电商网站运营js实现网站浮动窗口
1 概述
OpenHarmony 分布式任务调度是一种基于分布式软总线、分布式数据管理、分布式 Profile 等技术特性的任务调度方式。它通过构建一种统一的分布式服务管理机制,包括服务发现、同步、注册和调用等环节,实现了对跨设备的应用进行远程启动、远程调用、绑定/解绑,以及迁移等操作的支持。此外,分布式任务调度还能够根据设备的能力、位置、业务运行状态、资源使用情况,以及用户的习惯和意图,选择最合适的设备来运行分布式任务,从而提高了任务的执行效率和质量。
1.1 应用场景举例
比如在用户的日常出行中,一段路程往往需要使用不同的交通工具,例如:从家里出发去某公园露营,需要先开车到达公园到公园停车场,然后骑单车进入公园,最终可能还需要步行一段距离才可以到达目的地。在这个过程中,用户需要分别打开车载导航 APP 和手机的导航 APP,并分别输入起点和终点,最后才能完成一次出行导航。但是,借助于 OpenHarmony 分布式任务调度,可以将这些 APP 的功能进行整合,用户只需要在手机上输入起点和终点,然后点击出行按钮,借助于 OpenHarmony 分布式任务调度,应用就会根据使用场景自动地将导航信息流转到车机,手机,手表等不同的设备上。
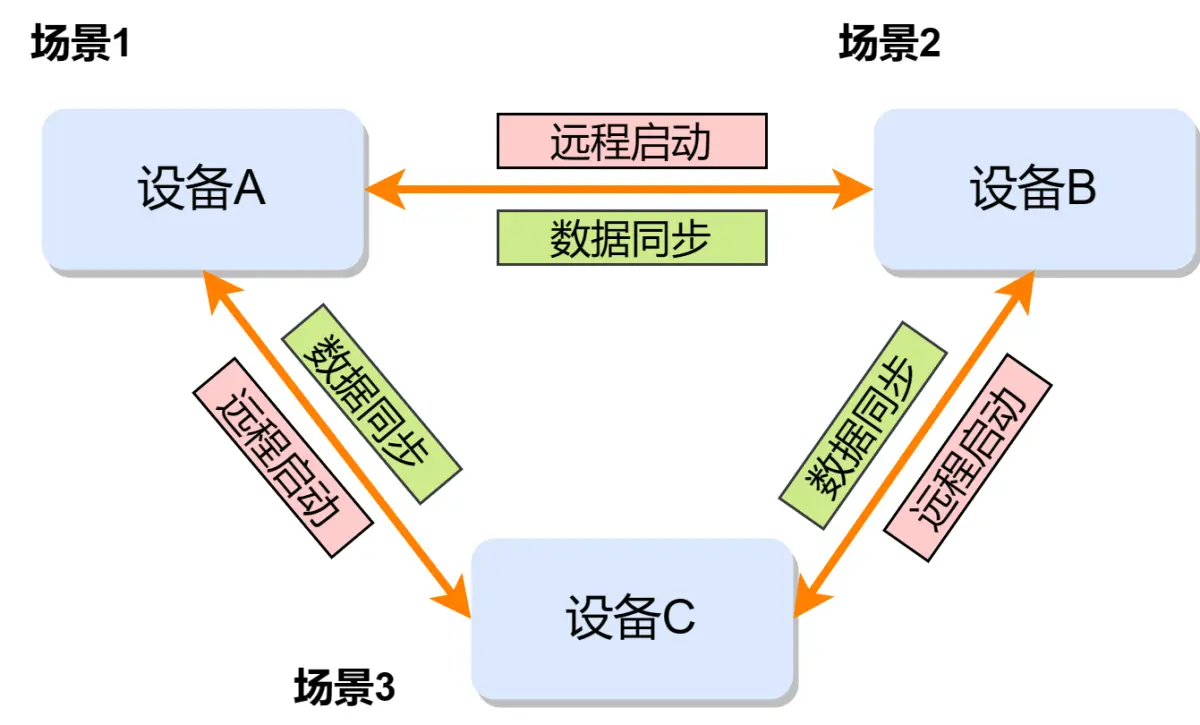
可以看到借助于 OpenHarmony 分布式任务调度,在物联网应用场景中可以实现设备间的资源共享,跨设备任务调度,从而创造出无限的可能性,提升用户的使用体验的同时,也提升了设备的使用效率。
1.2 系统架构
如图所示,分布式任务调度框架位于系统服务层,主要包括元能力子系统中的系统服务管理(safwk/samgr)和分布式组件管理部件(distributedsched)两个模块。其中,系统服务管理主要负责系统服务(SystemAbility)的启动、注册、发现、调用等功能。分布式组件管理主要负责分布式应用(Ability)调度的功能,包括元能力的远程绑定与调用、绑定关系的管理、分布式权限管理,元能力的远程启动与迁移等功能。

2 系统服务及其分布式特性
OpenHarmony 的系统服务通常是一个常驻内存的进程,它可以通过 IPC 或 RPC 的方式向其他进程提供相关的系统能力,比如分布式数据管理、设备认证等。按照启动方式大体可将系统服务分为两种,原生的可执行程序(如设备认证服务)和 SystemAbility(如分布式数据管理服务)。原生的服务通常比较底层,大多数使用 C 语言实现,其对应的编译目标也是可执行的二进制文件。比如 deviceauth_service,它是设备认证的系统服务,主要负责设备的认证和鉴权。这种类型的服务通常在系统启动的时候由 init 进程根据服务的配置文件(json 格式的文本文件)进行启动。
SystemAbility 则是由 samgr 统一管理的 so 库,一般采用 service.cfg + profile.xml + libservice.z.so 的方式由 init 进程根据对应的 service.cfg 文件拉起相关系统服务能力进程。cfg 配置文件为 linux 提供的 native 进程拉起策略,开机启动阶段由 init 进程解析该文件,调用 sa_main(profile.xml)加载服务的 so 库文件。profile.xml 是 SA 的描述文件,定义了服务的名称,so 文件路径等信息。
本文的分布式任务调度主要指的是 SystemAbility 类型的系统服务,因此主要介绍 SA 的相关内容。SA 类型的服务主要由 safwk 和 samgr 两部分组成,其中 safwk 定义了 SystemAbility 的实现方法,并且提供了 SystemAbility 的注册、调用等功能接口。samgr 则是 SystemAbility 的管理者,通过 IPC 通信接收到 safwk 的消息,完成服务注册,调用,加载 so 库等功能。下面将分别从服务的启动,实现等方面介绍两个模块的实现原理。

2.1 SA 启动流程
通过 samgr 管理的服务需要配置文件 service.cfg 和 profile.xml,参考下图。其中 name 字段为服务的名称,path 服务的启动路径。profile.xml 定义了服务的名称,so 文件路径等信息。需要注意的是,不同的 SA 可能会加载进同一个进程,因此 process 字段指定了要加载的进程名称,systemability 字段定义了 SA 相关的信息。也就是说一个 service 进程可以加载多个 SA 的 so 库。
SA 的启动流程如下:
- 在系统开机启动阶段,init 进程会解析 service.cfg 文件,根据配置的 path 字段,调 用 sa_main(profile.xml)启动服务。sa_main 是 safwk 中编译得到的可执行文件,是 SA 的 启动入口。其首先会对参数进行预处理,判断 profile.xml 路径,saId 等参数是否合法。
- 接着 sa_main 会调用 lsamgr 的 DoStartSAProcess()方法启动服务进程。lsamgr(Local SystemAbility Manager)是 safwk 框架中的内部组件,主要用于在 safwk 内部对服务进行管理,注意与 samgr 服务区别。
- DoStartSAProcess()首先解析 profile 文件,配置服务进程,SA 实例的名称,SaId 等属性,然后通过 IPC 调用 samgr 服务的 AddSystemProcess()方法将服务进程(本质上是一个绑定了服务相关信息的 lsamgr 实例)注册到 samgr,然后启动服务进程。
- SA 对应的系统进程启动之后,便需要加载启动 SA 自身。首先,samgr 调用 AddOnDemandSystemAbilityInfo(),将对应的 SA 实例与服务进程进行绑定,并准备启动对应的 SA。
- 启动 SA 需要再次调用 safwk 中 lsamgr 的 StartAbility()方法,该方法会加载 SA 对应的 so 库,并从中调用 SA 的 Start()方法,完成服务的启动。在 Start()方法中会触发钩子函数 OnStart()的调用,OnStart()通常由 SA 自己实现,用来完成其的初始化工作,并调用 Publish()发布 SA。
- 最后 Publish()方法会调用 samgr 的 AddSystemAbility()方法,将 SA 注册到 samgr 中。
至此,服务启动完成,可以对外提供服务了。
2.2 SA 的实现
SA 服务通过 IPC 通信向外提供服务,因此其除了需要继承 SystemAbility 外,实现其 OnStart()等方法外,还需要实现 IPC 通信框架。OpenHarmony 的 IPC 框架主要依赖下面几个类:
- IService:SA 服务的接口类,用来定义并描述服务的能力,该类需要继承 IRemoteBroker 类,并使用宏命令 DECLARE_INTERFACE_DESCRIPTOR 声明接口描 述符。该类是 IPC 通信双方的公共接口,因此需要将其放在公共的头文件中,以便于双方都可以使用。
- ServiceStub:SA 服务中 IPC 请求的接收类,该类需要同时继承 IService 和 IRemoteStub 类,并实现 IRemoteStub 类的 OnRemoteRequest 方法,该方法用来在接收 到 IPC 请求时处理请求。
- ServiceImpl:SA 服务的实现类,继承 ServiceStub 和 SystemAbility 类,实现 IService 接口中定义的方法,该类用来实现服务的具体功能,并且需要在 onStart 方法中调用 Publish 方法将服务发布出去。
- ServiceProxy:SA 服务的代理类,继承 IService 和 IRemoteProxy 类,并实现 IService 中定义的同名方法,该类通过 IRemoteProxy 类的 Remote()获取远程对象,并调用其 SendRequest()方法向 SA 服务的 Stub 类发送 IPC 请求。
当其他进程或应用需要调用该 SA 服务的功能时,首先需要调用 samgr 的 GetSystemAbility()方法获取服务的代理实例,即上述的 ServiceProxy 类的实例 proxy。然后调用 proxy 中的同名方法,该方法通过 Remote()->SendRequest()方法向 SA 服务的 ServiceStub 类发送 IPC 请求。在 ServiceStub 类的 OnRemoteRequest()方法中接收到相应的 IPC 请求,从中读取参数,然后调用服务实现类 ServiceImpl 的具体方法去处理实际的业务逻辑,完成最后将结果写回 IPC 请求。
下面我们通过实现一个简单的 HelloService 服务来说明如何向系统中添加一个 SA 服务。该服务通过 IPC 通信向外提供一个 SayHello 接口,该接口接收一个 string 类型的参数 name,然后生成字符串“Hello name”,将其通过 hilog 输出打印,并将结果返回给调用者。整体服务的类图如图。

其中 HelloService 对应上述的 ServiceImpl 类,HelloServiceClient 是服务的客户端,提供与服务同名的接口,在其中封装了获取服务代理对象以及调用代理类的同名接口,供外部程序调用。下面的流程图展示了外部进程调用该服务的流程。其中 GetProxy 方法会向 samgr 请求服务的代理实例,并通过接口转换函数 iface_cast 将其转换为自己进程内的 HelloServiceProxy 类型的实例 proxy,图中的虚线对应 IPC 通信,其具体的实现机制在此不在展开介绍。

2.3 分布式 SA
上述 SA 的启动及调用均为本地服务,下面来介绍 SA 服务的分布式特性,即本地设备调用其他设备的 SA 服务。注意,下文中的对端设备均指的是已经与本地设备完成组网认证的设备。分布式 SA 服务的启动与本地服务的启动类似,只需要在 SA 对应的 profile 文件中设置 distributed 属性为 true 即可。然后 SA 的 Publish()方法中会检查注册阶段保存的该属性,若为 true,则首先通过 IPC 框架的 dbinder_service 服务的 RegisterRemoteProxy()接口对该 SA 服务的 saId 进行注册。dbinder_service 服务会维护一个 map 类型的变量 mapRemoteBinderObjects_以记录本地对外提供的分布式服务对象。在服务注册及启动阶段,分布式 SA 与本地 SA 并无太多区别,真正实现 SA 的分布式特性实在服务的访问调用阶段。
如果本地设备需要调用对端设备 SA 服务的功能,则在获取 SA 代理时需要向 samgr 的 GetSystemAbility()方法同时传入 saId 和 deviceId。samgr 检测到客户端请求的是其他设备的 SA 服务实例时,会调用 IPC 框架的 dbinder_service 服务的 MakeRemoteBinder()方法来构建远程服务实例,该实例实际是一个指向 DBinderServiceStub 对象的指针。DBinderServiceStub 主要用来实现 RPC 通信,这里不过多介绍。MakeRemoteBinder()方法会构造一个 DBinderServiceStub 类的实例,并绑定远程 SA 服务的 saId 和 deviceId,然后记录在 DBinderStubRegisted_(一个 Vector 类型的变量)中。接着与对端设备建立软总线会话,并通过软总线发送 Entry 消息到对端设备,挂起线程等待回复。若能够收到回复,则证明远程服务已经启动,将 DBinderServiceStub 类的对象返回给 samgr,samgr 进一步返回给远程 SA 服务的请求者。请求者收到该对象后,将其作为参数构造 ServiceProxy 代理类对象 remoteProxy,之后的调用与本地 SA 服务调用类似,先调用 remoteProxy 中的同名接口,该接口通过 Reomte()->SendRequest()方法发送 RPC 请求(通过软总线)。SendRequest()的跨端实现属于 RPC 框架部分,此处不再赘述。
由上述分析可以看到,相比于本地的 SA,分布式 SA 不仅需要向 samgr 注册,还需要将其注册至 IPC/RPC 框架中以供后续跨设备调用。本地 SA 主要依赖于 IPC 通信提供服务,而分布式 SA 则通过 RPC(依赖于软总线)向其他设备提供服务。
3 分布式组件管理
系统服务 SA 的分布式特性主要供框架层使用,几乎不会直接提供给上层应用。而实际应用中支持分布式调度的任务特性多是由上层应用实现。比如多设备联动,用户应用程序的流转,实现如邮件跨设备编辑、多设备协同健身、多屏游戏等分布式业务。上层应用的分布式调度主要由分布式组件管理服务(DistributedSched)服务提供。DistributedSched 服务是 OpenHarmony 系统中的一个 SA,可以向其他进程提供分布式任务调度的相关接口。分布式任务调度框架是分布式任务调度的核心功能所在,包括元能力的远程启动、流转等功能。
DistributedSched 服务(dmsfwk 框架)主要包括两个模块,dtbabilitymgr 和 dtbschedmgr。dtbabilitymgr 主要负责元能力的分布式流转管理功能的实现,向上层应用提供流转管理的接口,也是 SA 服务的实例。dtbschedmgr 主要负责分布式任务调度的具体功能实现,包括元能力的远程启动,迁移,绑定等具体功能的实现。
需要注意的是,在 OpenHarmony3.2 版本中,dtbschedmgr 作为一个独立的 so 库,由 dtbabilitymgr 服务进程加载使用,但是在最新的 4.0 版本中,dtbschedmgr 作为一个独立的 SA 服务运行,两模块间通过 IPC 通信。
3.1 远程启动 Ability
Ability 的远程启动主要依赖 dtbschedmgr 模块,在介绍 dtbschedmgr 模块前我们先简单了解一下 OpenHarmony 的应用启动流程。通常,我们通过应用的上下文类 Context 的 StartAbility(want)方法启动新的 Ability。Want 是一种对象,用于在应用组件之间传递信息。例如,当 UIAbilityA 需要启动 UIAbilityB 并向 UIAbilityB 传递一些数据时,可以使用 Want 作为一个载体,将数据传递给 UIAbilityB。如图所示:

Want 类包含字段 deviceid,给字段指明了启动新的 Ability 的设备。若该字段为空则表示在本地启动,反之表示在字段指定的设备上启动。当 ability_runtime 框架判断需要处理的 want 的 deviceid 为其他设备时,便会调用 dtbschedmgr 的相关接口实现分布式的能力管理。
当 AbilityManager 服务需要远程启动 Ability 时,调用 DistributedSched 服务(dtbschedmgr 模块)的 StartRemoteAbility()方法处理远程启动的请求。StartRemoteAbility()方法首先会调用 samgr 的 GetSystemAbility()方法获取对端设备上的 DistributedSched 服务的代理对象 remoteProxy,这一步即是上文中提到的分布式 SA 服务的实现。然后设置 abilityInfo,callerInfo,accountInfo 等信息,并配置新的 want 对象。使用上述参数调用 remoteProxy(对端设备服务代理)的 StartAbilityFromRemote()方法。对端设备的 DistributedSched 服务收到请求后,会调用其 StartAbilityFromRemote()方法,通过本地的 AbilityManager 服务启动本地 Ability。具体流程参考下图。

3.2 Ability 流转
在 OpenHarmony 中,流转泛指跨多设备的分布式操作。流转能力打破设备界限,多设备联动,使用户应用程序可分可合、可流转,实现如邮件跨设备编辑、多设备协同健身、多屏游戏等分布式业务,如本章引言中提到的智能家居中视频播放流转及多场景导航应用的使用。流转为开发者提供更广的使用场景和更新的产品视角,强化产品优势,实现体验升级。流转按照使用场景可分为跨端迁移和多端协同。
跨端迁移指在用户使用设备的过程中,当使用情境发生变化时(例如从客厅走到卧室或者周围有更合适的设备等),之前使用的设备可能已经不适合继续当前的任务,此时,用户可以选择新的设备来继续当前的任务,原设备退出任务,这就是跨端迁移场景。常见的跨端迁移场景实例:在平板上播放的视频,迁移到智慧屏继续播放,从而获得更佳的观看体验;平板上的视频应用退出。在应用开发层面,跨端迁移指在 A 端运行的 UIAbility 迁移到 B 端上,完成迁移后, B 端 UIAbility 继续任务,而 A 端 UIAbility 退出。
多端协同指用户拥有的多个设备,可以作为一个整体,为用户提供比单设备更加高效、沉浸的体验,这就是多端协同场景。常见的多端协同场景实例:平板侧应用 A 做答题板,智慧屏侧应用 B 做直播,为用户提供更优的上网课体验。在应用开发层面,多端协同指多端上的不同 UIAbility/ServiceExtensionAbility 同时运行、或者交替运行实现完整的业务;或者多端上的相同 UIAbility/ServiceExtensionAbility 同时运行实现完整的业务。一次多端协同的流程大体如下图所示:

由于在最新的 OpenHarmony 版本中(4.0)跨端迁移及多端协同的能力尚未具备,开发者当前只能开发具备跨端迁移能力的应用,但不能发起实际迁移。虽然流转功能的 NAPI 接口尚未完全实现,但其基本的流程和上述的远程启动流程类似,本地设备的 DistributedSched 服务的在 ContinueRemoteMission()接口中远程调用对端设备的 DistributedSched 服务的 ContinueMission()接口,从而实现流转功能。
流转功能的实现大体可分为两步,首先远程启动对端设备的 Ability,然后同步本地设备的 Ability 的状态及数据至对端,从而实现流转。目前数据同步功能尚未完善,但是在应用层可通过分布式数据管理(KVDB 或 RDB)的相关接口实现数据的同步。这里可以参考 OpenHarmony 官网上的应用示例:
- 跨端迁移:分布式音乐播放器
- 多段协同:分布式计算器
4 小结
本文带领读者了解分布式任务调度的基本概念和应用场景。结合 OpenHarmony3.2 源代码,简要介绍了分布式任务调度的实现原理和核心代码框架。了=包括 SystemAbility 的启动流程和实现原理,以及如何结合 SA 与 IPC 框架以向其他进程提供服务。在此基础上,介绍了分布式组件管理服务 DistributedSched 服务的实现原理,包括远程启动 Ability 和流转功能的实现。通过上述介绍,读者可以更深入地理解分布式任务调度的具体实现方式,以及其在实际应用开发中的使用。
为了能让大家更好的学习鸿蒙(HarmonyOS NEXT)开发技术,这边特意整理了《鸿蒙开发学习手册》(共计890页),希望对大家有所帮助:https://qr21.cn/FV7h05
《鸿蒙开发学习手册》:
如何快速入门:https://qr21.cn/FV7h05
- 基本概念
- 构建第一个ArkTS应用
- ……
开发基础知识:https://qr21.cn/FV7h05
- 应用基础知识
- 配置文件
- 应用数据管理
- 应用安全管理
- 应用隐私保护
- 三方应用调用管控机制
- 资源分类与访问
- 学习ArkTS语言
- ……

基于ArkTS 开发:https://qr21.cn/FV7h05
- Ability开发
- UI开发
- 公共事件与通知
- 窗口管理
- 媒体
- 安全
- 网络与链接
- 电话服务
- 数据管理
- 后台任务(Background Task)管理
- 设备管理
- 设备使用信息统计
- DFX
- 国际化开发
- 折叠屏系列
- ……

鸿蒙开发面试真题(含参考答案):https://qr18.cn/F781PH

鸿蒙开发面试大盘集篇(共计319页):https://qr18.cn/F781PH
1.项目开发必备面试题
2.性能优化方向
3.架构方向
4.鸿蒙开发系统底层方向
5.鸿蒙音视频开发方向
6.鸿蒙车载开发方向
7.鸿蒙南向开发方向
