个人建设网站盈利需要什么材料网站如何做浮窗
1.发布商品流程

发布商品分为5个步骤:
- 基本信息
- 规格参数
- 销售属性
- SKU信息
- 保存完成
2.发布商品-基本信息
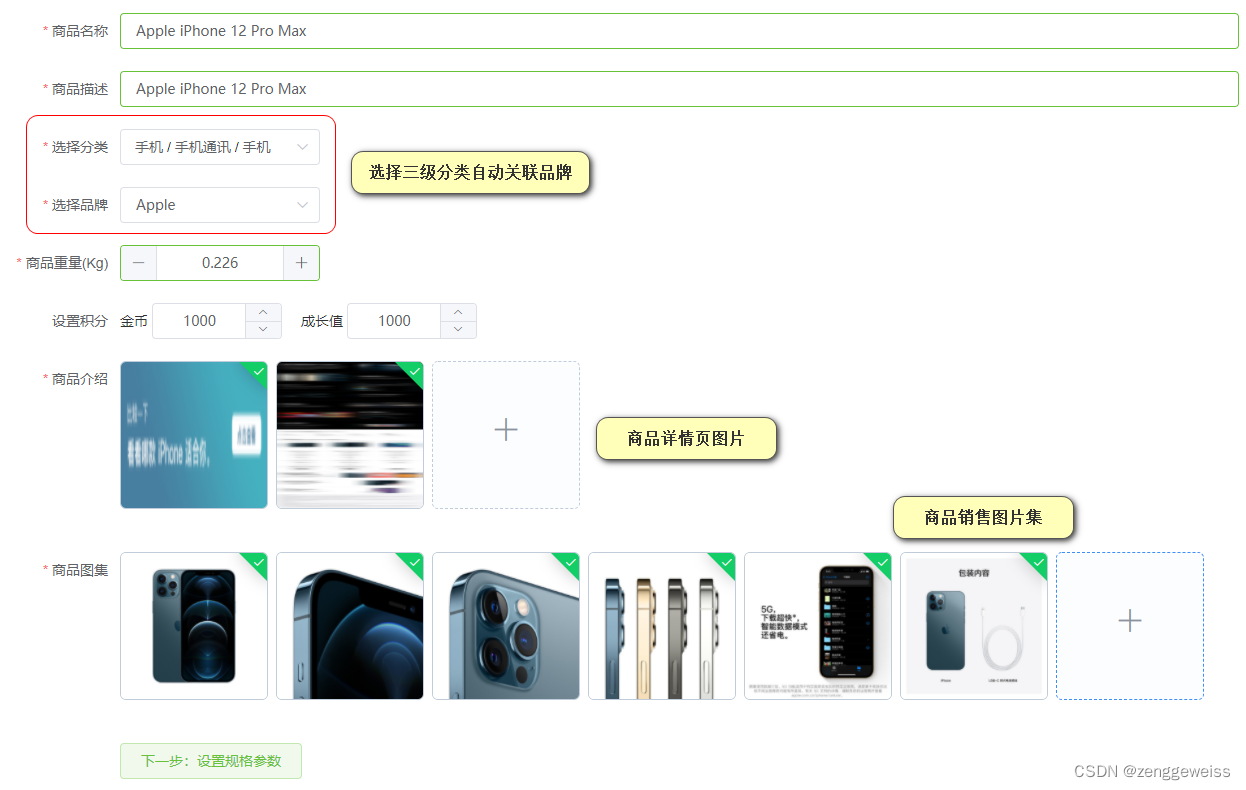
2.1.会员等级-会员服务
2.1.1.会员服务-网关配置
在网关增加会员服务的路由配置
- id: member_routeuri: lb://gmall-memberpredicates:- Path=/api/member/**filters:- RewritePath=/api/(?<segment>.*), /$\{segment}
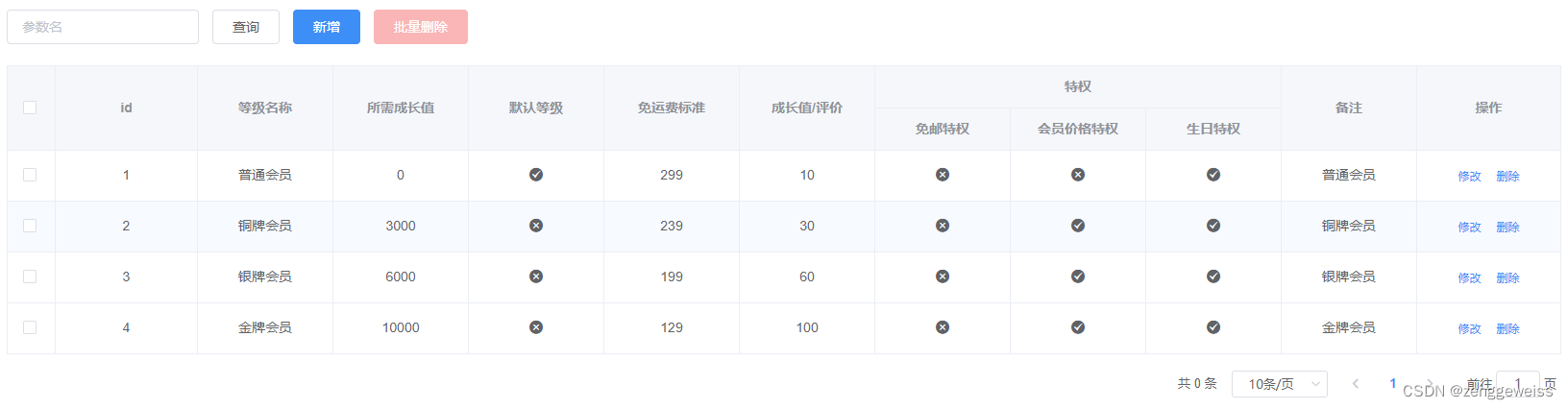
2.1.2.新增会员等级
菜单路径:用户系统 -> 会员等级
2.2.获取分类关联的品牌
2.2.1.API
GET /product/categorybrandrelation/brands/list// 请求参数
{"catId": 255}// 响应数据
{"msg": "success","code": 0,"data": [{"brandId": 0,"brandName": "string",}]
}
2.2.2.后台接口实现
CategoryBrandRelationController
/*** 获取分类关联的品牌* @param catId 分类ID* @return*/@GetMapping("/brands/list")public R brandRelationList(@RequestParam(value = "catId", required = true) Long catId) {List<BrandEntity> brandEntities = categoryBrandRelationService.getBrandsByCatId(catId);List<BrandVO> vos = brandEntities.stream().map(brandEntity -> {BrandVO brandVO = new BrandVO();brandVO.setBrandId(brandEntity.getBrandId());brandVO.setBrandName(brandEntity.getName());return brandVO;}).collect(Collectors.toList());return R.ok().put("data", vos);}
CategoryBrandRelationServiceImpl
/*** 获取分类关联的品牌* @param catId 分类ID* @return 当前分类下的品牌*/@Overridepublic List<BrandEntity> getBrandsByCatId(Long catId) {List<CategoryBrandRelationEntity> categoryBrandRelationEntities = categoryBrandRelationDao.selectList(new QueryWrapper<CategoryBrandRelationEntity>().eq("catelog_id", catId));List<BrandEntity> brandEntities = categoryBrandRelationEntities.stream().map(categoryBrandRelationEntity -> {return brandDao.selectById(categoryBrandRelationEntity.getBrandId());}).collect(Collectors.toList());return brandEntities;}
3.发布商品-规格参数
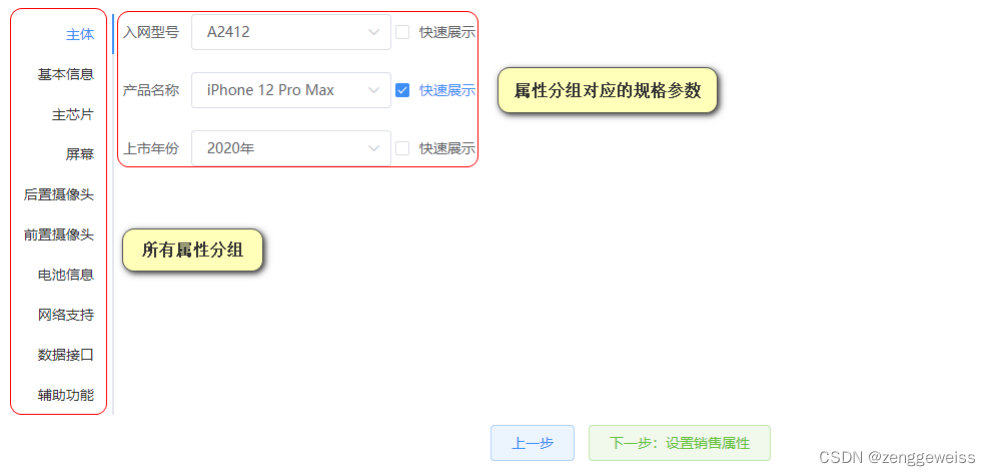
3.1.获取分类下所有分组&关联属性
3.1.1.API
GET /product/attrgroup/{catelogId}/withattr
3.1.2.后台接口实现
AttrGroupController
/*** 获取分类下所有分组及关联的所有属性* @return*/@GetMapping("/{catelogId}/withattr")public R getAttrGroupWithAttrs(@PathVariable("catelogId") Long catelogId) {List<AttrGroupWithAttrsVO> vos = attrGroupService.getAttrGroupWithAttrsByCatelogId(catelogId);return R.ok().put("data", vos);}
AttrGroupServiceImpl
/*** 获取分类下所有分组及关联的所有属性* @param catelogId 三级分类ID* @return 分组及关联的所有属性集合*/@Overridepublic List<AttrGroupWithAttrsVO> getAttrGroupWithAttrsByCatelogId(Long catelogId) {// 获取分类的所有属性分组List<AttrGroupEntity> attrGroupEntities = this.list(new QueryWrapper<AttrGroupEntity>().eq("catelog_id", catelogId));List<AttrGroupWithAttrsVO> attrGroupWithAttrsVOs = attrGroupEntities.stream().map(attrGroupEntity -> {AttrGroupWithAttrsVO attrGroupWithAttrsVO = new AttrGroupWithAttrsVO();BeanUtils.copyProperties(attrGroupEntity,attrGroupWithAttrsVO);// 获取分组的所有属性List<AttrEntity> attrEntities = attrGroupService.getAttrRelation(attrGroupWithAttrsVO.getAttrGroupId());attrGroupWithAttrsVO.setAttrs(attrEntities);return attrGroupWithAttrsVO;}).collect(Collectors.toList());return attrGroupWithAttrsVOs;}
4.发布商品-销售属性
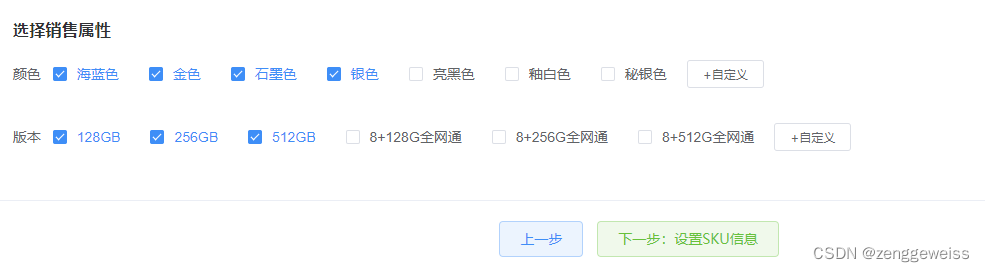
根据选择的颜色和版本,生成SKU销售信息 = 颜色数量 * 版本数量
5.发布商品-SKU信息
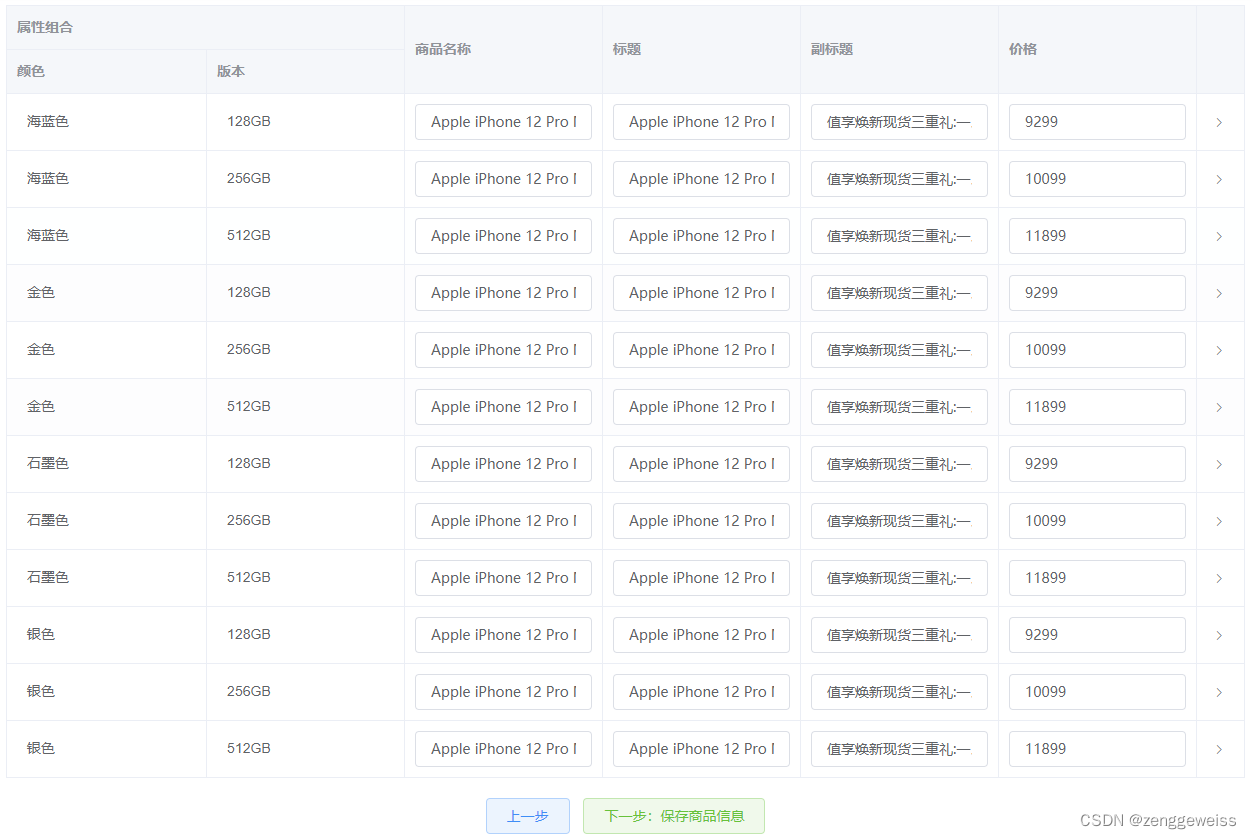
6.发布商品-保存完成
6.1.API
POST /product/spuinfo/save
6.2.抽取VO对象
保存发布商品时,根据前端生成的json,需要生成对应的 VO 对象
- SpuVO
- Bounds
- BaseAttrs
- Skus
- Attr
- Images
- MemberPrice
6.3.远程接口
6.3.1.TO 对象
SpuBoundTO
package com.atguigu.common.to;import lombok.Data;import java.math.BigDecimal;/*** SPU会员积分信息远程服务传输对象 {@link SpuBoundTO}** @author zhangwen* @email: 1466787185@qq.com*/
@Data
public class SpuBoundTO {/*** spu id*/private Long spuId;/*** 购物积分*/private BigDecimal buyBounds;/*** 成长积分*/private BigDecimal growBounds;
}
SkuReductionTO
package com.atguigu.common.to;import lombok.Data;import java.math.BigDecimal;
import java.util.List;/*** 满减,会员折扣等信息 TO 对象 {@link SkuReductionTO}** @author zhangwen* @email: 1466787185@qq.com*/
@Data
public class SkuReductionTO {private Long skuId;/*** 满几件*/private int fullCount;/*** 打几折*/private BigDecimal discount;/*** 是否优惠叠加*/private int countStatus;/*** 满多少*/private BigDecimal fullPrice;/*** 减多少*/private BigDecimal reducePrice;/*** 是否叠加优惠*/private int priceStatus;/*** 会员价*/private List<MemberPrice> memberPrice;
}
6.3.2.CouponFeignService 远程接口
CouponFeignService
package com.atguigu.gmall.product.feign;import com.atguigu.common.to.SkuReductionTO;
import com.atguigu.common.to.SpuBoundTO;
import com.atguigu.common.utils.R;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;/*** Coupon 优惠服务远程接口 {@link CouponFeignService}** @author zhangwen* @email: 1466787185@qq.com*/
@FeignClient("gmall-coupon")
public interface CouponFeignService {/*** CouponService.saveSpuBounds(SpuBoundTO spuBoundTO)* 1.@RequestBody将这个对象转为json* 2.在注册中心找到gmall-coupon服务,然后发送 /coupon/spubounds/save 请求* 将转换的json放在请求体发送* 3.gmall-coupon服务接收到请求,请求体里有json数据* 将请求体里json数据转为 SpuBoundTO* 总结:* 只要json数据模型是兼容的,双方服务不一定需要使用同一个 TO 对象** 保存积分* @param spuBoundTO* @return*/@PostMapping("/coupon/spubounds/save")R saveSpuBounds(@RequestBody SpuBoundTO spuBoundTO);/*** 保存满减优惠及会员折扣* @param skuReductionTO* @return*/@PostMapping("coupon/skufullreduction/savareduction")R savaReduction(@RequestBody SkuReductionTO skuReductionTO);
}
6.3.3.CouponFeignService 远程接口实现
gmall-coupon 服务
- /coupon/spubounds/save
- coupon/skufullreduction/savareduction
SpuBoundsController
/*** 保存积分信息*/@PostMapping("/save")public R save(@RequestBody SpuBoundsEntity entity){spuBoundsService.save(entity);return R.ok();}
SkuFullReductionController
/*** 保存满减优惠及会员折扣* @param skuReductionTO* @return*/@PostMapping("/savareduction")public R saveSkuReduction(@RequestBody SkuReductionTO skuReductionTO) {skuFullReductionService.saveSkuReduction(skuReductionTO);return R.ok();}
SkuFullReductionServiceImpl
/*** 保存满减优惠及会员折扣* @param skuReductionTO*/
@Transactional(rollbackFor = Exception.class)
@Override
public void saveSkuReduction(SkuReductionTO skuReductionTO) {// 满几件减 sms_sku_ladderSkuLadderEntity skuLadderEntity = new SkuLadderEntity();BeanUtils.copyProperties(skuReductionTO, skuLadderEntity);skuLadderEntity.setAddOther(skuReductionTO.getCountStatus());if (skuLadderEntity.getFullCount() > 0) {skuLadderService.save(skuLadderEntity);}// 满多少价减 sms_sku_full_reductionSkuFullReductionEntity skuFullReductionEntity = new SkuFullReductionEntity();BeanUtils.copyProperties(skuReductionTO, skuFullReductionEntity);skuFullReductionEntity.setAddOther(skuReductionTO.getCountStatus());if (skuFullReductionEntity.getFullPrice().compareTo(new BigDecimal("0")) == 1) {this.save(skuFullReductionEntity);}//会员价 sms_member_priceList<MemberPriceEntity> memberPriceEntities =skuReductionTO.getMemberPrice().stream().map(memberPrice -> {MemberPriceEntity memberPriceEntity = new MemberPriceEntity();memberPriceEntity.setSkuId(skuReductionTO.getSkuId());memberPriceEntity.setMemberLevelId(memberPrice.getId());memberPriceEntity.setMemberLevelName(memberPrice.getName());memberPriceEntity.setMemberPrice(memberPrice.getPrice());memberPriceEntity.setAddOther(skuReductionTO.getPriceStatus());return memberPriceEntity;}).filter(memberPriceEntity -> {return memberPriceEntity.getMemberPrice().compareTo(new BigDecimal("0")) == 1;}).collect(Collectors.toList());memberPriceService.saveBatch(memberPriceEntities);
}
6.4.后台接口实现
SpuInfoController
/*** 保存发布商品*/@RequestMapping("/save")public R save(@RequestBody SpuVO spuVO){spuInfoService.saveSpuInfo(spuVO);return R.ok();}
SpuInfoServiceImpl
/*** 保存发布商品* @param spuVO*/
@Transactional(rollbackFor = Exception.class)
@Override
public void saveSpuInfo(SpuVO spuVO) {// 1.保存spu基本信息 pms_spu_infoSpuInfoEntity spuInfoEntity = new SpuInfoEntity();BeanUtils.copyProperties(spuVO, spuInfoEntity);spuInfoEntity.setCreateTime(new Date());spuInfoEntity.setUpdateTime(new Date());this.save(spuInfoEntity);// 2.保存spu的描述图片 pms_spu_info_descList<String> decript = spuVO.getDecript();SpuInfoDescEntity spuInfoDescEntity = new SpuInfoDescEntity();spuInfoDescEntity.setSpuId(spuInfoEntity.getId());spuInfoDescEntity.setDecript(String.join(",", decript));spuInfoDescService.save(spuInfoDescEntity);// 3.保存spu的图片集 pms_spu_imagesList<String> images = spuVO.getImages();spuImagesService.saveImages(spuInfoEntity.getId(), images);// 4.保存spu的规格参数 pms_product_attr_valueList<BaseAttrs> baseAttrs = spuVO.getBaseAttrs();productAttrValueService.saveProductAttrValue(spuInfoEntity.getId(), baseAttrs);// 5.保存spu的积分信息,跨库操作,feign远程调用// gmall-sms -> sms_spu_boundsBounds bounds = spuVO.getBounds();SpuBoundTO spuBoundTo = new SpuBoundTO();BeanUtils.copyProperties(bounds, spuBoundTo);spuBoundTo.setSpuId(spuInfoEntity.getId());R r = couponFeignService.saveSpuBounds(spuBoundTo);if (r.getCode() != 0) {log.error("调用远程服务 yomallб coupon 保存积分信息失败");}// 6.保存spu对应的sku信息// sku基本信息 pms_sku_info// sku的图片集 pms_sku_images// sku的销售属性信息 pms_sku_sale_attr_value// sku的满件优惠,满价优惠,会员价等信息,跨库操作// gmall-sms -> sms_sku_ladder, sms_sku_full_reduction, sms_member_priceList<Skus> skus = spuVO.getSkus();if (skus != null && skus.size() > 0) {skuInfoService.saveSkuInfo(spuInfoEntity, skus);}
}
SkuInfoServiceImpl
/*** 保存spu对应的sku* @param spuInfoEntity* @param skus*/
@Transactional(rollbackFor = Exception.class)
@Override
public void saveSkuInfo(SpuInfoEntity spuInfoEntity, List<Skus> skus) {skus.forEach(sku -> {// 保存sku基本信息SkuInfoEntity skuInfoEntity = new SkuInfoEntity();BeanUtils.copyProperties(sku, skuInfoEntity);skuInfoEntity.setBrandId(spuInfoEntity.getBrandId());skuInfoEntity.setCatalogId(spuInfoEntity.getCatalogId());skuInfoEntity.setSpuId(spuInfoEntity.getId());skuInfoEntity.setSaleCount(0L);String defaultImage = "";for (Images image : sku.getImages()) {if (image.getDefaultImg() == 1) {defaultImage = image.getImgUrl();}}skuInfoEntity.setSkuDefaultImg(defaultImage);this.save(skuInfoEntity);// 批量保存sku图片Long skuId = skuInfoEntity.getSkuId();List<SkuImagesEntity> skuImagesEntities =sku.getImages().stream().map(image -> {SkuImagesEntity skuImagesEntity = new SkuImagesEntity();skuImagesEntity.setSkuId(skuId);skuImagesEntity.setDefaultImg(image.getDefaultImg());skuImagesEntity.setImgUrl(image.getImgUrl());return skuImagesEntity;}).filter(skuImagesEntity -> {return !StringUtils.isEmpty(skuImagesEntity.getImgUrl());}).collect(Collectors.toList());skuImagesService.saveBatch(skuImagesEntities);// 批量保存sku属性值List<SkuSaleAttrValueEntity> collect = sku.getAttr().stream().map(attr ->{SkuSaleAttrValueEntity skuSaleAttrValueEntity = new SkuSaleAttrValueEntity();BeanUtils.copyProperties(attr, skuSaleAttrValueEntity);skuSaleAttrValueEntity.setSkuId(spuInfoEntity.getId());return skuSaleAttrValueEntity;}).collect(Collectors.toList());skuSaleAttrValueService.saveBatch(collect);// 保存优惠,满减等信息SkuReductionTO skuReductionTO = new SkuReductionTO();BeanUtils.copyProperties(sku, skuReductionTO);skuReductionTO.setSkuId(skuId);if (skuReductionTO.getFullCount() > 0 ||skuReductionTO.getFullPrice().compareTo(new BigDecimal("0")) == 1){R r = couponFeignService.savaReduction(skuReductionTO);if (r.getCode() != 0) {log.error("调用远程服务 yomallб coupon 保存SKU优惠信息失败");}}});
}
7.SPU管理-列表
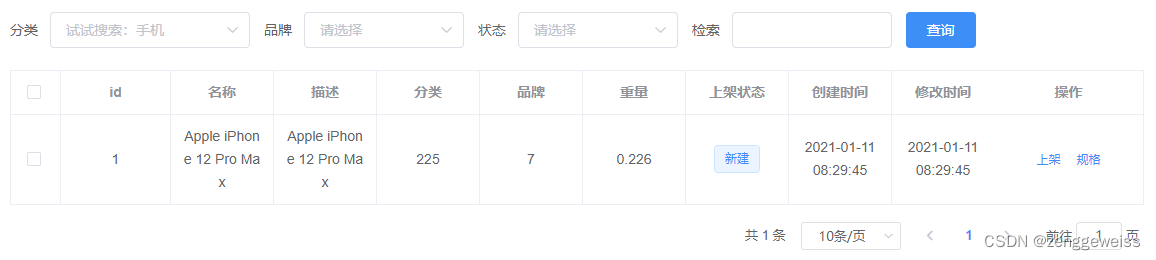
7.1.API
7.2.后台接口实现
SpuInfoController
/*** SPU检索*/
@RequestMapping("/list")
public R list(@RequestParam Map<String, Object> params){PageUtils page = spuInfoService.queryPageByCondition(params);return R.ok().put("page", page);
}
SpuInfoServiceImpl
/*** SPU 检索* @param params* @return*/
@Override
public PageUtils queryPageByCondition(Map<String, Object> params) {QueryWrapper<SpuInfoEntity> queryWrapper = new QueryWrapper<>();String key = (String)params.get("key");if (!StringUtils.isEmpty(key)) {queryWrapper.and(wrapper ->{wrapper.eq("id", key).or().like("spu_name", key);});}String status = (String)params.get("status");if (!StringUtils.isEmpty(status)) {queryWrapper.eq("publish_status", status);}String brandId = (String)params.get("brandId");if (!StringUtils.isEmpty(brandId) && !"0".equalsIgnoreCase(brandId)) {queryWrapper.eq("brand_id", brandId);}String catelogId = (String)params.get("catelogId");if (!StringUtils.isEmpty(catelogId) && !"0".equalsIgnoreCase(catelogId)) {queryWrapper.eq("catalog_id", catelogId);}IPage<SpuInfoEntity> page = this.page(new Query<SpuInfoEntity>().getPage(params),queryWrapper);return new PageUtils(page);
}
8.商品管理
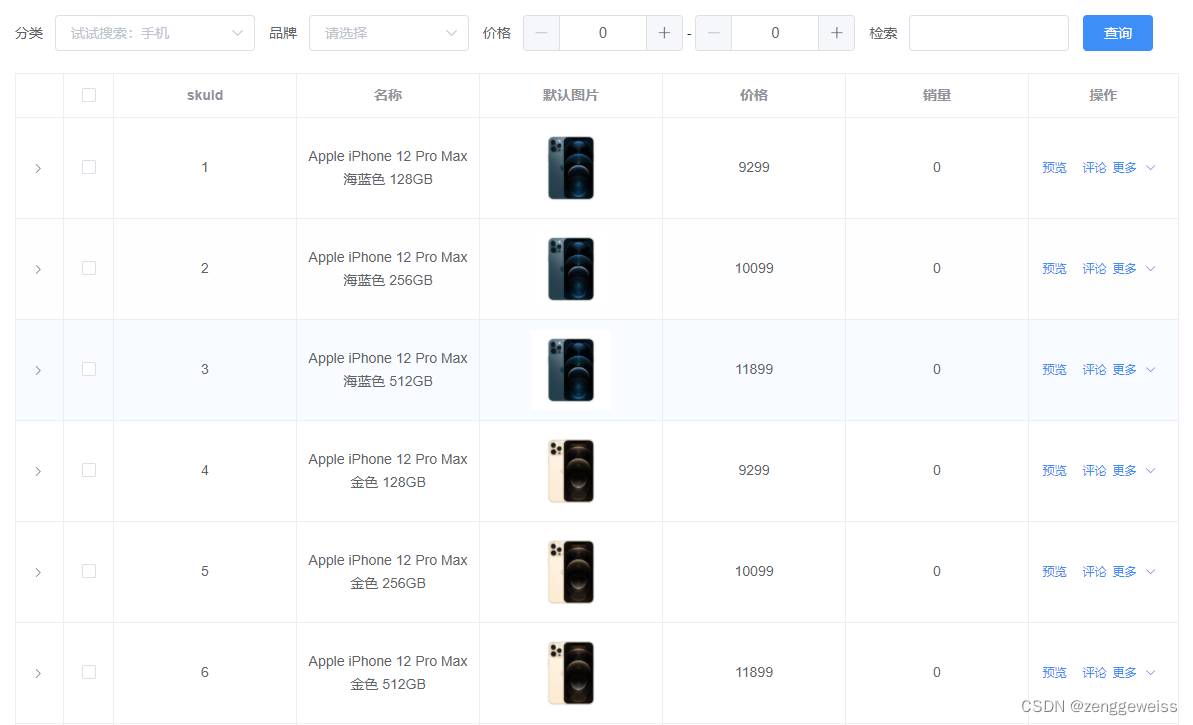
8.1.SKU检索
8.1.1.API
GET /product/skuinfo/list
8.1.2.后台接口实现
SkuInfoController
/*** SKU检索*/
@RequestMapping("/list")
public R list(@RequestParam Map<String, Object> params){PageUtils page = skuInfoService.queryPageByCondition(params);return R.ok().put("page", page);
}
SkuInfoServiceImpl
/*** SKU检索* @param params* @return*/
@Override
public PageUtils queryPageByCondition(Map<String, Object> params) {QueryWrapper<SkuInfoEntity> queryWrapper = new QueryWrapper<>();String key = (String)params.get("key");if (!StringUtils.isEmpty(key)) {queryWrapper.and(wrapper -> {wrapper.eq("sku_id", key).or().like("sku_name", key);});}String brandId = (String)params.get("brandId");if (!StringUtils.isEmpty(brandId) && !"0".equalsIgnoreCase(brandId)) {queryWrapper.eq("brand_id", brandId);}String catelogId = (String)params.get("catelogId");if (!StringUtils.isEmpty(catelogId) && !"0".equalsIgnoreCase(catelogId)) {queryWrapper.eq("catalog_id", catelogId);}String min = (String)params.get("min");if (!StringUtils.isEmpty(min)) {queryWrapper.ge("price", min);}String max = (String)params.get("max");if (!StringUtils.isEmpty(max) && !"0".equalsIgnoreCase(max)) {queryWrapper.le("price", max);}IPage<SkuInfoEntity> page = this.page(new Query<SkuInfoEntity>().getPage(params),queryWrapper);return new PageUtils(page);
}