网站搭建模板素材当阳市住房和城乡建设局网站
如何在 Windows 10 环境下安装和配置 MySQL:初学者指南
MySQL 是一个流行的开源数据库管理系统,广泛应用于各种应用程序中。对于初学者来说,了解如何在 Windows 10 环境下安装和配置 MySQL 是一个重要的第一步。本篇博客将详细介绍如何完成这些步骤,确保你能顺利地启动和使用 MySQL。
一、下载 MySQL 安装包
-
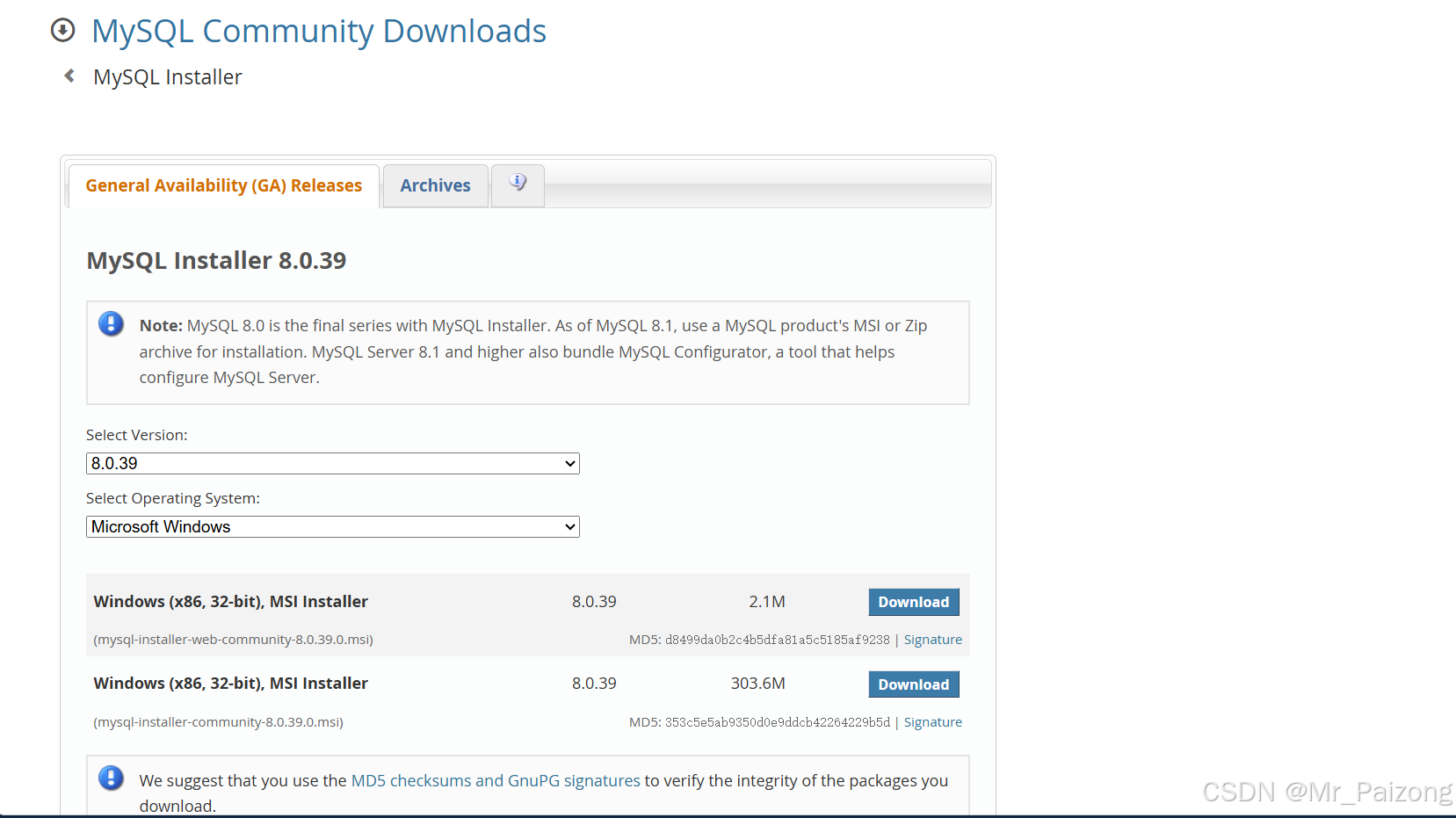
访问 MySQL 官方网站
打开浏览器,前往 MySQL 的官方下载页面。这里你会看到两种主要的安装包:Web 版和完整版。
-
选择安装包
- Web 版:体积较小,安装过程中会从互联网下载所需组件。
- 完整版:包含所有必要组件,下载后可以离线安装。
对于初学者来说,建议选择 完整版,因为它不需要每次都从互联网下载组件,方便离线安装。
-
下载并运行安装程序
点击下载你选择的版本,下载完成后双击运行安装程序。
二、安装 MySQL
-
启动 MySQL Installer
双击你下载的安装程序以启动 MySQL Installer。在欢迎界面点击“下一步”继续。
-
选择安装类型
MySQL Installer 提供了多种安装选项,你可以选择:
- Developer Default:安装 MySQL Server、Workbench 和其他开发工具。
- Server Only:只安装 MySQL Server。
- Client Only:只安装客户端工具。
- Full:安装所有组件。
- Custom:自定义选择组件。
对于初学者,建议选择 Developer Default,这样你将获得所有基本的开发工具。
-
安装依赖项
MySQL Installer 可能会检查并安装一些必要的依赖项。点击“执行”以安装这些依赖项。
-
选择安装位置
安装程序默认将 MySQL 安装在
C:\Program Files\MySQL\MySQL Server X.X。你可以选择其他位置,但通常建议使用默认位置。 -
配置 MySQL
- 选择配置类型:选择 "Development Machine"(开发机器),适合大多数开发者使用。
- 选择数据库引擎:一般选择默认选项即可。
- 设置端口号:默认端口号是 3306。除非有特殊要求,否则可以保留默认设置。
- 配置字符集:建议选择 UTF-8 编码,以确保支持多语言字符。
- 设置 root 用户密码:输入并确认 root 用户的密码。请务必记住这个密码,因为它用于管理数据库。
- 创建其他用户(可选):如果需要,还可以创建其他用户,并设置相应权限。
-
应用配置
配置完成后,点击“执行”以应用设置。安装程序会开始配置 MySQL Server,这可能需要几分钟时间。
三、验证 MySQL 安装
-
启动 MySQL Server
安装完成后,MySQL Server 应该会自动启动。你可以通过系统托盘的 MySQL 图标或使用 Windows 服务管理工具来检查 MySQL 服务的状态。
-
使用 MySQL Workbench 连接
- 打开 MySQL Workbench(如果你选择了安装它)。
- 点击左上角的 “+” 按钮创建新的连接。
- 输入连接名称,主机名(通常是
localhost),端口号(默认是 3306),以及之前设置的 root 用户密码。 - 点击“测试连接”,如果能成功连接到 MySQL 服务器,说明安装成功。
-
在命令提示符中检查 MySQL 安装
- 打开命令提示符:按下
Win + R,输入cmd并按回车。 - 检查 MySQL 版本:在命令提示符中输入
mysql --version并按回车。如果 MySQL 正常安装并配置好,你将看到类似于mysql Ver 8.0.28 for Win64 on x86_64 (MySQL Community Server - GPL)的版本信息。 - 登录 MySQL:输入
mysql -u root -p并按回车。系统会提示你输入之前设置的 root 用户密码。输入正确的密码后,你将进入 MySQL 的命令行界面,显示mysql>提示符。
- 打开命令提示符:按下

四、配置环境变量(可选)
为了在命令行中方便地使用 MySQL,你可以将 MySQL 的安装目录添加到系统的环境变量中:
-
打开系统属性
右键点击桌面上的 “此电脑” 图标,选择 “属性”。点击 “高级系统设置”,在系统属性对话框中,点击 “环境变量”。
-
编辑系统环境变量
- 在 “系统变量” 部分找到变量名为
Path的项,选中它,点击 “编辑”。 - 点击 “新建”,然后输入 MySQL 的
bin目录路径,例如C:\Program Files\MySQL\MySQL Server X.X\bin。 - 点击 “确定” 保存设置。
- 在 “系统变量” 部分找到变量名为
-
验证环境变量
打开命令提示符(CMD),输入
mysql --version,如果能看到 MySQL 的版本信息,说明环境变量配置成功。
当然,以下是关于安装 Navicat Premium Lite 17 的更详细步骤:
五、安装 Navicat Premium Lite 17
Navicat Premium Lite 是一款功能强大的数据库管理工具,支持多种数据库的连接和管理。以下是详细的安装步骤:

-
下载 Navicat Premium Lite 17
- 访问 Navicat 官网。
- 在产品页面选择“下载”选项,进入下载页面。
- 找到 Navicat Premium Lite 17 的下载链接,选择适合你操作系统的版本(Windows、macOS、Linux)。
- 点击下载链接,保存安装包到你的计算机。
-
运行安装程序
- 找到下载的安装包(通常是一个
.exe文件),双击以启动安装程序。 - 如果系统弹出安全警告,确认你希望运行该程序。
- 找到下载的安装包(通常是一个
-
启动安装向导
- 安装向导启动后,你会看到一个欢迎界面。点击“下一步”以继续。
-
阅读并接受许可协议
- 安装程序会展示许可协议。请仔细阅读协议内容。
- 勾选“我接受协议”,然后点击“下一步”。
-
选择安装位置
- 默认安装路径通常是
C:\Program Files\Navicat Premium Lite 17。你可以点击“浏览”按钮选择其他安装位置。 - 确定安装路径后,点击“下一步”。
- 默认安装路径通常是
-
选择开始菜单文件夹
- 安装程序会询问你是否希望在开始菜单中创建 Navicat 的快捷方式。你可以选择默认文件夹或自定义文件夹。
- 点击“下一步”。
-
选择附加任务
- 在此步骤,你可以选择是否创建桌面图标、快速启动图标等。根据你的需求勾选相应选项。
- 点击“下一步”。
-
开始安装
- 安装程序将显示一个总结页面,列出你选择的安装选项。
- 点击“安装”开始实际的安装过程。安装过程可能需要几分钟时间,请耐心等待。
-
完成安装
- 安装完成后,安装程序会显示“完成”页面。你可以选择立即启动 Navicat Premium Lite 17,或者取消勾选此选项后手动启动。
- 点击“完成”退出安装向导。
-
启动 Navicat Premium Lite 17
- 如果在安装过程中选择了启动 Navicat Premium Lite 17,你会自动看到启动界面。
- 否则,你可以通过开始菜单、桌面快捷方式或在
C:\Program Files\Navicat Premium Lite 17目录下找到并运行 Navicat Premium Lite 17。
-
初次启动和设置
- 启动 Navicat Premium Lite 17 后,你将看到初始设置向导。
- 在主界面中,你可以点击“连接”按钮,创建新的数据库连接。
- 选择你要连接的数据库类型(如 MySQL、PostgreSQL 等),输入连接信息(主机名、端口号、用户名、密码等),然后点击“测试连接”以确保设置正确。
- 成功测试后,点击“确定”保存连接设置,并开始使用 Navicat Premium Lite 17 进行数据库管理。
这样,你就完成了 Navicat Premium Lite 17 的安装和初步配置。如果在安装过程中遇到任何问题,建议查看官方文档或寻求技术支持。希望这对你有所帮助!如果还有其他问题,请随时告诉我。
六、总结
恭喜你!你已经成功在 Windows 10 环境下安装并配置好了 MySQL,并安装了 Navicat Premium Lite 17。现在,你可以使用 Navicat Premium Lite 进行数据库的可视化管理,使用 MySQL 进行各种数据库操作。如果你遇到任何问题,可以参考 MySQL 和 Navicat 的官方文档或在社区中寻求帮助。
希望这篇博客对你有所帮助,如果有任何问题或建议,欢迎在评论区留言讨论!