榆林公司网站建设wordpress音乐播放插件
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码、数据、讲解

💥1 概述
由于能源的日益匮乏,电力需求的不断增长等,配电网中分布式能源渗透率不断提高,且逐渐向主动配电网方向发展。此外,需求响应(demand response,DR)的加入对配电网的规划运行也带来了新的因素[1-2]。因此,如何综合考虑分布式发电 (distributed generation,DG)和负荷,甚至需求响应负荷的关系,从而制定有效的协同规划方案,来应对高渗透分布式电源接入给主动配电网带来的诸多问题,具有较大的意义和价值。国内外学者对传统配电网规划方案作了大量的研究工作,如 DG 规划[3-4]、网架规划[5-6]、无功补偿规划[7]等。文献[3-7]均为单一规划,然而在分布式能源大力提倡和发展环境下,配电网公司应综合考虑 DG 和用户响应等关联因素,制定协同规划方案。当前配电网协同规划领域研究主要集中在变 电站和线路协同规划[8]及变电站、线路和电容的协同规划[9]等,其设计目标主要集中于减少传统配电网规划的设备投资,进而满足负荷的长。
随着分布式电源(distributed generation,DG)的渗透率不断增长,其出力的不确定性限制了配电网的消纳能力[1] 。安装储能设备等传统的解决措施又受到规划成本、设备灵活性等诸多方面的制约。柔性负荷具有成本低、灵活度高的特点,可代替储能设备实现一定的辅助功能,其与实际储能被统称为广义储能系统[2⁃3] ,是现代配电网规划中的重要部分。
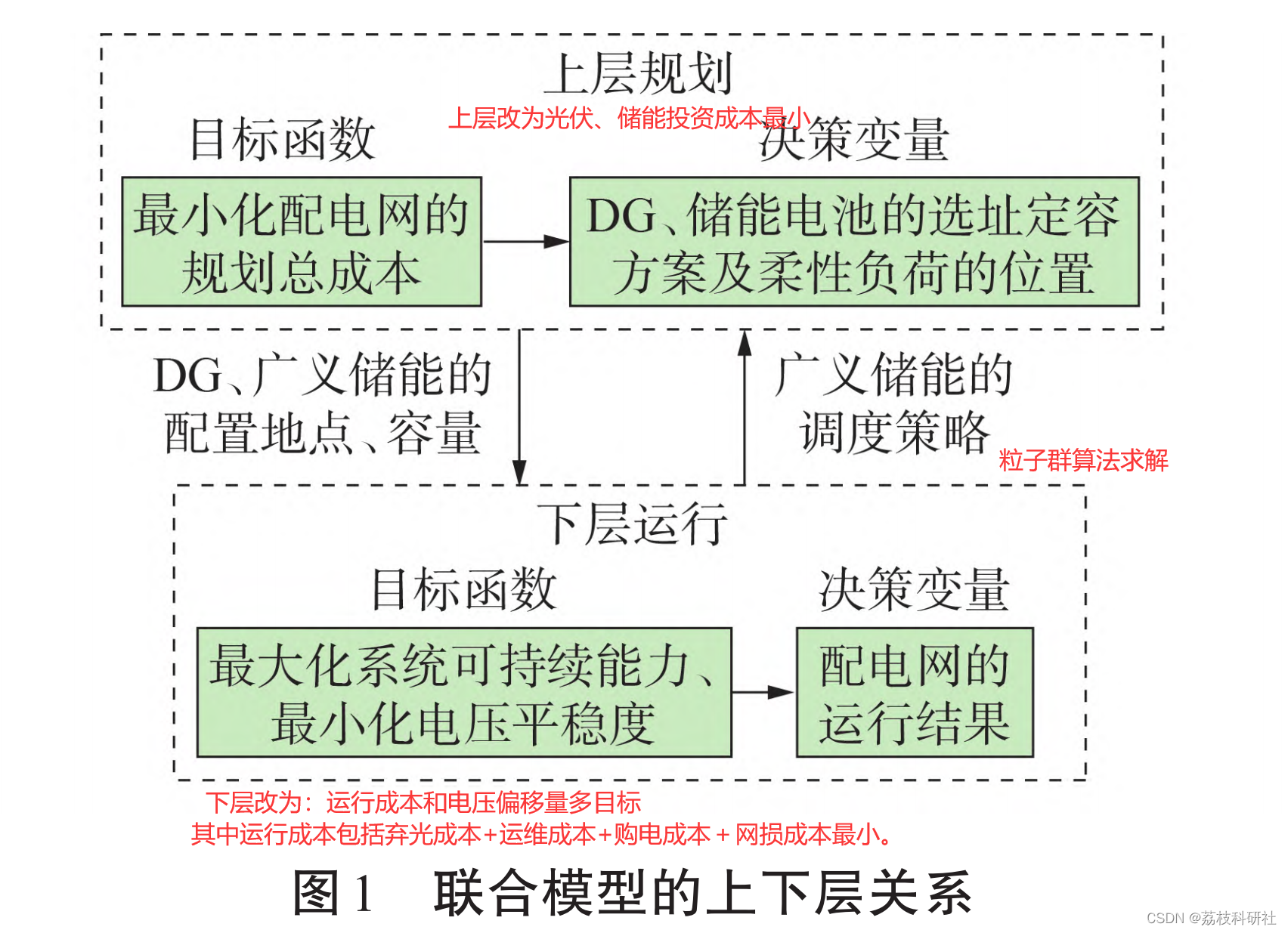
粒子群优化算法(particle swarm optimization,PSO)是一种利用微粒模拟飞鸟捕食行为,不断更新粒子位置和速度,寻找目标最优解的优化算法。该算法因收敛速度快,搜索能力强的特点而受到广泛应用。本文采用惯性权重因子和学习因子调整的改进粒子群算法,进一步优化粒子搜索能力,提高运算收敛性。改进粒子群算法求解双层优化模型步骤如下:
1)输入配电网络参数,采用 K-均值多场景分析法对风光荷年历史数据进行处理,将风光荷随机特性用不同季节不同气候下多个典型日确定化描述,得到各典型日场景数据和概率;
2)初始化粒子位置和速度,即规划层灵活性资源的位置和容量,作为运行层的输入;
然后上下两层规划如下:
📚2 运行结果
链接:https://pan.baidu.com/s/1HYG1K_NrhYuYzi0LOFq83g
提取码:urub
--来自百度网盘超级会员V3的分享
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]高红均,刘俊勇.考虑不同类型DG和负荷建模的主动配电网协同规划[J].中国电机工程学报,2016,36(18):4911-4922+5115.DOI:10.13334/j.0258-8013.pcsee.152440.
[2]刘自发,于普洋,李颉雨.计及运行特性的配电网分布式电源与广义储能规划[J].电力自动化设备,2023,43(03):72-79.DOI:10.16081/j.epae.202208029.
[3]任智君,郭红霞,杨苹等.含高比例可再生能源配电网灵活资源双层优化配置[J].太阳能学报,2021,42(09):33-38.DOI:10.19912/j.0254-0096.tynxb.2019-0783.