山东省建设厅注册中心网站一级域名与二级域名有啥区别
Playables
一、Playable Director:是一种用于控制和管理剧情、动画和音频的工具。它作为一个中央控制器,可以管理播放动画剧情、视频剧情和音频剧情,以及它们之间的时间、顺序和交互。
Playable Director组件具有以下作用:
剧情控制:Playable Director可以用于控制和管理剧情的播放。通过指定剧情的Timeline(时间轴)或Animation(动画)资源,Playable Director可以按照预定义的时间表触发和操纵对象的动作和属性变化。它实现了在给定时间范围内按照需求展示和控制游戏中的剧情。
动画控制:Playable Director可以用于控制和播放动画。它支持Unity的Animation系统以及Timeline系统,可以控制对象的动画剪辑、关键帧和过渡。可以通过Playable Director来指定动画的播放速度、循环设置和动画间的过渡方式,实现复杂的动画序列和交互。
音频控制:Playable Director也可以用于控制和管理音频的播放。通过添加和配置Audio Clips(音频剪辑),Playable Director可以触发和控制游戏中的音效和背景音乐。您可以在时间轴上设置音频剪辑的触发时间和长度,以实现动态的音频播放和交互。
交互设计:Playable Director还支持交互设计,允许您在游戏运行时根据玩家的输入或特定条件动态切换剧情、动画和音频的播放。通过编写脚本,您可以在Playable Director上监听事件,根据特定条件或触发器切换到不同的时间轴、动画或音频。

Playable(可播放):定义了要在Playable Director上播放的Playable对象。这可以是Animation Clip、Timeline、Playable Asset等。
Update Method(更新方法):定义了Playable Director的更新方式。可以选择以下选项:
(1)DSP Clock:会在音频引擎中以固定的速率进行更新,独立于游戏时间和帧率。这意味着Playable Director的更新将与音频引擎的更新同步,使得音频和动画同步播放。
(2)Game Time:游戏时间是以游戏时间轴为基准的相对时间,会受到Time Scale(时间缩放)影响。这意味着在游戏暂停或时间缩放时,Playable Director的更新也会相应地受到影响。
(3)Unscaled Game Time:与Game Time不同,Unscaled Game Time不受Time Scale的影响,始终以实际时间的速度进行更新。这意味着即使在游戏暂停或时间缩放时,Playable Director的更新速度也不会改变。
(4)Manual:选择Manual更新方法时,Playable Director将不会自动更新,需要通过脚本代码手动调用Play() 方法或Evaluate() 方法来控制其更新。这可以用于实现自定义的时间控制和特定的更新逻辑。
Play On Awake(自动播放):定义了Playable Director在启用时是否自动播放。可以选择是或否。如果设置为是,则Playable Director将在场景启动时自动开始播放。
Wrap Mode(循环模式):定义了Playable Director的循环模式。可以选择以下选项:
(1)Hold:选择Hold循环模式时,可播放资源会在播放结束时保持最后一个关键帧的状态。换句话说,可播放资源在最后一帧上停留,并持续显示该帧的内容,直到切换到其他帧或停止播放。
(2)Loop:选择Loop循环模式时,可播放资源会在播放结束时循环回到开始处,无限循环播放。这意味着资源将按照循环周期不断重复播放,直到停止或切换到其他帧。
(3)None:选择None循环模式时,可播放资源将在播放结束后立即停止,不会循环播放或保持任何特定的状态。资源将在播放到最后一帧后停止,并停留在该帧的状态。
Initial Time(初始时间):定义了Playable Director初始的播放时间。可以手动设置时间点来决定播放的起始位置。
Bindings(绑定):允许在Playable Director和Playable对象之间进行绑定。通过将数据和参数绑定到Playable对象上,可以在播放过程中动态修改和控制对象的属性。
Rendering
一、Camera:控制摄像机的视觉效果和行为

Clear Flags(清除标志):定义了相机在每帧渲染前是否要清空画布。选项包括:
(1)Skybox(使用天空盒清除画布)
(2)Solid Color(使用指定的颜色清除画布)
(3)Depth Only(只清除深度缓冲)
(4)Don’t Clear(不清除画布)
Background(背景):定义了相机的背景颜色。可以选择使用颜色来填充背景(在Clear Flags为Solid Color下起效果)
Culling Mask(剔除层):定义了相机渲染的层级。通过勾选或取消勾选特定层级,可以控制相机渲染哪些对象。
Projection(投影方式):定义了相机的投影方式。可以选择透视投影(Perspective)或正交投影(Orthographic)。
FOV Axis(视野轴)/ Field of View(视野角度):FOV Axis 属性和 Field of View 属性用于定义透视投影相机的视野范围。Field of View 表示视野的角度,用于确定相机可视区域的大小。FOV Axis 则指定了角度测量的屏幕轴
Physical Camera(物理相机):允许使用真实世界相机的参数来设置 Unity 相机。通过启用 Physical Camera 属性,你可以模拟真实相机的参数,如光圈、感光度和快门速度等。
Clipping Planes(裁剪平面):定义了相机的近裁剪面和远裁剪面的距离。在这个距离之外的物体将在渲染过程中被剪裁掉。
Viewport Rect(视口矩形):定义了相机在屏幕上的矩形位置和大小。可以使用这个属性来控制相机渲染到屏幕的区域。
Depth(渲染顺序):定义了相机的渲染顺序。渲染按照深度值进行排序,深度值小的先渲染。
Rendering Path(渲染路径):定义了相机的渲染路径。可选的渲染路径包括 Forward(正向渲染)和 Deferred(延迟渲染)等。
Target Texture(目标纹理):定义了渲染结果输出到指定的纹理上,而不是直接输出到屏幕上。这可以用于创建屏幕后处理效果或者将渲染结果传递给其他渲染流程。
Occlusion Culling(遮挡剔除):允许根据相机的视锥体内的物体之间的遮挡关系进行剔除,以提高渲染性能。
HDR(高动态范围):允许在渲染过程中使用高动态范围的颜色,以获得更好的光照效果和色彩范围。
MSAA(多重采样抗锯齿):允许在渲染过程中使用多重采样抗锯齿来减少锯齿和平滑边缘。
Allow Dynamic Resolution(动态分辨率):允许在运行时根据性能需要动态调整相机的分辨率,以平衡画面质量和性能。
Target Display(目标显示器):定义了相机在多显示器设置中输出到目标显示器的索引。
二、Canvas Renderer组件:是UI元素渲染的核心组件,负责将UI元素转化为渲染指令,并控制材质、着色器、排序和遮罩等渲染相关的设置。它为UI元素的显示提供了必要的功能和控制。

Cull Transparent Mesh:用于控制在透明网格绘制过程中的裁剪行为。它影响绘制透明的UI元素的可见性和性能表现。
注:当Cull Transparent Mesh属性设置为true时,Canvas Renderer会在绘制透明网格时进行裁剪。这意味着,如果透明网格的可见性被完全遮住或超出了屏幕视图范围,将不会为其执行渲染操作。这样可以减少不可见区域的渲染开销,提高性能。相反,当Cull Transparent Mesh属性设置为false时,Canvas Renderer会忽略透明网格的可见性,始终进行绘制操作。这可能会导致在不可见或超出屏幕的区域进行不必要的渲染,从而降低性能。通常情况下,对于大部分透明的UI元素,可以将Cull Transparent Mesh属性设置为true以获得更好的性能。但是如果你希望即使在屏幕外也保持透明网格的绘制,你可以将其设置为false。但是,Cull Transparent Mesh属性只影响透明网格的渲染行为,对于完全不透明的网格(如图片或文本等),该属性不会产生影响
三、Flare Layer:用于在渲染摄像机视图时添加光晕效果,以增强场景中光源的可视效果。光晕效果是由光源经过镜头折射和扩散产生的视觉效果。使用 Flare Layer 组件可以模拟这种效果,并在渲染摄像机的最后一步中添加光晕。
![]()
Flare Layer 组件可以在渲染摄像机的所有全屏效果之后应用,但在 UI 前面。它将光晕效果叠加在最终的图像上,以增强光源的外观,使其更加真实和吸引人。
四、Light:用于在场景中模拟光照效果的组件
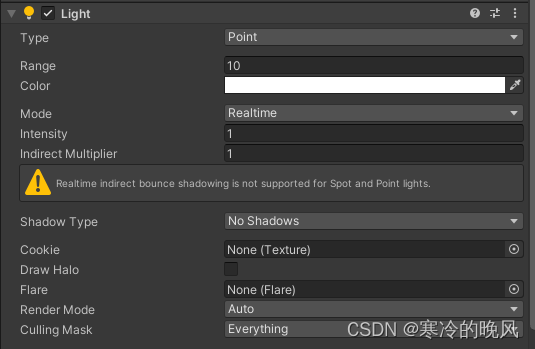
Type(类型):定义了光源的类型,可以选择以下选项:
(1)Spot(聚光灯): Spot光源模拟了一个可以在特定方向上发射光束的聚光灯。通过设置灯光的位置、方向、角度和范围等属性,可以控制聚光灯的照射区域和光照强度。Spot光源经常用于模拟聚光灯、手电筒或景观中的远距离照明效果。
(2)Directional(平行光): Directional光源模拟了类似太阳光的平行光照射效果。它没有具体的位置,而是以指定的方向均匀照射场景中的所有对象。Directional光源的光照是平行且无穷远的,例如模拟室外场景的阳光。它没有明确定位的位置和角度,而是通过方向矢量来定义其照射角度和强度。
(3)Point(点光源): Point光源模拟了从特定位置向周围全方向发射的光源。通过设置灯光的位置和范围,可以确定点光源的照射位置和强度。点光源可用于模拟室内场景中的灯泡、火焰或其他局部照明效果。
(4)Area(面光源,仅用于烘焙): Area光源是用于烘焙光照贴图的一种特殊类型的光源。它模拟了区域光源,例如矩形或圆形面板的光照效果。Area光源一般用于烘焙光照贴图(lightmapping)场景,对实时渲染无效。
Range(范围):定义了光源的影响范围,决定了光源的照射距离。
Color(颜色):定义了光源的颜色。
Mode(模式):用于指定灯光的工作模式,也就是灯光的计算和渲染方式,可以选择以下选项:
(1)Realtime(实时模式):选择Realtime模式时,灯光会在运行时实时计算和渲染。这意味着灯光会动态影响场景中的实时渲染对象,光照效果会随着时间和物体位置的变化而实时更新。Realtime模式适用于需要实时计算和动态光照的情况,但在性能开销较大。
(2)Mixed(混合模式):选择Mixed模式时,灯光将使用烘焙的光照贴图(Lightmap)进行预计算,并将其与实时计算和渲染结合使用。这意味着灯光会在场景启动时进行预计算,生成Lightmap,然后在运行时应用实时光照计算。Mixed模式适用于在保持一定的实时灵活性的同时获得更好的性能和光照质量。
(3)Baked(烘焙模式):选择Baked模式时,灯光将完全使用烘焙的光照贴图进行渲染。烘焙模式通过提前计算光照,将结果保存在静态的光照贴图中,不进行实时计算。这意味着光照效果不会根据物体的移动或时间的变化而改变。Baked模式适用于静态场景或不需要实时光照计算的情况,能够获得较高的性能和光照质量。
Intensity(强度):定义了光源的强度,用于调整光源的亮度。
Indirect Multiplier(间接光照倍数):定义了间接光照(全局光照)的强度倍数。
Shadow Type(阴影类型):定义了光源投射的阴影类型,可以选择以下选项:
(1)No Shadows(无阴影):该光源不会投射阴影。
(2)Hard Shadows(硬阴影):投射出硬边的阴影。
(3)Soft Shadows(软阴影):投射出柔和的阴影。
Cookie(贴图):定义了光源投射阴影的贴图。
Draw Halo(绘制光晕):决定了光源是否绘制光晕效果。
Flare(光晕):定义了光源的光晕效果。
Render Mode(渲染模式):定义了渲染光源的方式,可以选择以下选项:
(1)Auto(自动):根据设置自动选择最佳渲染模式。
(2)Important(重要):使用更高的质量并消耗更多性能。
(3)Not Important(不重要):使用更低的质量以获得更好性能。
Culling Mask(剔除层):定义了光源影响的层级。只有被勾选的层级才会受到光源影响。
五、Light Probe Group:用于在场景中放置和管理光探针的组件

Edit Light Probes按钮:点击之后才可以编辑下面的属性
Show Wireframe(显示线框):用于控制光探针的线框显示。如果勾选此选项,将在场景中显示光探针的线框,以便更好地可视化其位置和覆盖范围。
Remove Ringing(消除震铃效果):用于控制光探针的震铃效果。勾选此选项将应用去除震铃滤波器,用于减少光探针产生的震铃伪影。
Selected Probe Position(所选光探针位置):显示了所选光探针的位置。
Add Probe按钮(添加光探针):用于在 Light Probe Group 组件中添加新的光探针。单击此按钮后,在当前光探针组中创建一个新的光探针,并将其位置设置为场景中鼠标指针的位置。
Select All按钮(全选):用于选择 Light Probe Group 组件中的所有光探针。单击此按钮后,将选中所有光探针,可以对它们进行批量操作。
Delete Selected按钮(删除所选):用于删除 Light Probe Group 组件中的所选光探针。单击此按钮后,将删除选中的光探针,从光探针组中移除它们。
Duplicate Selected按钮(复制所选):用于复制 Light Probe Group 组件中的所选光探针。单击此按钮后,将复制选中的光探针,创建它们的副本,并将其位置稍微偏移以示区分。
六、Light Probe Proxy Volume:用于定义场景中光探针代理体积的属性

Refresh Mode(刷新方式):定义了光探针代理体积的刷新方式,可以选择以下选项:
(1)Automatic(自动):在场景发生变化时自动刷新光探针代理体积。
(2)Every Frame(每帧):每帧都刷新光探针代理体积。
(3)ViaScripting(通过脚本):通过脚本手动控制何时刷新光探针代理体积。
Quality(质量):定义了光探针代理体积的质量级别,会影响光探针的数量和分辨率。
Data Format(数据格式):定义了光探针代理体积的数据格式,可以选择以下选项:
(1)Half-Float(RG8):使用 RG8 格式存储光探针数据。
(2)Float (RG16):使用 RG16 格式存储光探针数据。
Bounding Box Mode(边界框模式):定义了光探针代理体积的边界框计算方式,可以选择以下选项:
(1)Auto(自动):根据场景中的光探针位置自动计算边界框。
(2)Custom(自定义):手动设置边界框的大小。
Proxy Volume Resolution(代理体积分辨率):定义了光探针代理体积的分辨率。分辨率值越高,代理体积包含的光探针数量越多,但会增加计算开销。
Resolution Mode(分辨率模式):定义了光探针的分辨率模式,可以选择以下选项:
(1)Automatic(自动):根据光探针代理体积分辨率自动设置光探针的分辨率。
(2)Custom(自定义):手动设置光探针的分辨率。
Density(密度):定义了光探针在代理体积中的密度(每单位体积中的光探针数量)。密度值越高,光探针的分布越密集。
Probe Position Mode(光探针位置模式):定义了光探针的位置模式
七、LOD Group:用于管理物体的层次细节(LOD)设置,以在不同距离上呈现不同细节级别的模型。使用 LOD Group 组件,你可以设置不同距离下的 LOD 级别,根据距离自动切换和显示不同细节级别的模型。这允许在远离摄像机时使用简化的模型,以提高性能,而在接近摄像机时使用更详细的模型,以保持视觉质量。
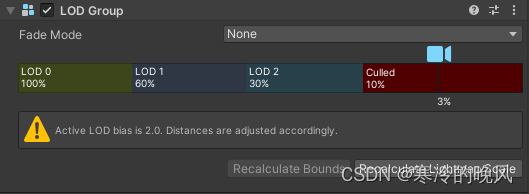
Fade Mode(淡出模式):定义了切换 LOD 级别时的淡出效果方式,可以选择以下选项:
(1)None(无):LOD 切换时没有淡出效果。
(2)Cross Fade(交叉淡出):使用淡出效果在 LOD 级别之间平滑过渡。
(3)SpeedTree(SpeedTree):使用 SpeedTree 的淡出效果在 LOD 级别之间平滑过渡。
LOD 0, LOD 1, LOD 2 等:这些属性用于指定不同 LOD 级别下的模型。每个 LOD 属性可以设置一个模型,并指定该模型在一定距离下被使用。
Culled(剔除):Culled 属性定义了物体在所有 LOD 都被剔除(隐藏)时是否完全剔除。如果选择了 Culled,则当 LOD Group 的所有 LOD 都被剔除时,物体将不再被渲染或占用任何性能。
八、Occlusion Area:用于定义遮挡区域,以在渲染过程中进行遮挡剔除优化。使用 Occlusion Area 组件,你可以标记和定义遮挡区域,在渲染过程中减少对已被遮挡物体的渲染,从而提高性能。遮挡区域的大小、中心和是否作为视图体积参与计算,取决于场景的需求和优化目标。

Size(大小):定义了遮挡区域的大小(体积)。可以通过调整三维向量的值来设置遮挡区域的宽度、高度和深度。
Center(中心):定义了遮挡区域的中心位置。可以通过调整三维向量的值来设置遮挡区域的中心位置。
Is View Volume(是否为视图体积):定义了遮挡区域是否用作视图体积。如果勾选了 Is View Volume,则表示该遮挡区域将用于进行遮挡剔除和确定可见物体,根据其位置和相机的视野进行计算。如果未勾选 Is View Volume,则表示该遮挡区域只用于遮挡剔除,但不参与确定可见物体。
九、Occlusion Portal:用于定义遮挡门,以在渲染过程中优化可见性。使用 Occlusion Portal 组件,你可以标记和定义遮挡门,以在渲染过程中优化可见性。可以将遮挡门放置在场景中的墙壁、门以及其他可见物体之间,通过开启或关闭遮挡门来控制可见性。遮挡门的中心位置和大小可以根据场景需求进行调整,以确保正确的遮挡效果。

Open(开启状态):定义了遮挡门的开启状态。如果勾选了 Open,则表示遮挡门是打开的,允许从遮挡门的一侧看到另一侧。如果未勾选 Open,则表示遮挡门是关闭的,将阻止从一侧看到另一侧。
Center(中心):定义了遮挡门的中心位置。可以通过调整三维向量的值来设置遮挡门的中心位置。
Size(大小):定义了遮挡门的大小(体积)。可以通过调整三维向量的值来设置遮挡门的宽度、高度和深度。
十、Reflection Probe

Type(类型):定义了反射探针的类型,可以选择以下选项:
(1)Baked(烘焙):在编辑模式下烘焙静态场景的反射信息,不支持实时更新。
(2)Custom(自定义):手动设置反射探针的参数和更新方式。
(3)Runtime(实时):定义了实时更新反射探针的参数和方式。
Runtime Settings
Importance(重要性):定义了反射探针在场景中的重要性,影响更新频率和性能开销。较高的重要性表示探针更频繁地更新。
Intensity(强度):定义了反射探针的亮度。可以调整该值来增加或减少反射的强度。
Box Projection(盒投影):定义了反射探针是否使用盒投影来捕捉反射信息。
Blend Distance(混合距离):定义了反射探针之间相互混合的距离。当多个反射探针的影响区域相交时,可以使用混合距离来实现平滑过渡。
Box Size(盒子尺寸):定义了反射探针影响区域的尺寸。以盒式体积的形式设置,可以通过调整三维向量的值来设置其宽度、高度和深度。
Box Offset(盒子偏移):定义了反射探针盒子相对于其位置的偏移量。通过调整三维向量的值,可以将盒子相对于探针位置进行位移。
Cubemap Capture Settings
Resolution(分辨率):定义了捕捉的立方体贴图的分辨率。较高的分辨率可以获得更高质量的反射,但也会增加内存和计算开销。
HDR(高动态范围):定义了是否使用高动态范围(HDR)格式来捕捉反射信息。启用 HDR 可以更准确地表示亮度范围较大的场景。
Shadow Distance(阴影距离):定义了反射探针用于渲染阴影的最大距离。超出此距离的阴影将不会被渲染到反射探针的立方体贴图中。
Clear Flags(清除标志):定义了立方体贴图是否应该被清除。可以选择以下选项:
(1)Skybox:清除立方体贴图时使用天空盒。
(2)Solid Color:清除立方体贴图时使用纯色。
Background(背景):定义了立方体贴图的背景色。
Culling Mask(剔除遮罩):定义了反射探针可以看到的物体的层级遮罩。只有被勾选的层级将被包含在反射探针的渲染中。
Use Occlusion Culling(使用遮挡剔除):定义了是否启用遮挡剔除来优化渲染。如果勾选了此选项,反射探针将采用遮挡剔除来排除不可见物体的渲染。
Clipping Planes(裁剪平面):定义了立方体贴图的裁剪平面。可以设置近裁剪面和远裁剪面,以限定立方体贴图捕捉的渲染空间范围。
十一、Skybox:用于渲染场景的天空盒

Custom Skybox:允许你使用自定义的材质为天空盒背景。Material(材质)定义了自定义天空盒的材质。你可以拖拽一个合适的材质到这个属性上,该材质将被用于渲染天空盒。这个材质应该是一个使用立方体贴图作为纹理的材质(可以使用 Skybox Shader 或 Cubemap Shader)。
十二、Sorting Group:用于控制对象在渲染中的绘制顺序

Sorting Layer(排序层):定义了对象所在的渲染层。渲染器根据排序层来确定对象的绘制顺序。较高的排序层将在较低的排序层之上绘制。可以通过在 Inspector 面板中的 Sorting Layer 下拉菜单中选择或创建不同的排序层。
Order in Layer(层中的顺序):定义了对象在所属排序层中的绘制顺序。较高的 Order in Layer 值将在较低的 Order in Layer 值之上绘制。可以通过在 Inspector 面板中直接调整 Order in Layer 字段的值来修改绘制顺序。
十三、Sprite Renderer

Sprite(精灵):定义了要在精灵渲染器中显示的精灵图像。可以通过拖拽精灵资源到该属性上来选择要渲染的精灵。
Color(颜色):定义了精灵的颜色。通过调整 R、G、B 和 Alpha 通道的值可以改变精灵的呈现颜色。Alpha 值控制精灵的透明度。
Flip(翻转):允许你以水平和垂直方向翻转精灵的渲染。可以单独控制水平翻转和垂直翻转两个方向。
Draw Mode(绘制模式):定义了精灵的绘制模式。可以选择以下选项:
(1)Simple:以默认方式绘制精灵。
(2)Tiled:在指定的区域内平铺绘制精灵。
(3)Sliced:根据九宫格切割方式绘制精灵。
Mask Interaction(遮罩交互):定义了精灵渲染器与遮罩(Mask)组件的交互方式。可以选择以下选项:
(1)Visible Inside Mask:精灵将在遮罩内部可见。
(2)Visible Outside Mask:精灵将在遮罩外部可见。
Sprite Sort Point(精灵排序点):定义了 Sprite Renderer 在场景中的排序点。可以选择以下选项:
(1)Pivot:使用精灵的 Pivot 点进行排序。
(2)Center:使用精灵的中心点进行排序。
Material(材质):定义了用于渲染精灵的材质。材质决定了精灵的外观和渲染效果。
Additional Settings(附加设置):
Sorting Layer(排序层):定义了精灵的绘制层级。
Order in Layer(层中顺序):定义了在同一排序层中的绘制顺序。
十四、Streaming Controller:用于管理场景资源加载和卸载的组件

Mip Map Bias:Mipmaps是一组预先生成的纹理,用于在远离相机或渲染目标时提供更合适的纹理细节。Mipmap是由原始纹理生成的一系列缩小版本,每个版本的大小都是前一个版本的一半。这样在渲染距离较远的物体时,能够使用较小的纹理,从而提高性能和减少显存的使用。
Mip Map Bias属性允许你手动调整Mipmap级别的偏移量。较大的偏移值将导致更低级别的Mipmap版本被使用,从而使纹理看起来更模糊、缩放比例更小。较小的偏移值将导致更高级别的Mipmap版本被使用,从而使纹理看起来更清晰、缩放比例更大。
通过调整Mip Map Bias属性,你可以在保证性能的前提下控制纹理细节的显示程度。较远的物体可以使用更低级别的Mipmap版本,避免不必要的细节,而较近的物体可以使用更高级别的Mipmap版本,保持细节清晰。