seo关于网站搜索排名网站建设优化服务多少钱
离线英文评测算法SDK
能力简介
CSK6 大模型开发套件可以对用户通过语音输入的英文单词进行精准识别,并对单词的发音、错读、漏读、多读等方面进行评估,进行音素级的识别,根据用户的发音给出相应的建议和纠正,帮助用户更好地掌握单词的发音。
离线单词评测 算法具备以下特性:
- 支持单词评测,评测准确率98%以上
- 支持音素级识别
- 支持单词发音评分
- 支持识别无效评测音频
功能交互展示
视觉语音大模型AI开发套件SDK 配套了离线英文评测这一示例工程,文本将对本示例工程进行说明。
1.固件运行后,可以在显示屏上看到 单词评测 的图标,点击图标即可进入单词评测应用:
2.目前固件提供了三种单词、短语、句子评测模式,点击对应选项课进入对应的模式:

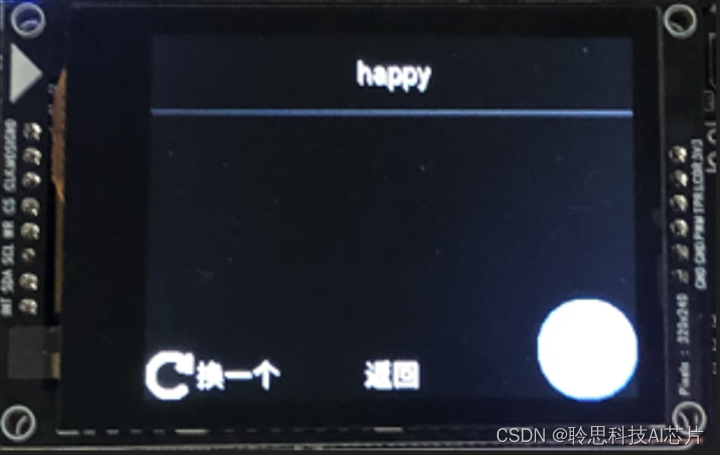
3.以单词评测为例,进入该模式后,固件将给出若干个英文单词,可点击右下角评测按钮进行评测:
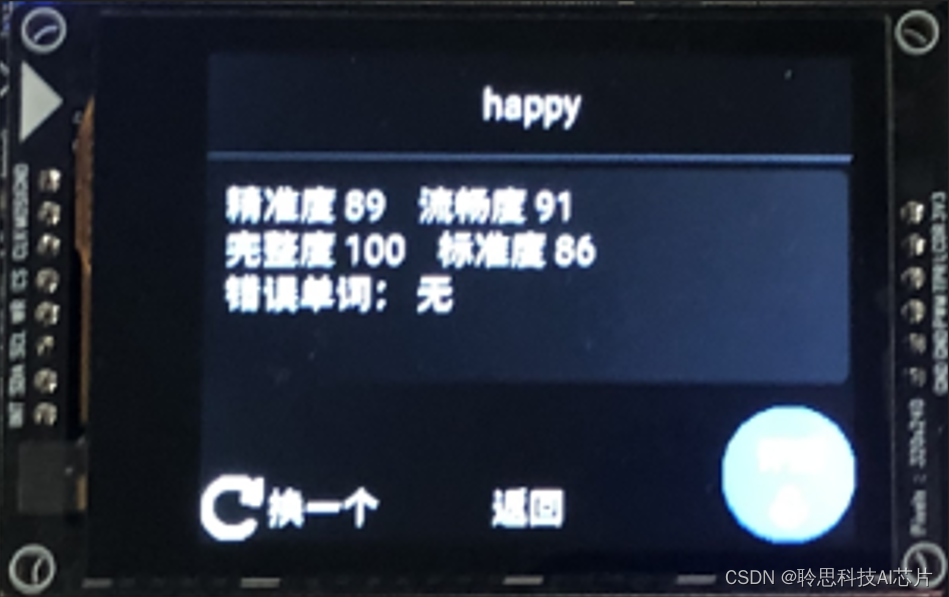
4.对着开发套件读出单词后,点击右下角图标结束评测,固件将给出此次评测的结果:
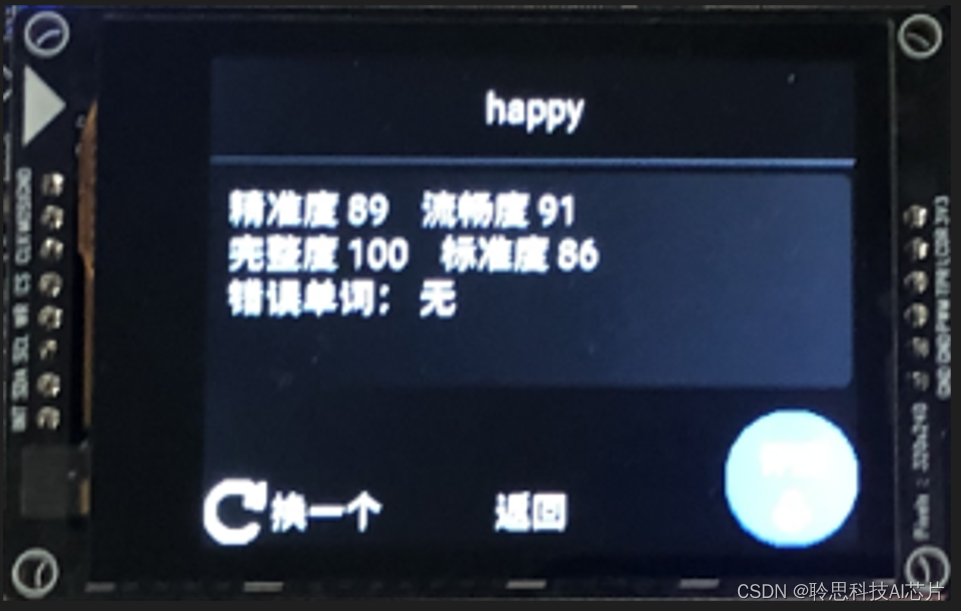
离线英译中SDK

能力简介
基于transformer模型,使用聆思科技开源的AI生态工具链LNN(ListenAI Neural Network),完成中英翻译任务的训练、量化、模型转换、仿真调试等一系列步骤,并实现在聆思CSK6芯片上进行推理。
SDK提供的示例集成了这个模型,可以让聆思CSK6开发板实现英译中功能,可用于体验离线翻译功能。
触摸屏UI交互翻译
固件烧录完毕后,程序将自动运行,您也可以通过复位按键(RST)对程序进行复位,复位后的UI界面如下:

- 点击画面中心的输入框,可通过屏幕上显示的键盘输入句子
- 点击输入框左侧的按钮,可随机填入一句演示的句子
- 点击下方翻译按钮,即可输出改句子的中文翻译
UART串口交互翻译
本示例也支持通过串口 UART 进行离线翻译,操作如下:
- 打开 聆思在线串口终端,选择开发板对应的串口,点击连接
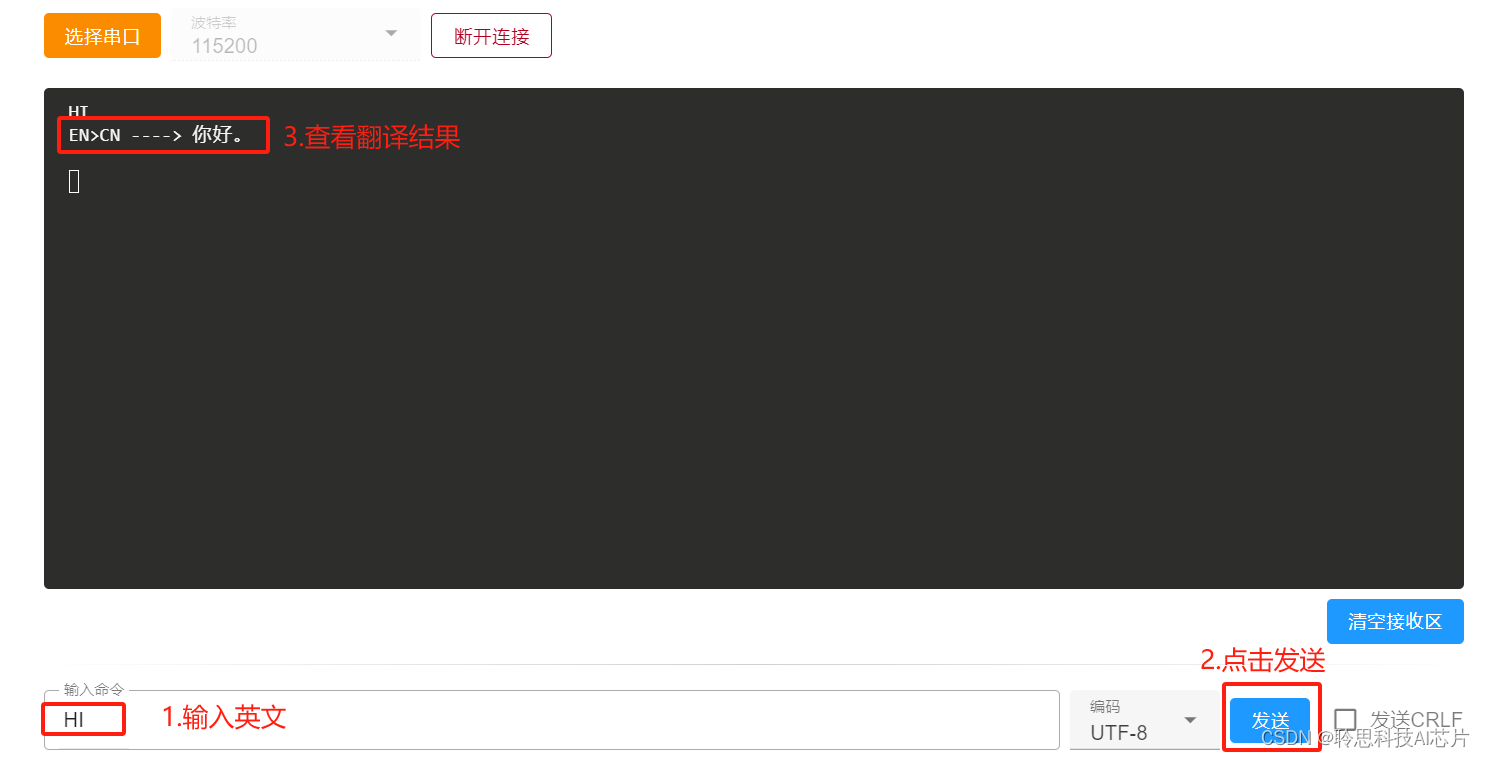
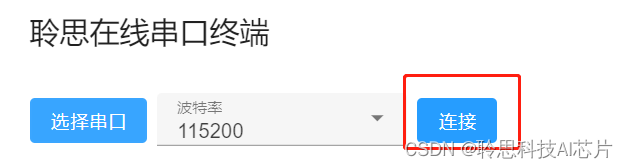 在下方输入框输入待翻译的英文内容,点击发送按钮,即可在接收区查看到翻译后的中文结果。
在下方输入框输入待翻译的英文内容,点击发送按钮,即可在接收区查看到翻译后的中文结果。
离线字母拼读算法SDK
能力简介
CSK6 大模型开发套件可以对用户的语音输入进行字母(a~z)的识别,通过语音拼读单词字母,快速准确地查询单词的发音和含义,可应用于扫描词典笔、单词卡、学习机等产品。
可以对用户的语音输入进行字母(a~z)的识别,通过语音拼读单词字母,快速准确地查询单词的发音和含义。
功能交互展示
聆思 CSK6 大模型开发套件出厂集成提供了字母拼读算法的示例,长按即可加载示例进行使用,无需联网。
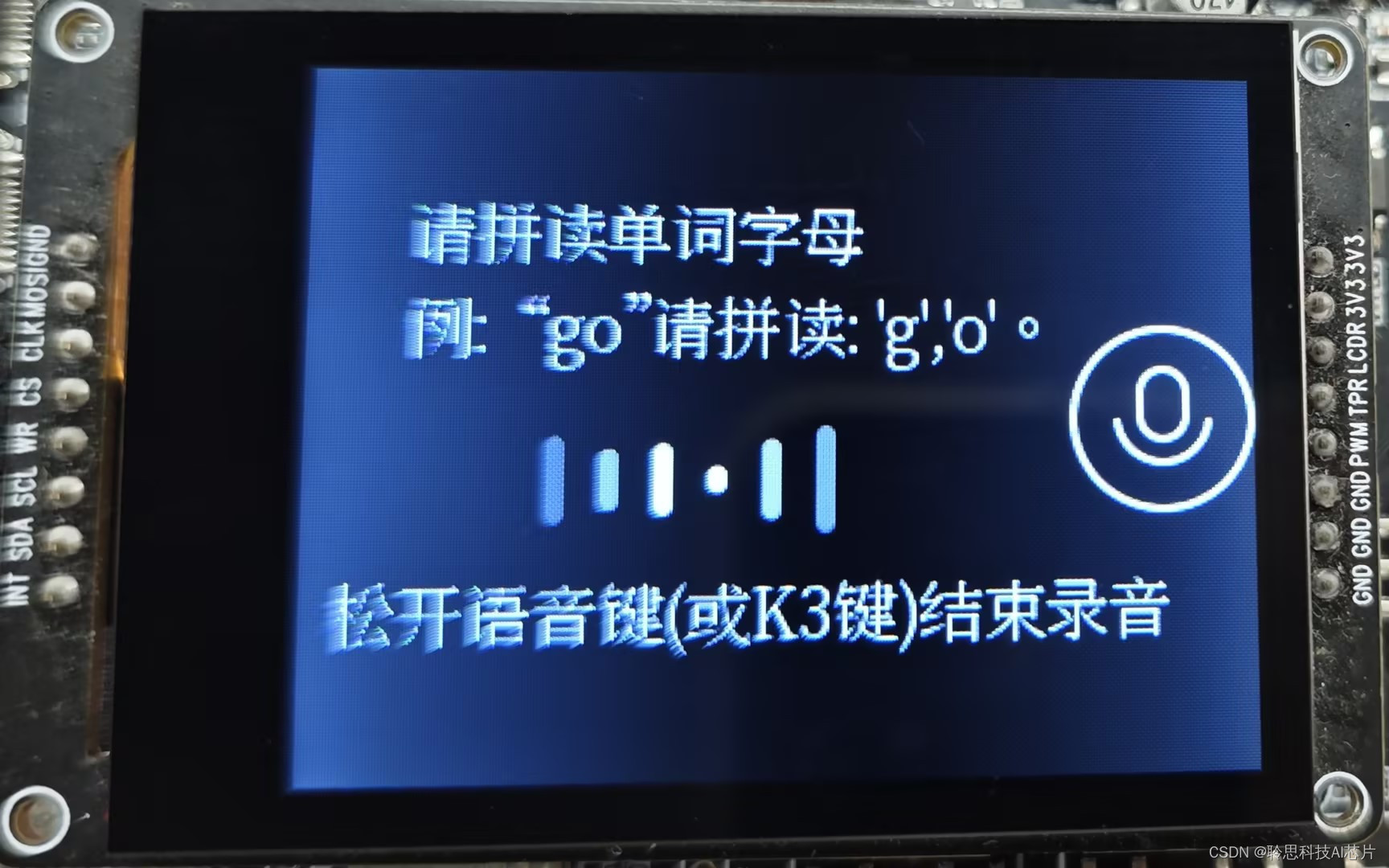
1.固件运行后,可以在显示屏上看到操作提示词:

2.按住按键进行单词拼读:
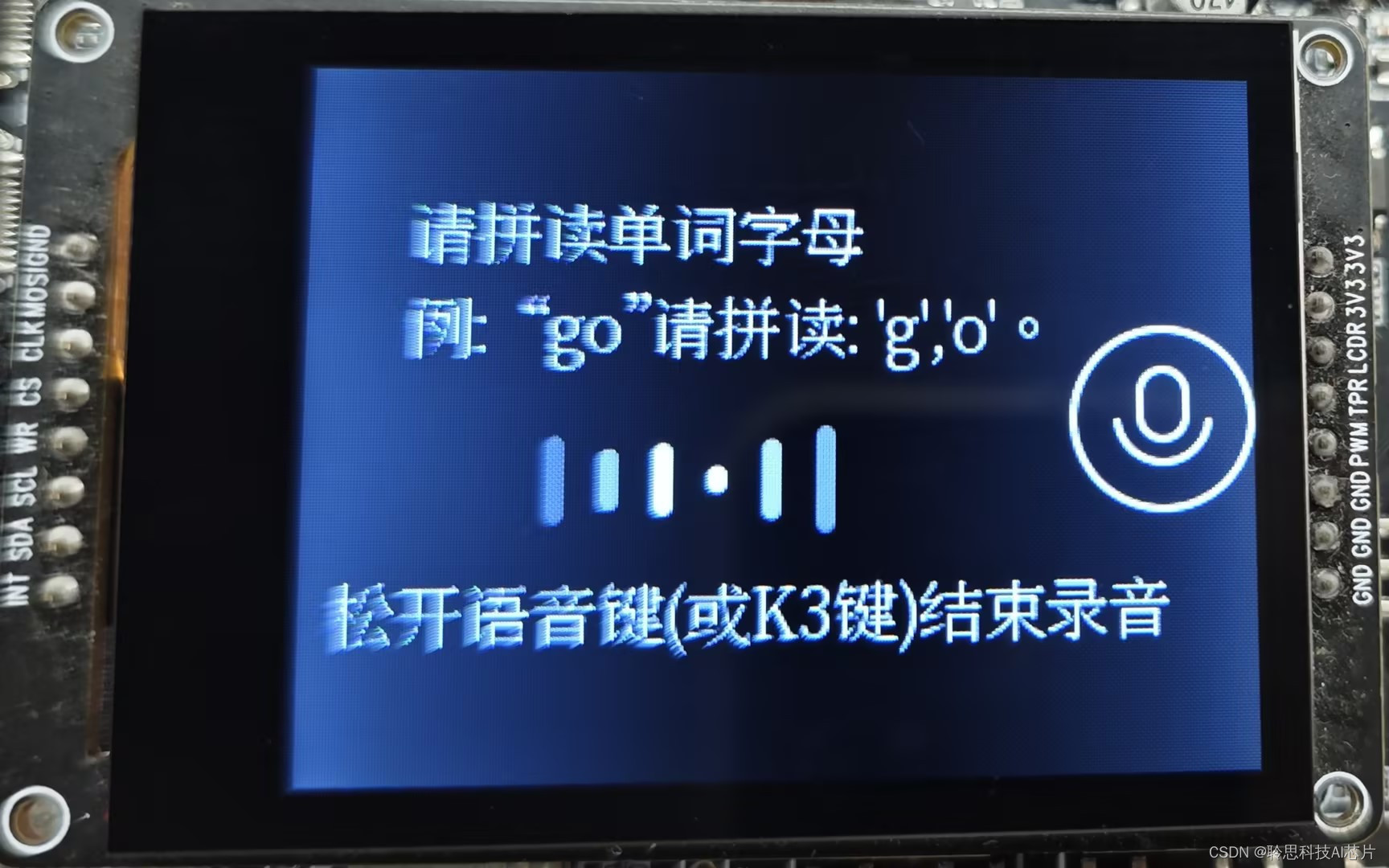
3.拼读完成后,固件将会给出单词的发音和含义:

SDK资源下载
以上3个离线英语评测SDK可以在以下地址下载:
1、 语音视觉大模型开发板 SDK:https://cloud.listenai.com/CSKG962172/duomotai_ap/-/tree/master/
-
字母拼读:apps目录下,工程目录名称为 lcd_wsp
-
英文评测: apps目录下,工程目录名称为 lcd_csps
-
英译中: apps/thinker_service目录下,工程目录名称为 translation
2、离线英译中transformer模型项目地址:GitHub - dwzhang00/Offline-translation: An offline translation model based on transformer
补充开发板信息

开发板具备丰富语音图像功能与硬件外设的开发板,采用有着丰富组件生态的 Zephyr RTOS 作为操作系统,默认配套开箱即玩的 AI 应用,也可以配合聆思的模型训练推理工具 LNN 将自己的算法模型部署至芯片上,构建自己的 AI 应用,开发板详情参考:https://docs2.listenai.com/x/nTn9kMMCU