中国建设工程招聘信息网站广州企业建站模板

1.前言
对于大多数开发人员来说,我们大多数在学习或者工作过程中只关注核心部分,比如说学习Java,可能对于大多数人而言一开始都是从Java基础学起,然后408,Spring,中间件等,当你发现很多高深的技术已经掌握,想要大展拳脚的时候,却倒在了第一步---工具的使用。上面所述是对于还没工作的同学的描述,我自己也是有亲身经历,第一次在阿里实习的时候,带我的师兄叫我拉个分支,之前我是接触过Git,但是用起来磕磕碰碰,导致后续push,pull,merge代码的时候频频出错,因此我认为作为新人第一步就是需要会折腾,这里的折腾是对开发工具,环境的折腾,这样不仅提高开发效率,而且对于后续陌生的环境也会得心应手。
2.Git的介绍
GIt是一个开源的分布式版本控制系统,可以快速高效的处理从小到大的各种项目。
常见的版本控制工具有:Subversion,CVS,Perforce和ClearCase。但是Git由于采用分布式的方式操作,相比较其他的版本控制工具性能较优。
3.Git工作机制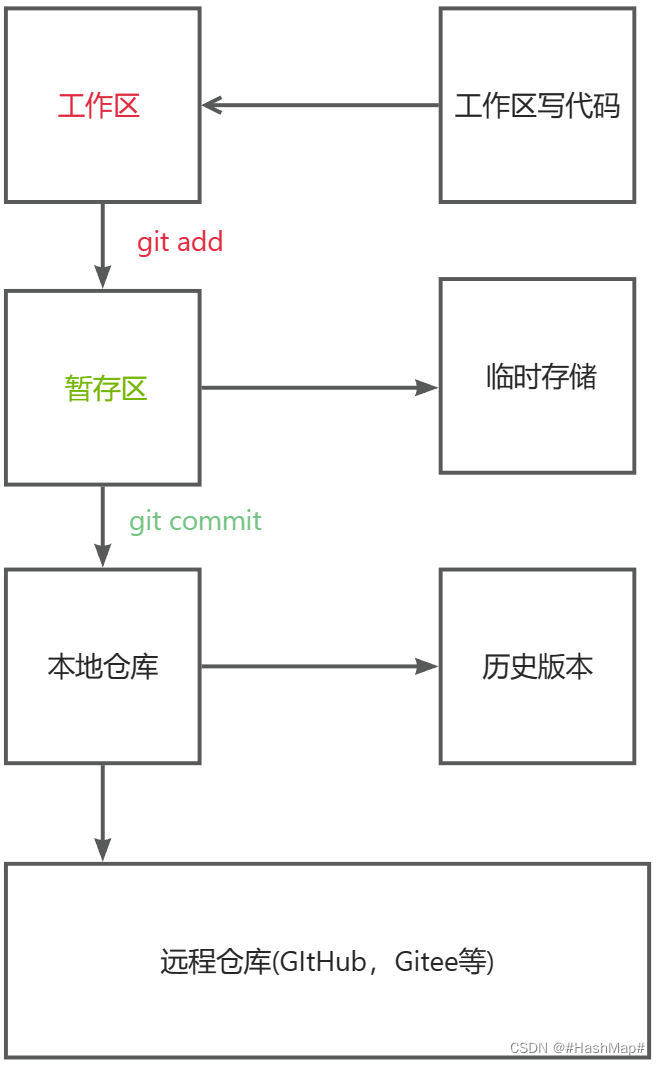
GIt分为三个区域:工作区,暂存区和本地库。
工作区:简单地说就是我们程序员写代码的区域,比如idea里,当我们对代码进行了修改之后需要使用git add命令添加到暂存区。
暂存区:暂存区相当于临时存储的区域,在这个区域的部分为红的,然后需要使用git commit命令提交到本地库
本地库:本地库存储的是历史版本,这部分区域是绿色的,最后可以通过push,pull和merge等操作与远程仓库交互。
4.Git常用命令
git config --global user.name 用户名 设置用户名
git config --global user.email 邮箱 设置用户邮箱
git init 初始化本地库
git status 查询本地库状态
git add 文件名 添加文件到暂存库
git commit -m "first commit" 文件名 提交文件到本地库
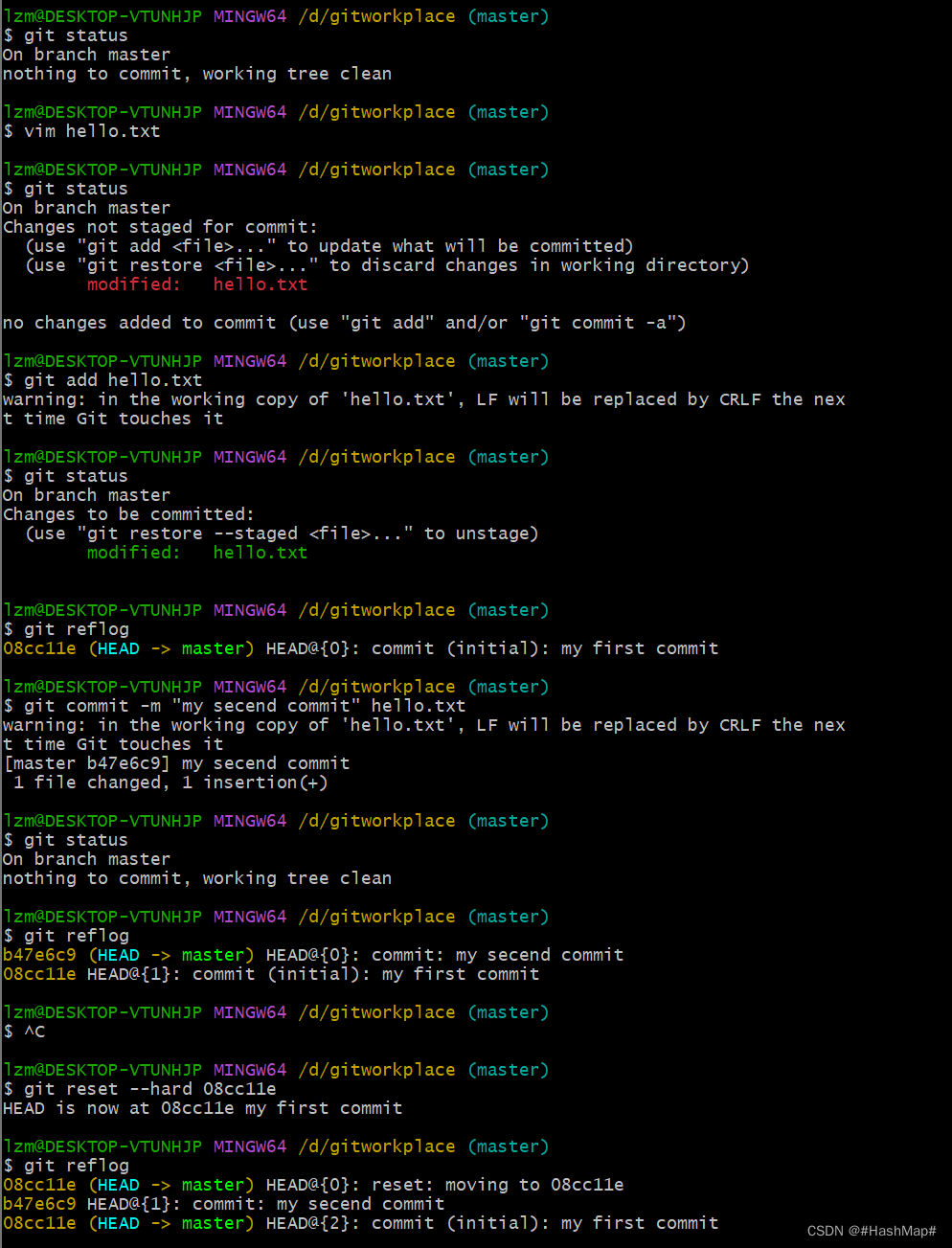
git reflog 查看历史版本
git reset --hard 版本号 版本穿梭(回退)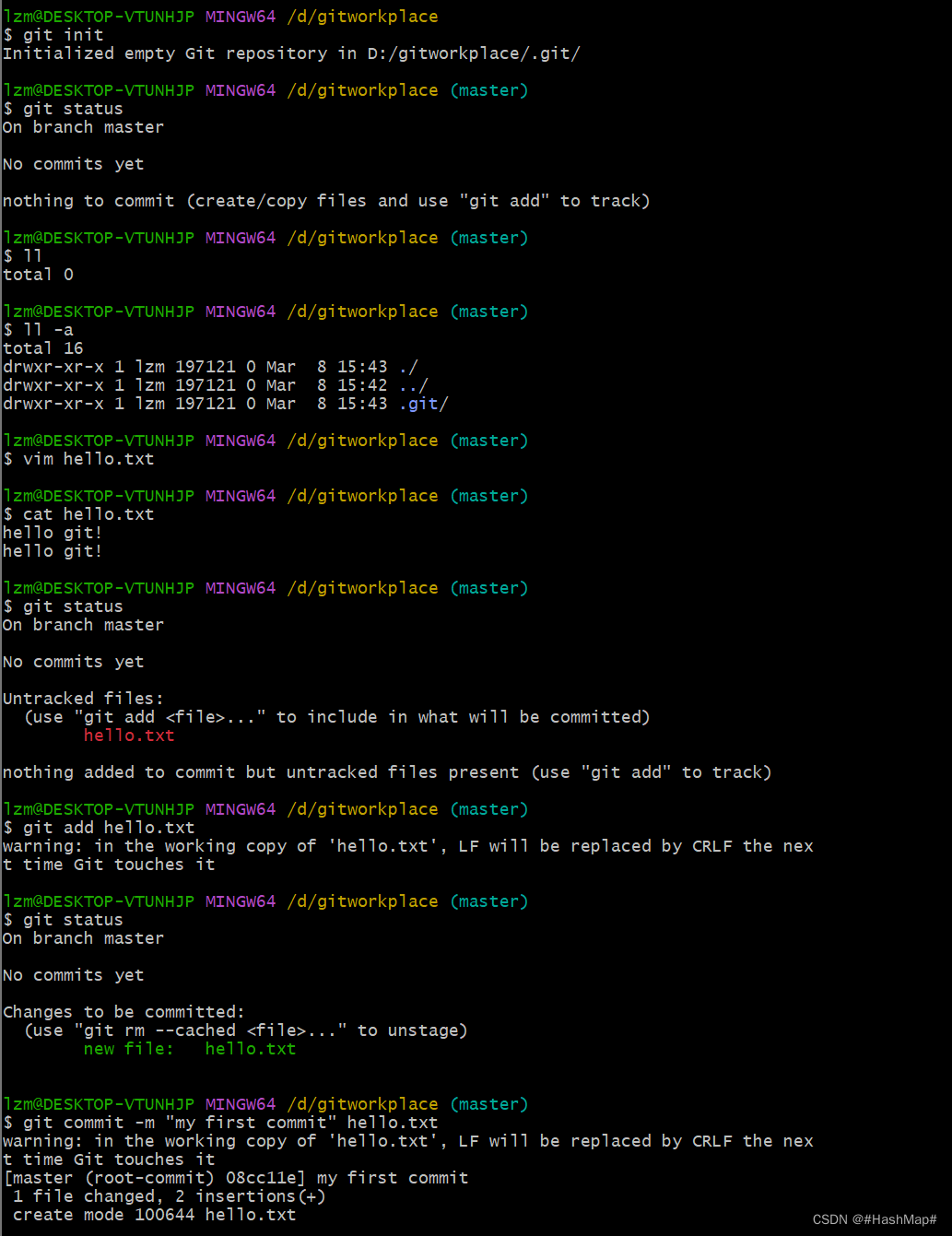
5.分支操作
基本的分支操作命令:
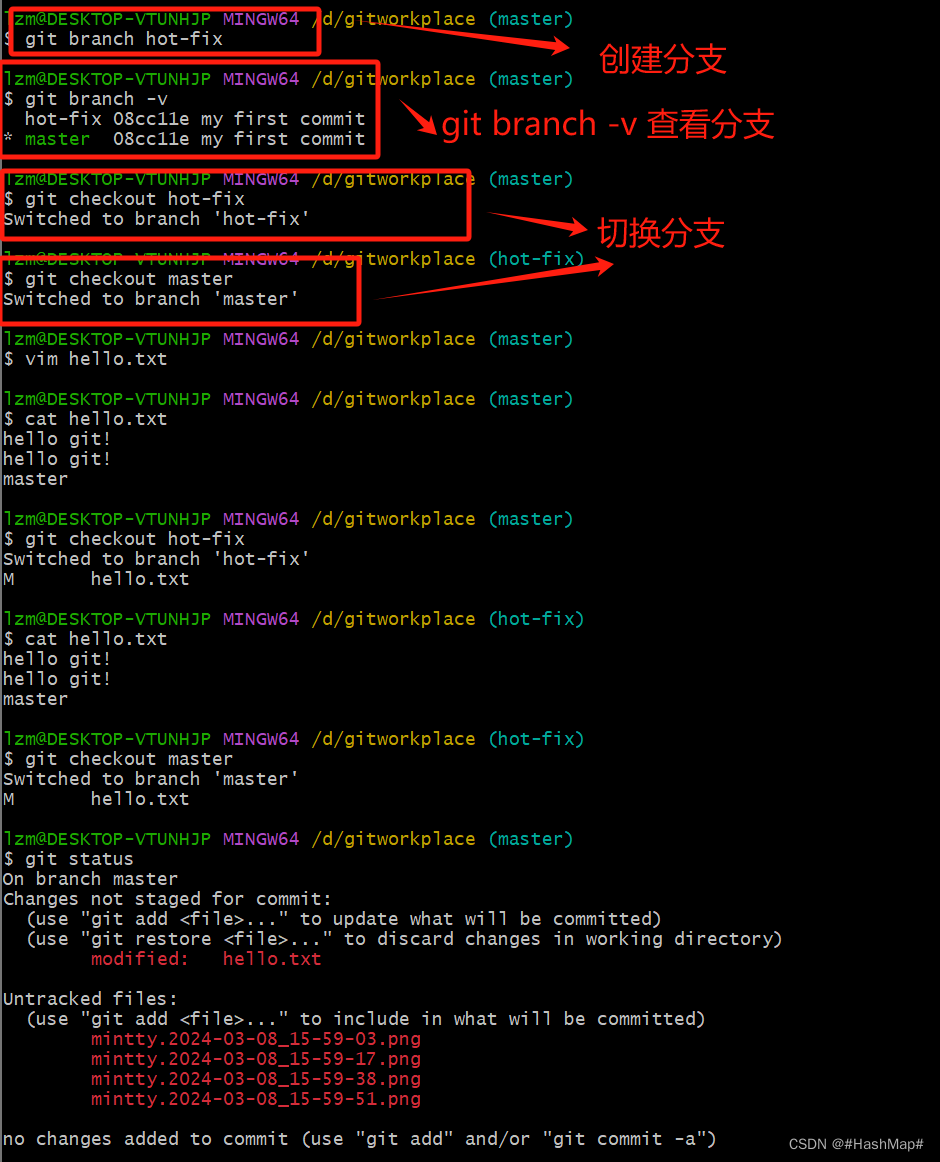
git branch 分支名 创建分支
git branch -v 查看分支
git checkout 分支名 切换分支
git merge 分支名 合并分支在Git Bash上进行的测试:
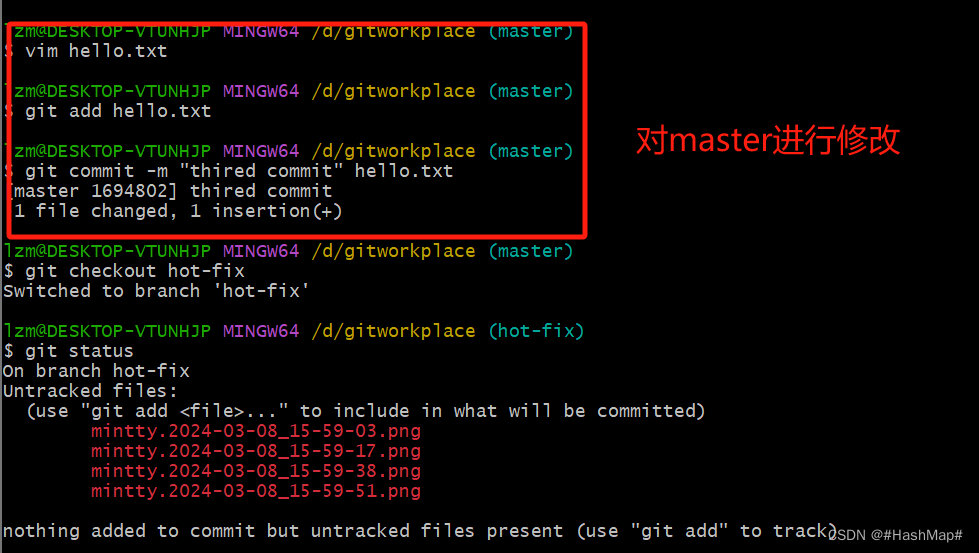
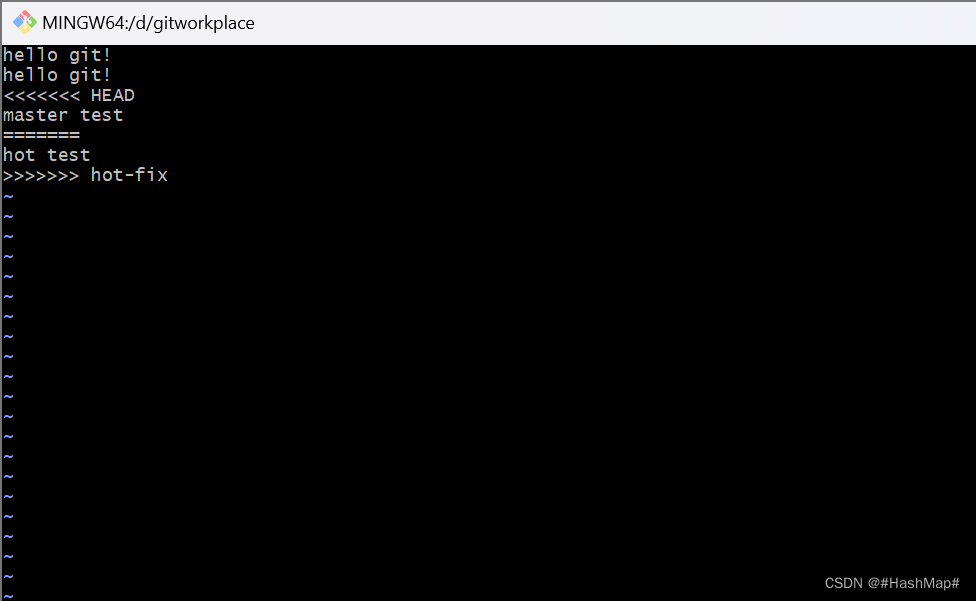
这里有一个易出现的问题---合并冲突。一般而言,我的理解就是有一个master和hot-fix分支,在master上进行了修改并执行git add和git commit命令然后切换到hot-fix分支进行修改内容然后执行add和commit操作,这时候进行merge就会产生冲突,简单的说就是master上进行了修改一般hot-fix没有在merge时
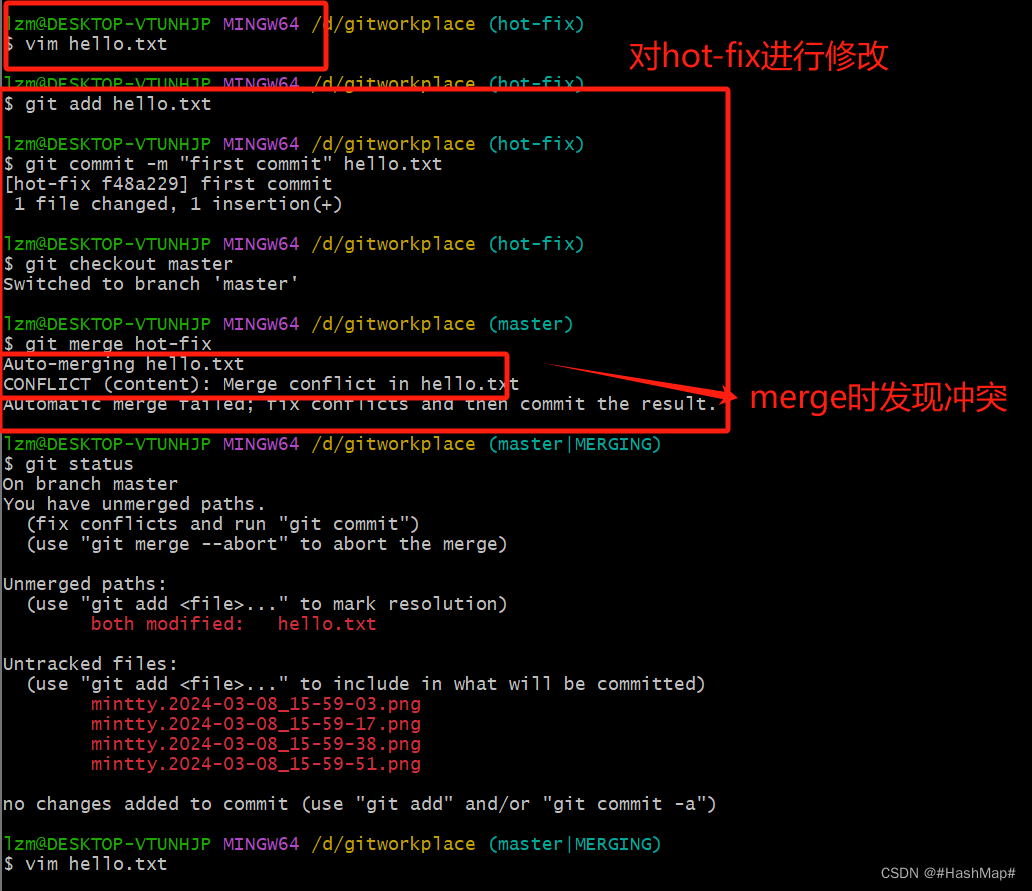
解决冲突的方法:把master里添加的内容保存,把hot-fix里的内容也保存,并把<<<和>>>以及===去掉

6.IDEA集成Git
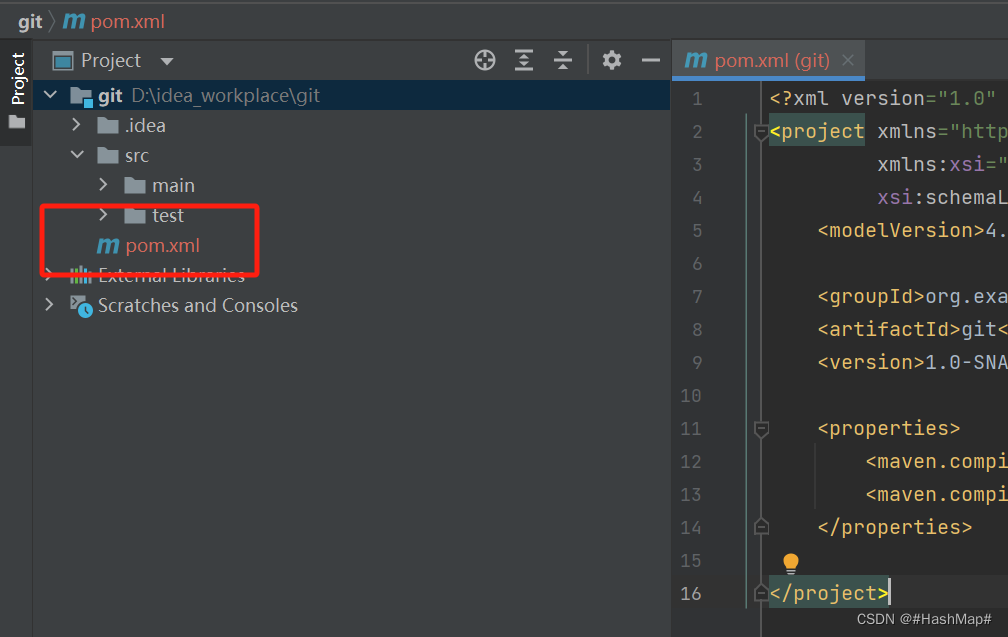
6.1 idea创建一个Maven工程,然后选择VCS里的Create Git Repository创建一个Git项目

6.2 创建之后文件会变红,和之前说的Git工作机制联系起来,这个时候红色文件在工作区需要add的,然后选择add

6.3 add之后发现文件变绿色,这时候在我们的暂存区,需要commit

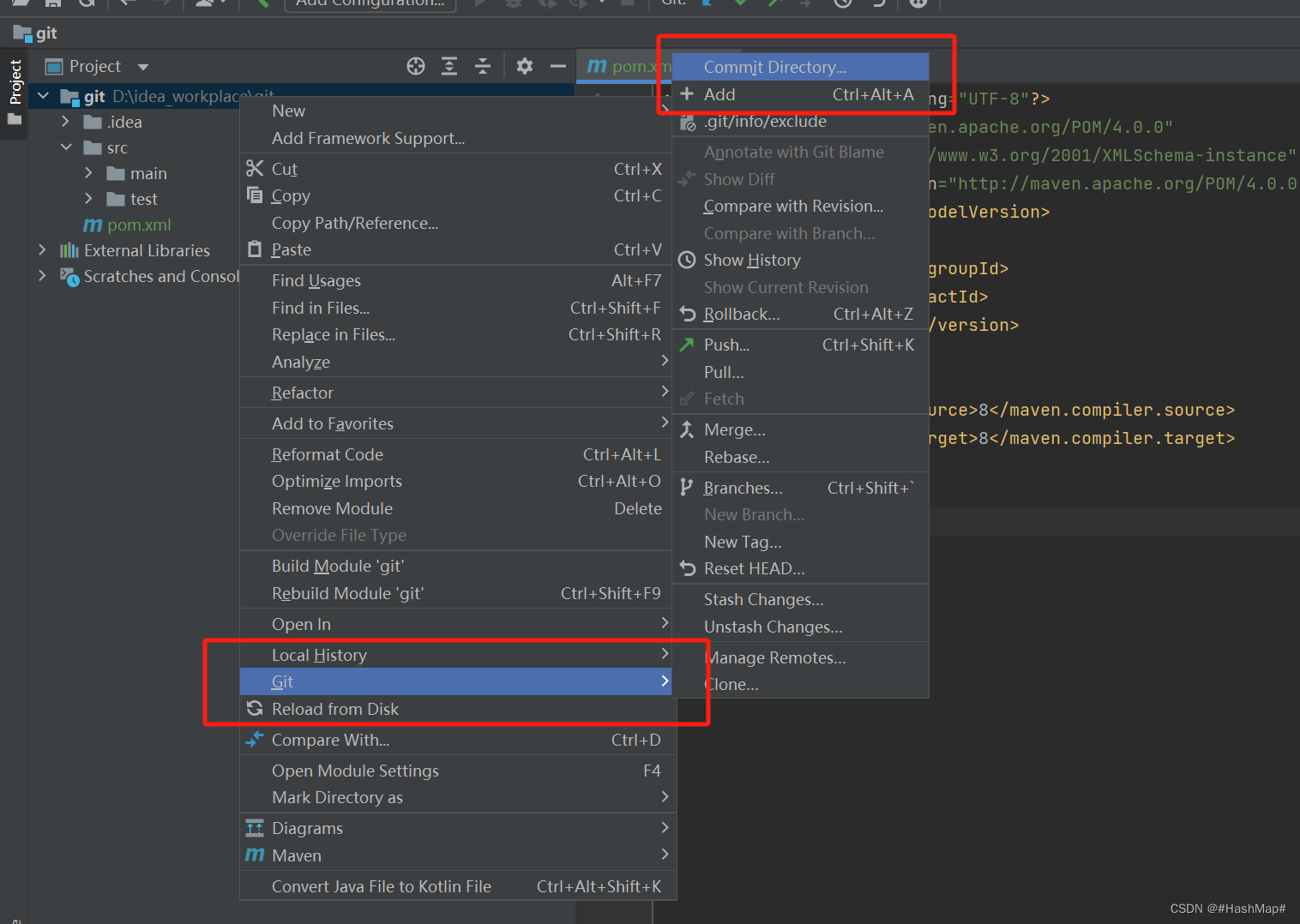

6.4 commit之后就添加到了本地库,此时发现文件颜色回复正常