php网站项目做恒生指数看什么网站
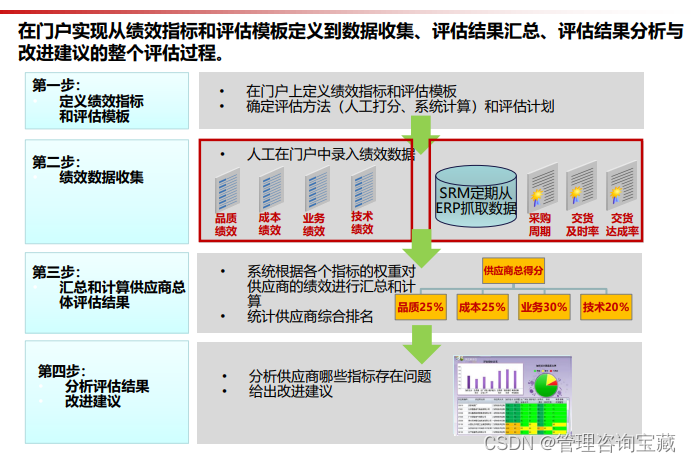

本报告首发于公号“管理咨询宝藏”,如需阅读完整版报告内容,请查阅公号“管理咨询宝藏”。
【管理咨询宝藏95】SRM采购平台建设内部培训方案
【格式】PDF版本
【关键词】SRM采购、制造型企业转型、数字化转型
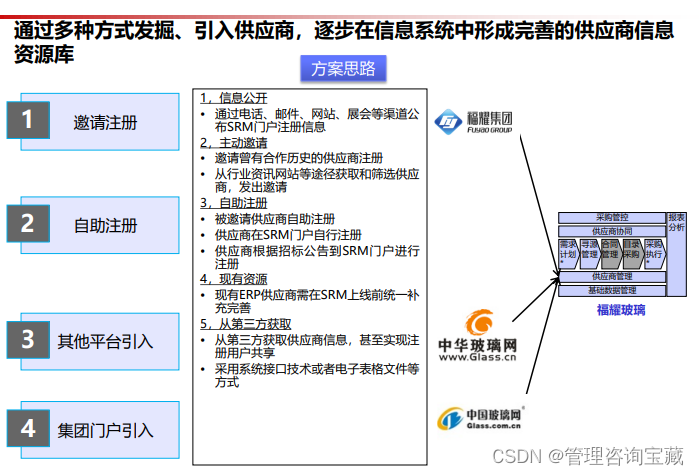
【核心观点】
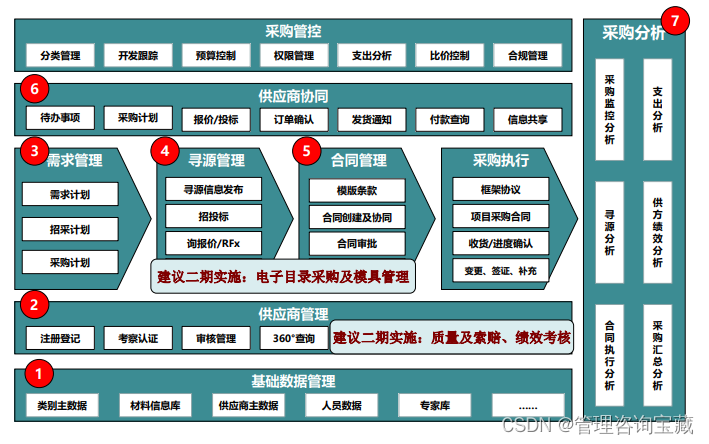
- 重点是建设一个适应战略采购要求,兼顾整个供应链资源整合、优化,可持续降低采购成本,高效处理采购业务,支撑集团管控的采购管理平台。
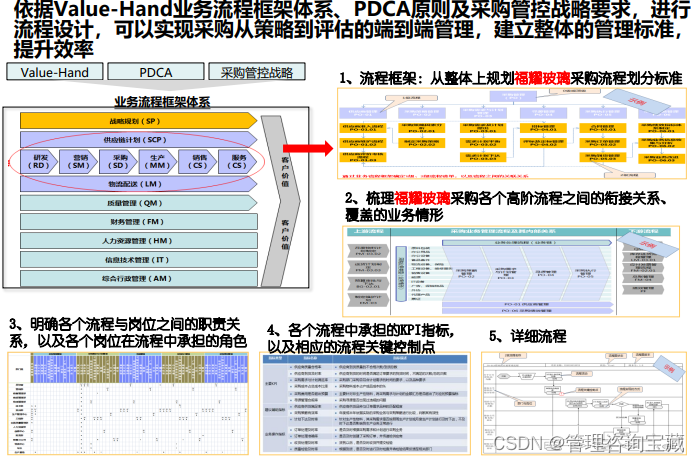
- 依据Value-Hand业务流程框架体系、PDCA原则及采购管控战略要求,进行流程设计,可以实现采购从策略到评估的端到端管理,建立整体的管理标准,提升效率
- 附件开发需要对开发的模具模摊情况进行跟踪,要了解已模摊的数量,当模摊数量完毕后系统参考价格自动下调,对每个开发协议的模具由系统自动生成一个模具号码
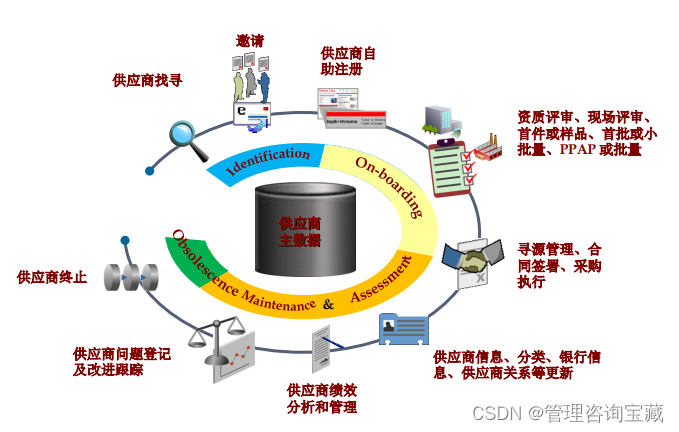
- Oracle SRM是面向企业采购流程信息化建设的完整解决方案。基于供应商关系管理体系在供应商管理、寻源管理、合同三大采购管理领域的成功实践,形成了深度契合业务实务的三项组件级解决方案。三者既相互独立,快速部署,满足企业在单一领域的深度需求;又无缝衔接,优化组合,构筑供应链全生命周期管理图景。
……