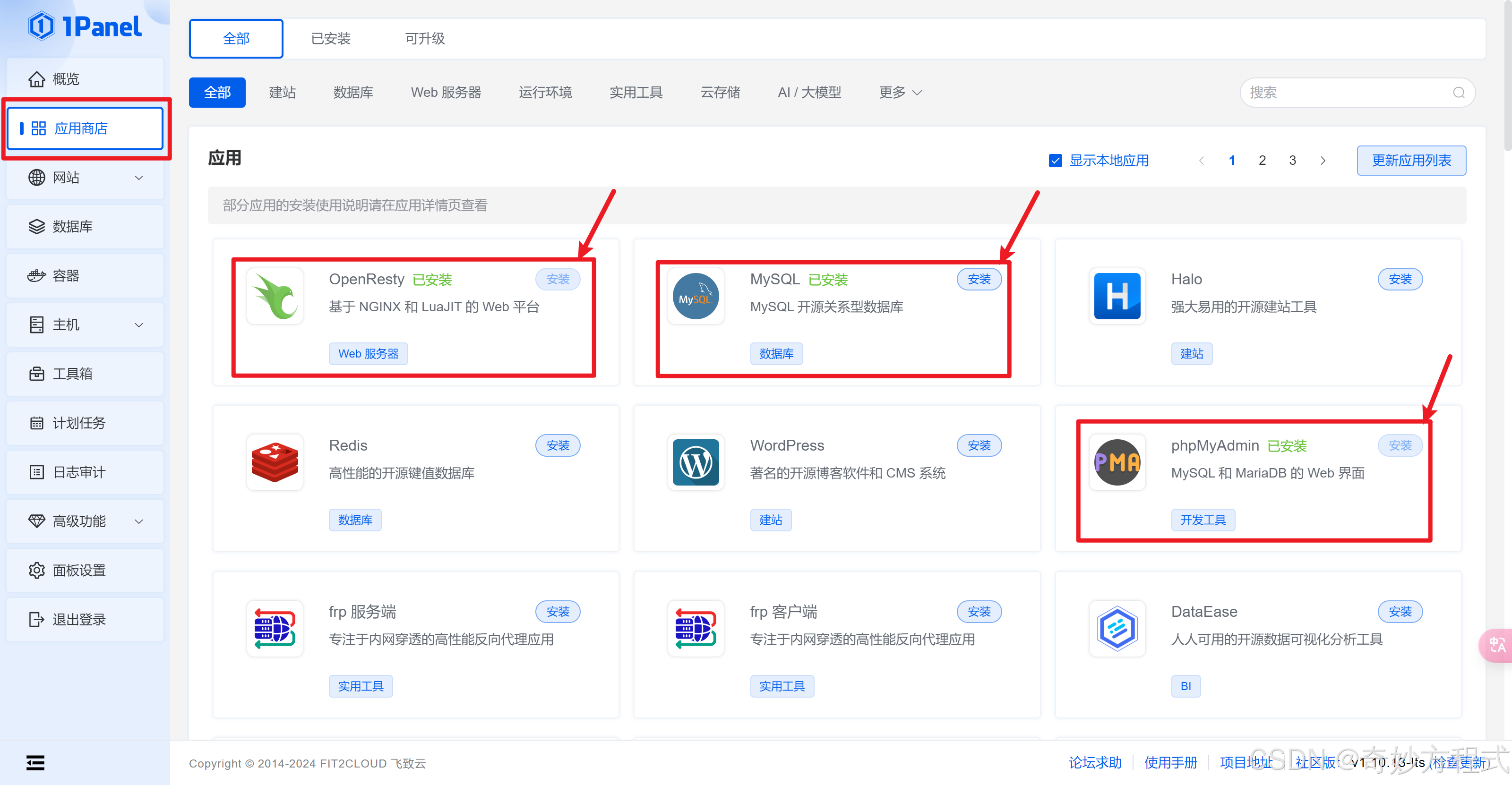
可在 应用商店 - 已安装 - 查看各软件的端口,并在 云服务器 和 面板中开放该端口
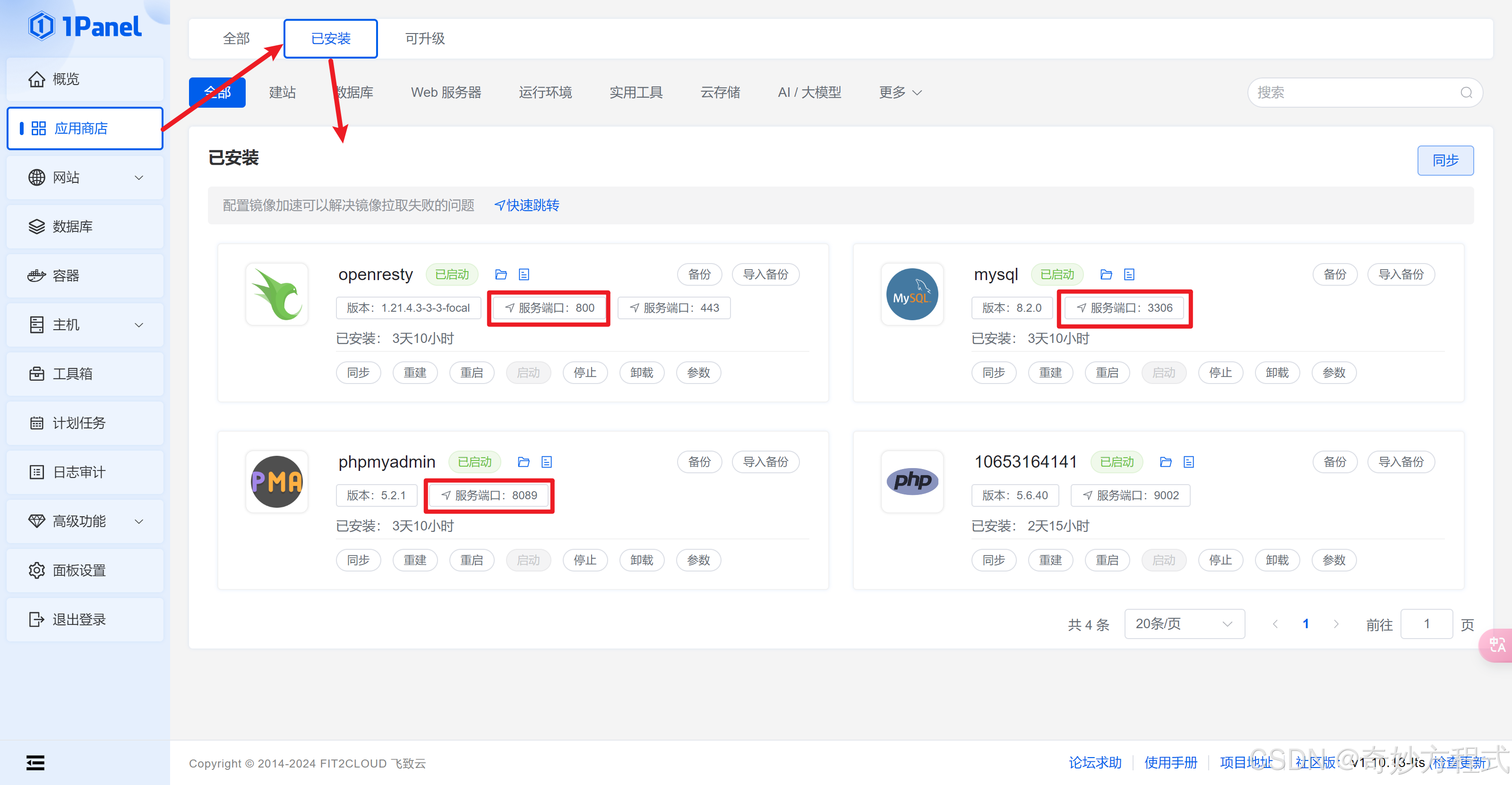
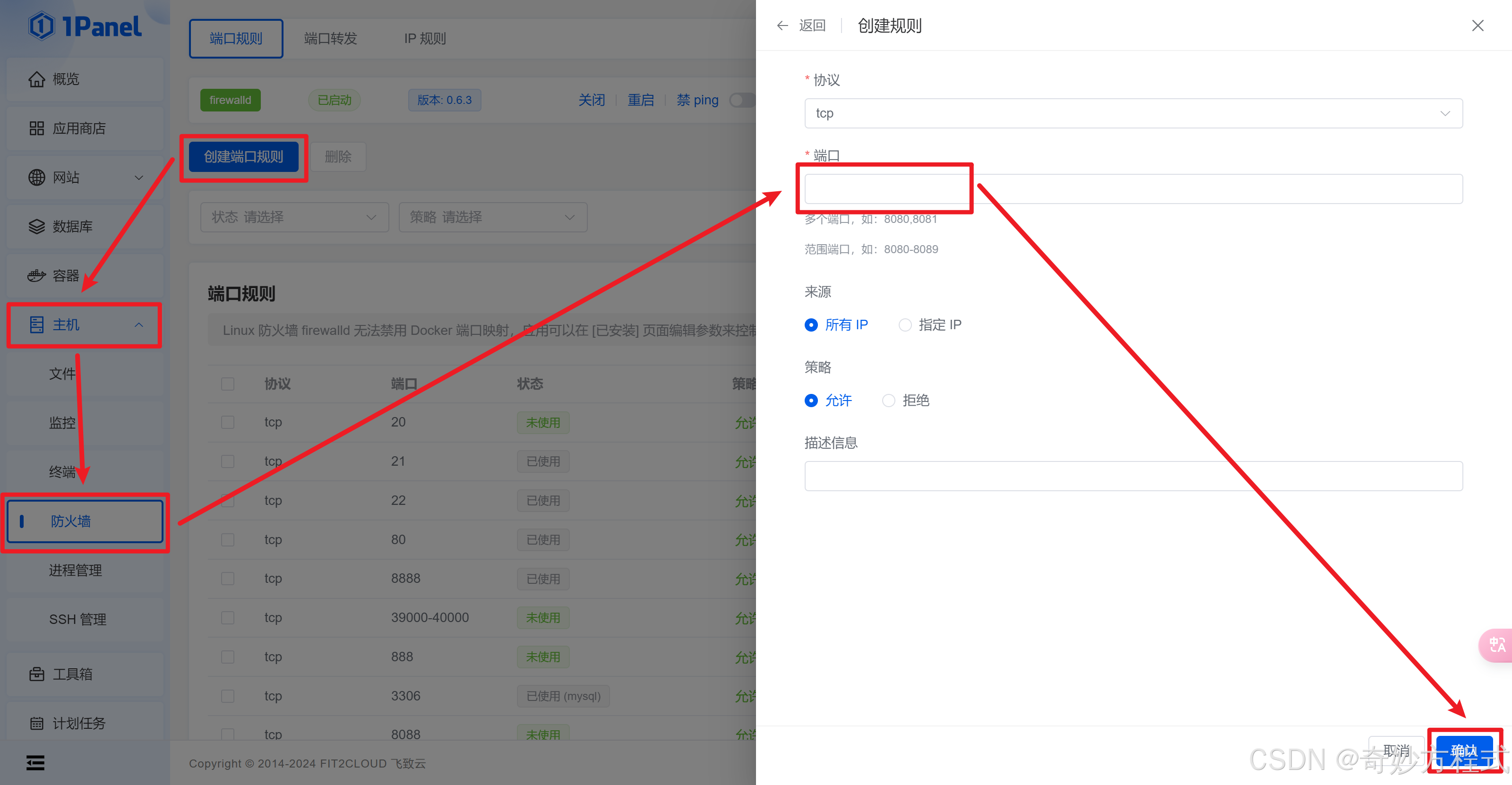
在服务器开放端口
在面板开放端口
主机 - 防火墙 - 创建端口规则
7. 打包并上传项目
7.1 打包 Java项目(springboot )项目并上传(端口我设置的是9090)
点击 m(maven) - 双击package,等待片刻,即可完成打包,最终是打包成了jar或者war文件

之后上传到面板文件
7.2 打包 vue 项目并上传(端口我设置的是8200)
修改后端端口(改成服务器的)

vscode软件 - NPM脚本 - build ,最后生成的是一个dist文件夹

之后上传到面板文件
8. 上传 并 创建Java运行环境(服务器和面板开放端口)
把 jar包之类的东西上传到面板文件中
网站 - 运行环境 - Java - 创建运行环境
运行目录 - 选中到 jar包
启动命令:java -jar xxx.jar (xxx,jar改成你自己jar包的名字)
端口号自己设置一下(可以设置成一样的),我这里设置的是9090

服务器和面板记得开放端口,前面说过方法,这里不重复
9. 上传 并 添加网站 - 静态网站(vue)(服务器和面板开放端口)
网站 - 网站 - 创建环境 - 静态网站
主域名处写下域名和端口就行,比如我写的是:106.53.164.141:8200
代号(就是网站目录的名称)自行设置
之后进入网站目录,把 dist文件夹上传上来

点进去刚刚设置的网站 - 网站目录 - 运行目录选择 /dist - 保存并重载
同时确保 root目录 选到的是 index文件夹(不是的话重选)

点击配置文件,把下面的代码加进去并保存
location / {try_files $uri $uri/ /index.html last; index index.html;
}

服务器和面板记得开放端口,前面说过方法,这里不重复
10. 数据库配置
先确保 mysql 和 phpMyAdmin 这两个端口号都开放
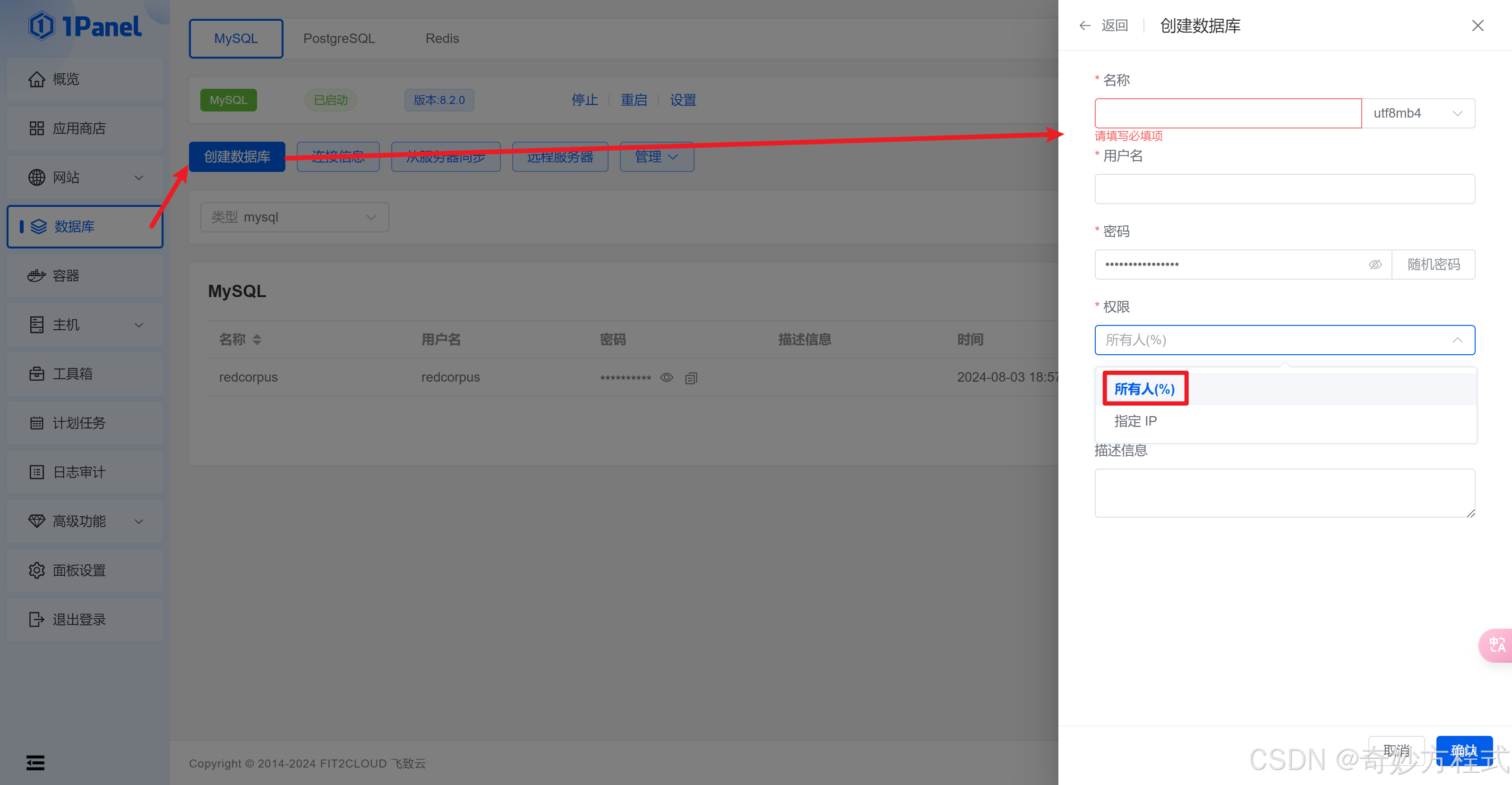
数据库 - 新建数据库
按自己项目情况来填写
权限改为所有人
管理 - phpMyAdmin - 进入web端musql管理工具
选择数据库 - 导入 - 上传文件
选择sql文件并上传

向下滑动,点击执行
11. 修改项目里的数据库配置 并 重启Java服务
之后修改一下项目里的数据库配置并保存

修改配置后,需要重启Java项目

12. 刷新对应网站,即可访问

