网站返利二维码怎么做asp网站域名授权
对于Mac用户来说,可能会遭遇一些烦恼,比如在试图将文件从Mac电脑拖入U盘时,却发现文件无法成功传输。这无疑给用户带来了很大的不便。那么,mac文件为什么不能拖进U盘,看完这篇你就知道了。

一、U盘的读写权限问题
如果U盘的读写权限不正确,那么就无法向U盘写入文件。想要解决这个问题,可以右击磁盘选择“查看简介”,将当前用户的权限更改为“读与写”。
Tuxera NTFS2023下载如下:
https://wm.makeding.com/iclk/?zoneid=54348

如果你无法向U盘写入文件,可能是因为U盘的读写权限设置不正确。你可以进行以下步骤来解决这个问题:
-
在桌面上找到U盘的图标,右键点击它。
-
在弹出的菜单中选择“查看简介”(或类似选项,具体名称可能有所不同)。
-
在弹出的窗口中,找到“共享与权限”(或类似选项)。
-
找到当前用户的权限设置,通常以用户名显示。
-
确保权限设置为“读与写”(或类似选项)。如果没有写权限,你可能只能看到“只读”或“无”等选项。
-
如果权限不正确,点击锁形图标来进行更改。输入管理员密码以确认权限更改。
-
将权限设置为“读与写”,以允许你向U盘写入文件。
-
关闭窗口,然后尝试将文件拖拽到U盘上,看看是否能够成功写入。
二、U盘的文件系统不兼容
对于Mac电脑来说,U盘的文件系统非常关键。如果U盘的文件系统与Mac不兼容,你就无法在Mac电脑上进行文件写入操作。大部分U盘使用的是FAT32文件系统,这种文件系统可以在Windows和Mac上读写,但由于一些限制(如单个文件大小不能超过4GB),很多人选择使用NTFS文件系统。然而,Mac电脑本身不原生支持NTFS格式,所以需要安装像Tuxera NTFS for Mac这样的磁盘读取软件才能实现对NTFS格式U盘的读写支持。
简单来说,如果你的U盘是NTFS格式的,你需要安装额外的软件才能在Mac上读写它。否则,就需要将U盘格式化为兼容的文件系统(如FAT32或exFAT),这样你就可以直接在Mac上进行文件的拷贝、移动或写入操作了。
三、文件损坏或错误
有时候文件本身可能会损坏或出现错误,这会导致无法正确地将文件传输到U盘中。为了解决这个问题,你可以尝试以下方法:
1、使用另一个U盘:如果你怀疑当前使用的U盘有问题,可以尝试使用另一个U盘来进行文件传输。有时候U盘本身可能出现故障或损坏,导致无法正确写入文件。
2、重新下载文件:如果你已经确定文件本身存在问题,可能是下载过程中出现错误或文件被损坏,那么尝试重新下载文件。确保从可靠的来源下载文件,并检查文件完整性。
3、使用磁盘工具软件:如果你安装了像Tuxera NTFS for Mac这样的软件,它提供了磁盘检查和修复的功能。通过打开软件并选择相应的U盘,你可以运行磁盘检查来查找和修复可能存在的磁盘错误或损坏。
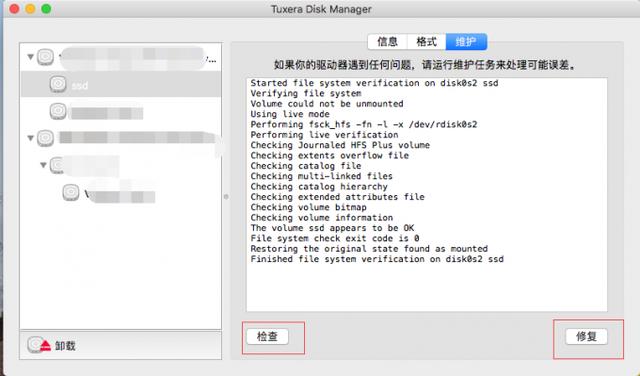
以上内容就是关于mac文件为什么不能拖进U盘的相关介绍,如果您还在为数据丢失而烦恼,不妨尝试上述的方法来找回自己的数据,也可以在评论区进行留言,小编会第一时间帮您解决!