个人搭建网站微信公众号是在哪个网站做的
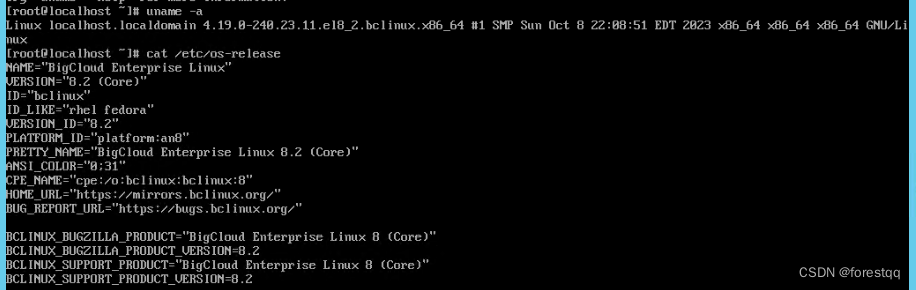
有个业务系统因为兼容性问题,需要安装el8.2的系统,因此对应安装国产环境下的BCLinuxR8U2系统来满足用户需求。BCLinux-R8-U2-Server是中国移动基于AnolisOS8.2深度定制的企业级X86服务器通用版操作系统。本文记录在DELL PowerEdge R720xd服务器上最小化安装该系统的过程。
一、下载ISO
1、下载官网链接
BCLinux-R8-U2-Server-x86_64-231017.iso
2、官方ISO文件的md5值
a7bd5e2a8834a2d1d95c7a2b148873b4dd527c65e1b81f76373c88deb6b69fa7 BCLinux-R8-U2-Server-x86_64-231017.iso
3、校验文件

可见文件包正常。
二、安装测试
1、服务器环境
本次测试服务器为DELL PowerEdge R720xd
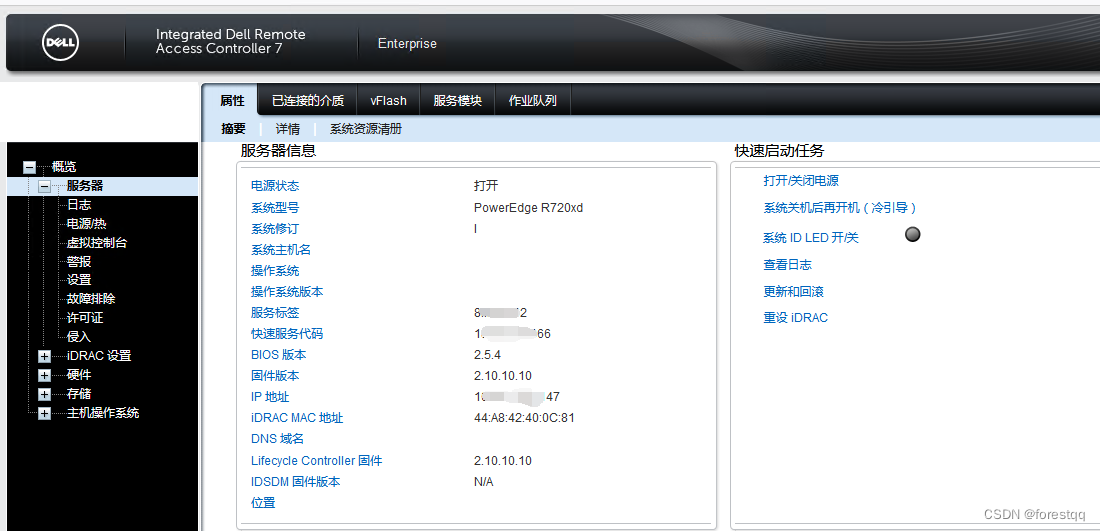
2、挂载镜像
2.1 登录至服务器控制台,进入虚拟控制台
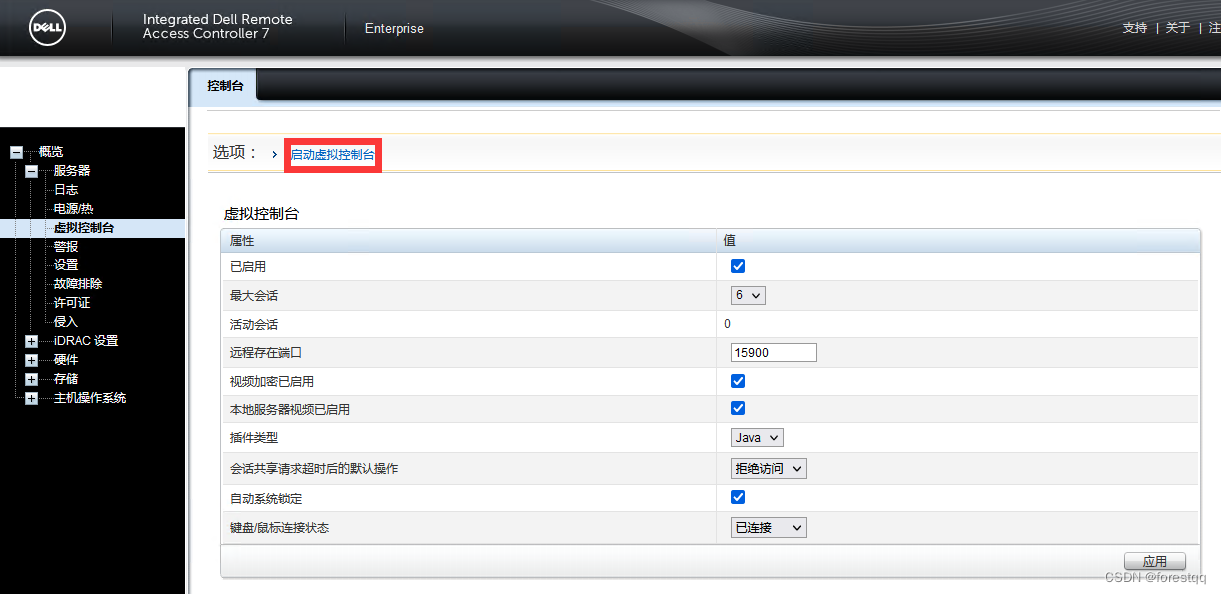
2.2 在控制台界面进行光驱挂载
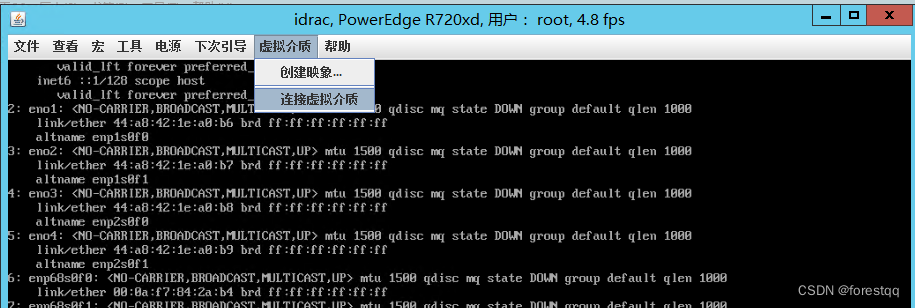
2.3 选中本地映像文件
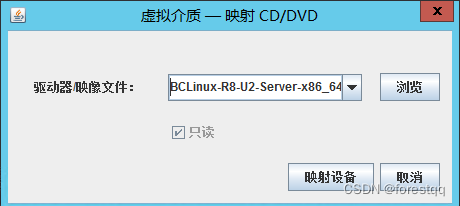
2.4 确认已挂载

2.5 配置下一次从虚拟光盘引导

2.6 重启服务器开始安装
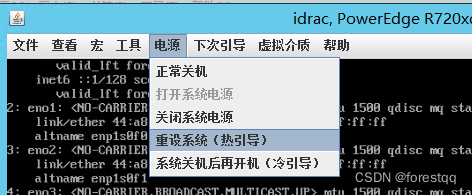
3、开始安装
3.1 重启后自动从光盘引导
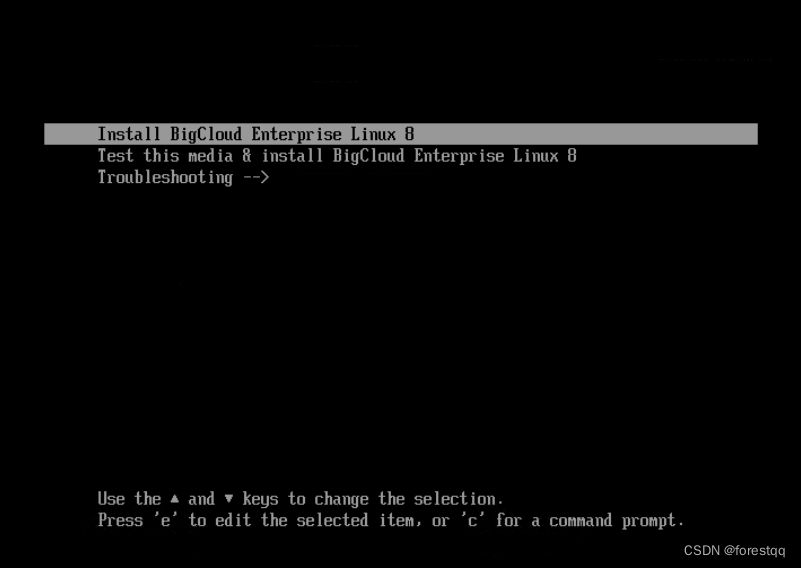
3.2 开始安装
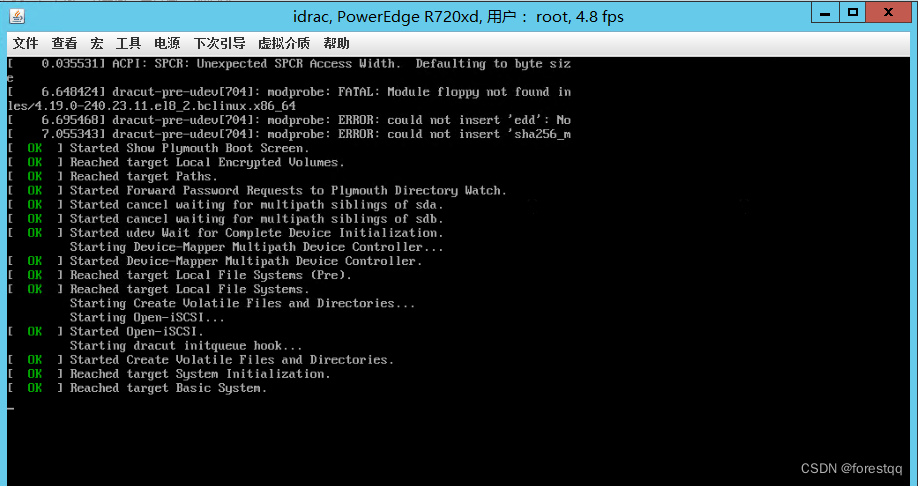
3.3 配置显示语言
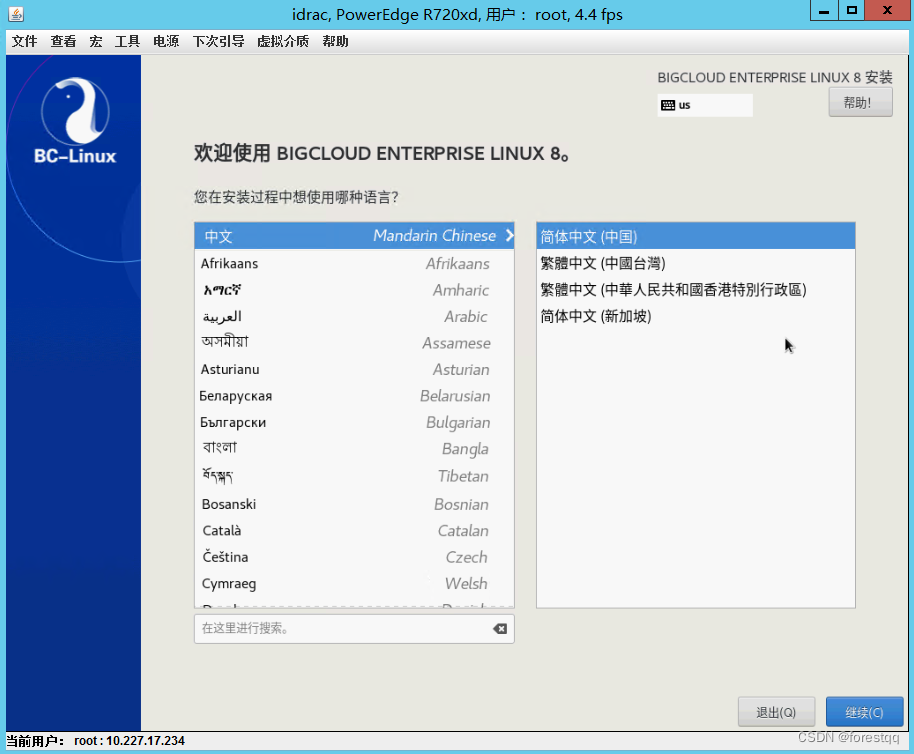
3.4 选择目标硬盘
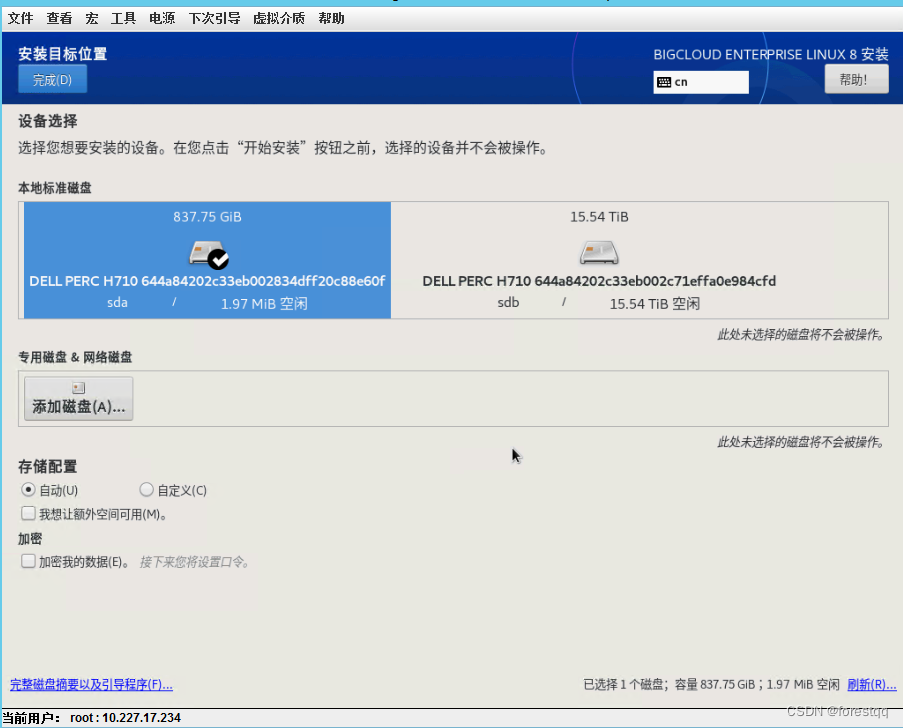
3.5 配置网络,本例使用enp5s0f1和enp66s0f1两个网口组成主备的bond
 3.6 配置IP
3.6 配置IP

3.7 禁用KDUMP
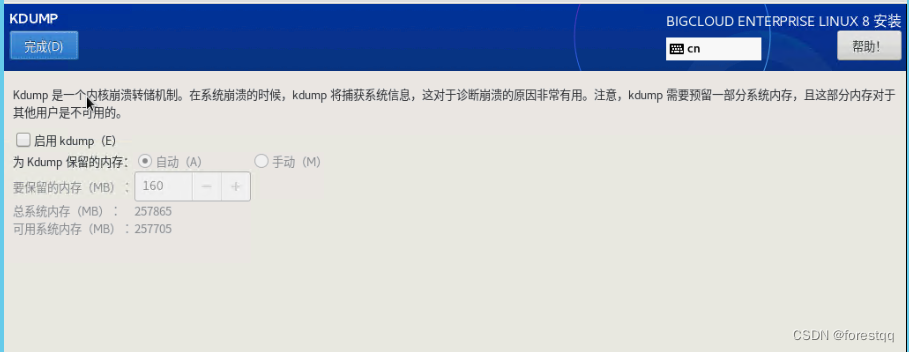
3.8选择时区
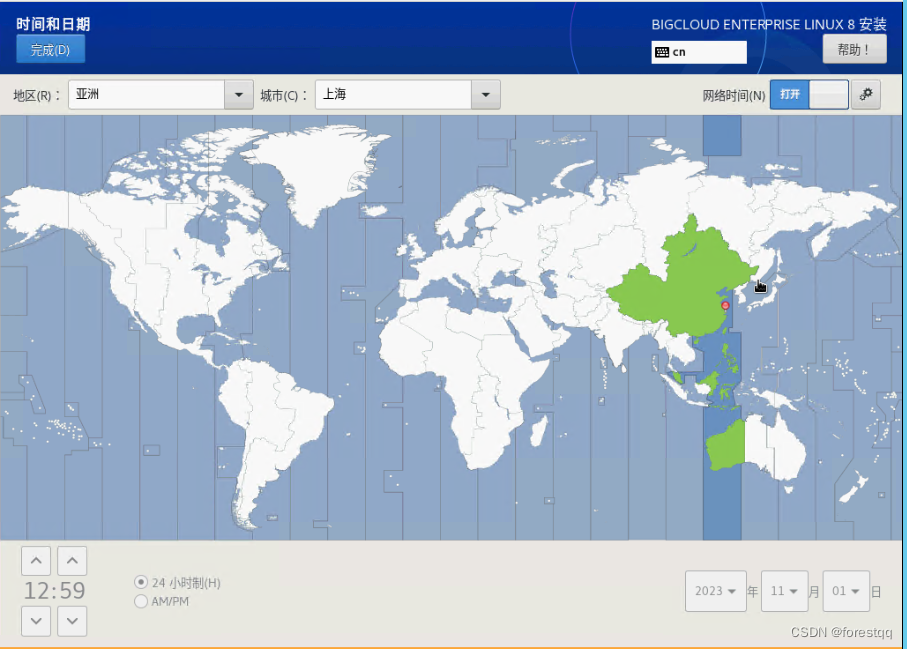
3.9 安装配置信息摘要
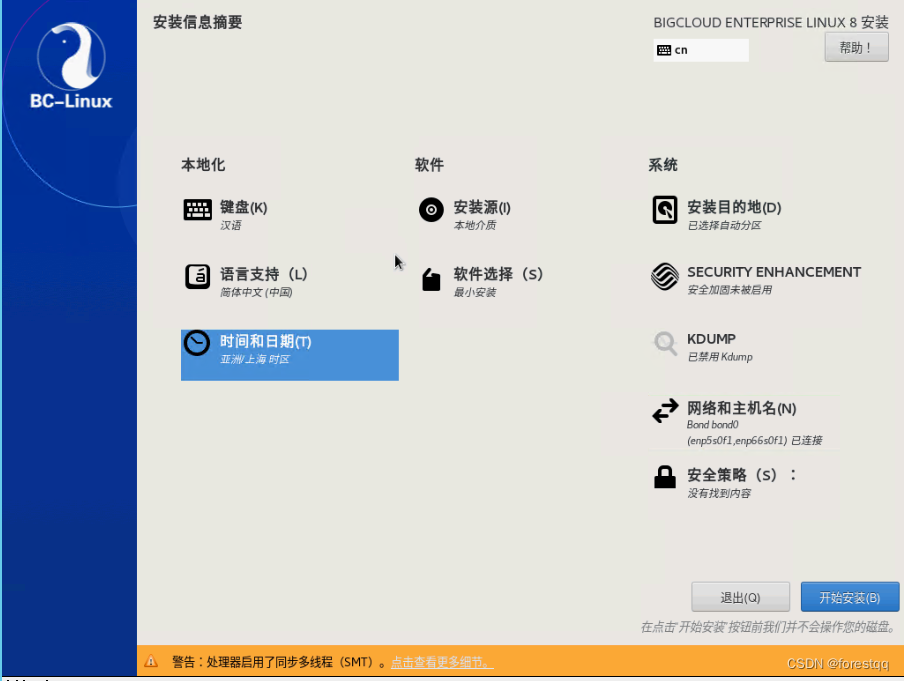
3.10 配置root密码和新建普通用户
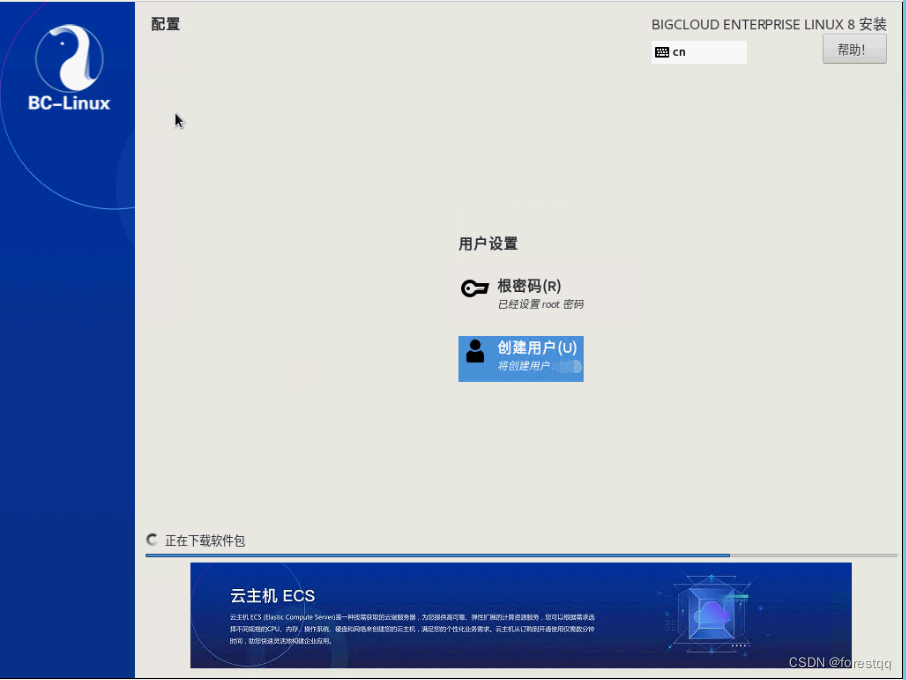
3.11 等待较长时间的安装过程(ISO镜像基于网络挂载,相对本地时间更长),完成后点击重启
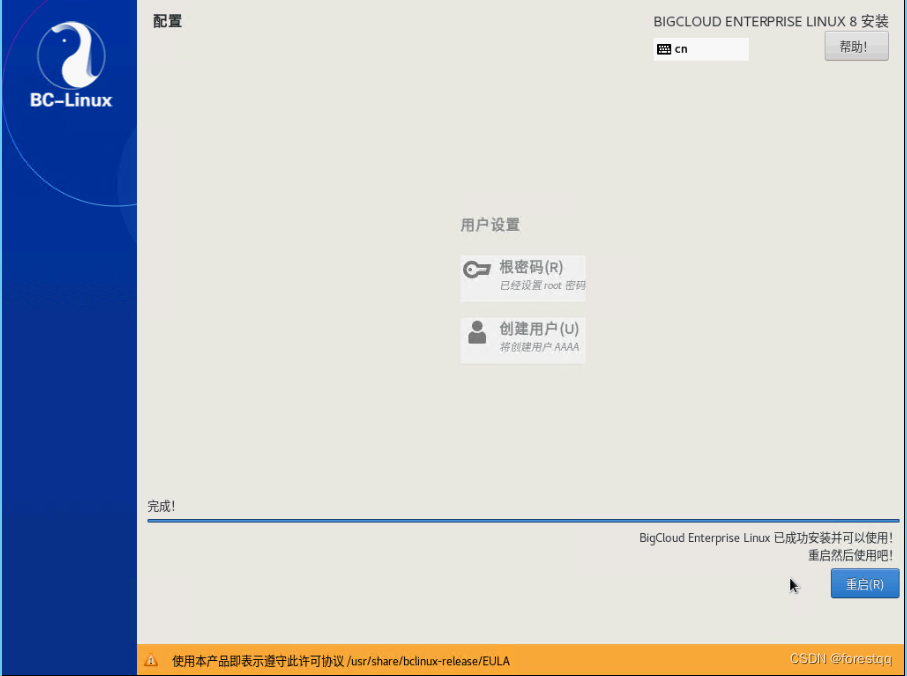
三、验证版本信息
1. 登录系统
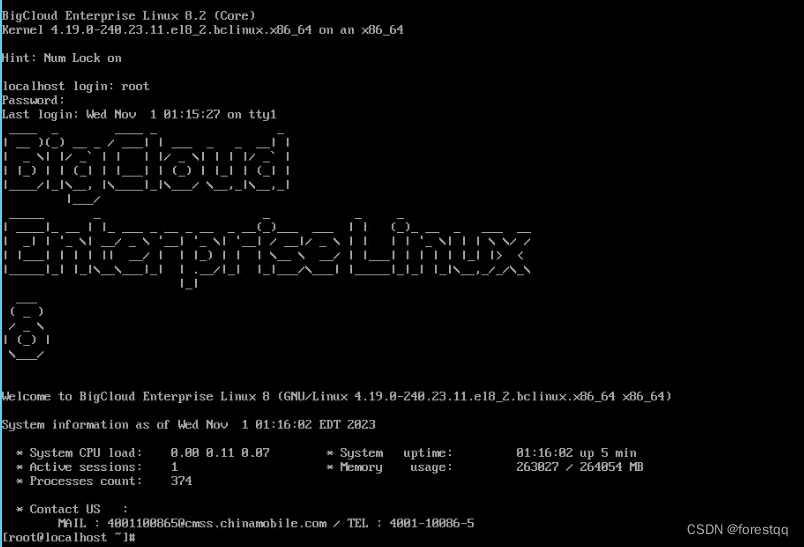
2. 验证版本信息