终身免费建站新乡网站设计公司
一、项目背景
制作小程序页面时候发现原生导航栏有一定的高度是没有背景渲染的会出现这种情况

但是我们需要的是

二、原因
小程序的原生导航栏存在。一般可以使用 纯色填充顶部栏
可以直接使用navigationBarBackgroundColor完成
在style中添加 "navigationBarBackgroundColor": "#FED000"
但是业务需求需要添加自定义的效果,例如一整张背景图纯色填充
三、自定义导航栏的使用

黄色部分为状态栏高度 uni.getSystemInfoSync().statusBarHeight;

红色部分为自定义导航栏高度。wx.getMenuButtonBoundingClientRect
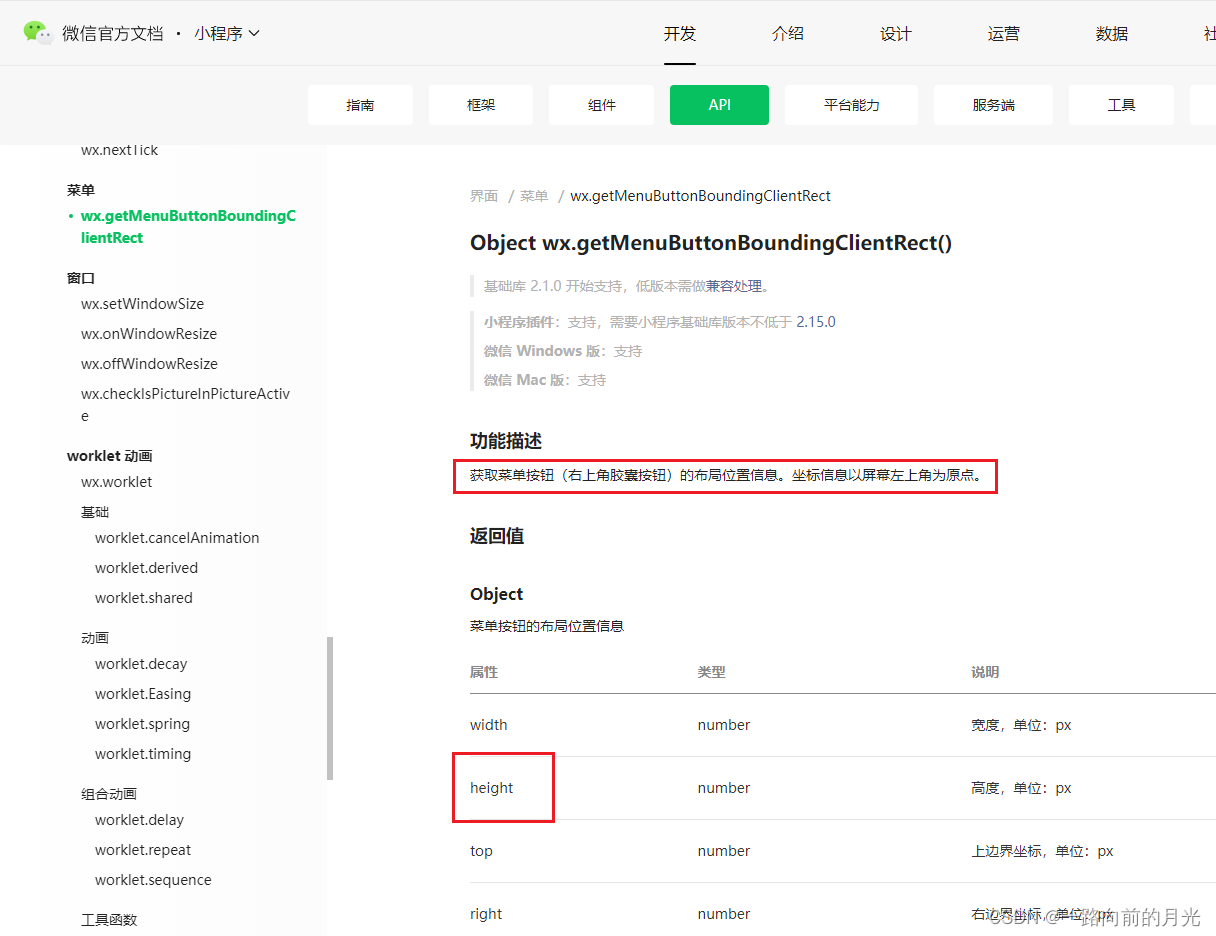
在页面onload时候就可以计算出相关高度了
onLoad() {// 状态栏高度this.statusBarHeight = uni.getSystemInfoSync().statusBarHeight; // 胶囊数据const { top, height } = wx.getMenuButtonBoundingClientRect();// 自定义导航栏高度 = 胶囊高度 + 胶囊的padding*2, 如果获取不到设置为38this.barHeight = height ? height + (top - this.statusBarHeight) * 2 : 38;
}, <!-- 状态栏高度 --><view :style="{ height: `${statusBarHeight}px` }"></view><!-- 自定义导航栏高度 并 居中 --><view :style="{height: `${barHeight}px`,'line-height': `${barHeight}px`,'text-align': 'center',}"><text>自定义标题</text></view>