项目网评ppt优化一个网站
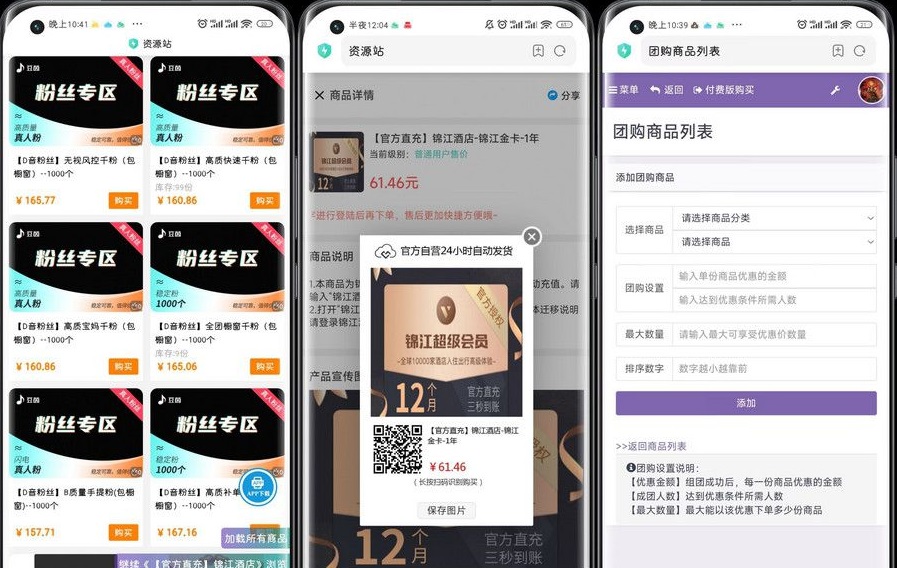
最新彩虹知识付费商城源码 V3.4,支持二级分类,多级分销,秒杀,砍价,团购,首页继续浏览,分站个人虚拟余额自定义,最新批量对接,批量下载图片,批量替换标题,详情关键词替换,商品去重,商品活码,分站活码,插件市场,后台教程。后台一键更新,而且是免授权版本,非常良心,有稳定的技术维护,自带4000+货源数据,秒速上货,搭建即可运营。
下载地址:极速云
最新彩虹知识付费商城源码 V3.4,支持二级分类,多级分销,秒杀,砍价,团购,首页继续浏览,分站个人虚拟余额自定义,最新批量对接,批量下载图片,批量替换标题,详情关键词替换,商品去重,商品活码,分站活码,插件市场,后台教程。后台一键更新,而且是免授权版本,非常良心,有稳定的技术维护,自带4000+货源数据,秒速上货,搭建即可运营。
下载地址:极速云