网站 内容 不收录 权重 1红河州做网站
一、APP安装指南
1.APP权限问题
电子标签APP安装之后,会提示一些权限的申请,点击允许。否则某些会影响APP的正常运行。安装后,搜索不到蓝牙标签,可以关闭App,重新打开。
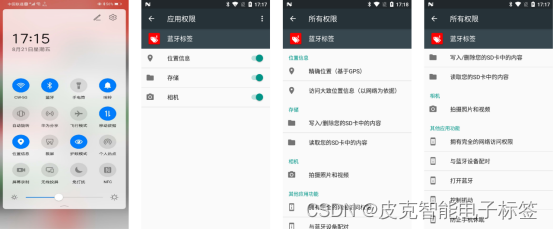
2.手机功能
运行APP时候,需要打开手机蓝牙和定位功能。如下图所示
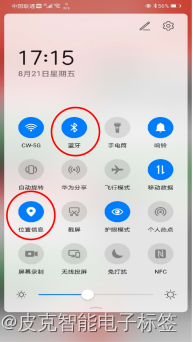
二、APP操作指南
1.设备界面介绍
设备界面的各个内容的介绍可以通过下图所示可以了解。
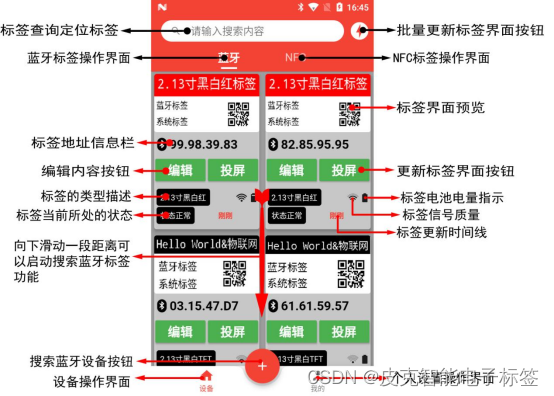
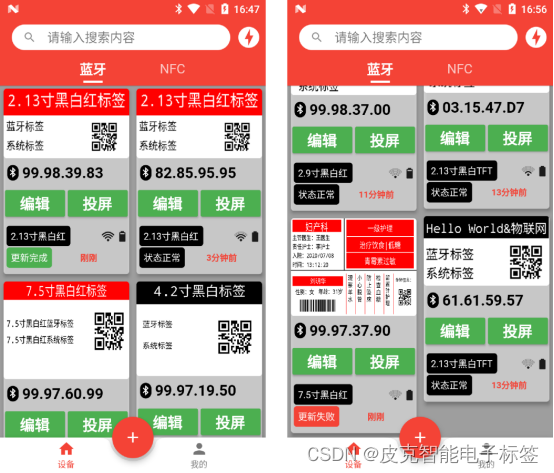
下面是蓝牙标签设备的几个状态的变化,当标签的内容被编辑过后,标签的状态就会变成黄色的【等待更新】标识,如果手动点击【投屏】按钮,标签状态会变成【准备更新】状态,此时手机会自动连接标签,并且会自动更新。可以连续的点击几个标签。如果标签连接成功,之后会出现一个传输数据的进度条。数据传输完成并且成功会提示有【更新成功】的绿色状态。如果数据传输失败,会出现【更新失败】的红色状态。

3.搜索设备
进入【设备】界面后,中间显示区域向下拉一段距离会提示搜索设备。
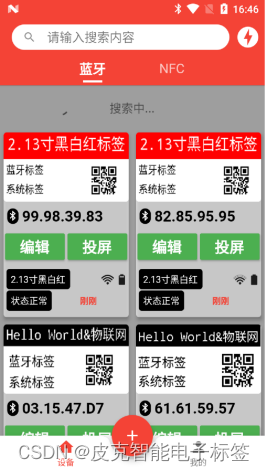
4.编辑标签内容
找到对应的标签,点击【编辑】按钮,会跳转到内容编辑的界面,如下图所示。第一行图片是预览。下面对应的是模板中内容。可以进行修改。修改的内容立即会在图片预览中看到。
条码和二维码的输入方式有两种,分别是通过后面的扫码按钮,调用扫码,进行填充内容。另外一种就是自己手动输入。

5.切换模板
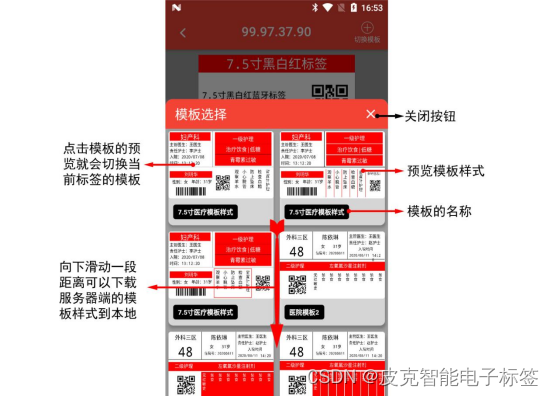
如果想对当前的标签进行切换模板,可以点击编辑界面右上角的【切换模板】按钮,可以调出模板选择界面。如下图所示。模板是可以上下滑动查看。点击模板,就会切换当前的模板。
6.模板下载
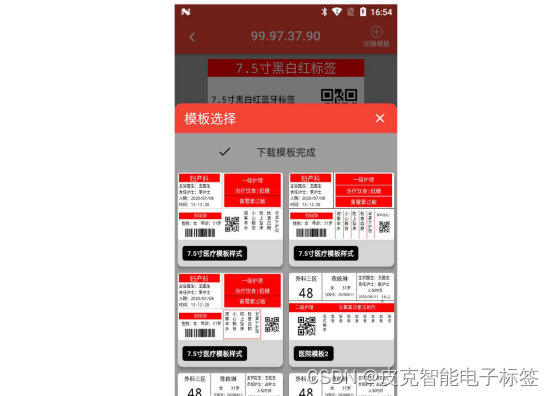
初始的时候模板是空的。需要从服务器上面下载模板。下载模板的方式是在【模板选择】界面,下拉模板界面的主区域。向下拉一段距离之后,会提示【下载模板】,如下图所示。
7.制作模板
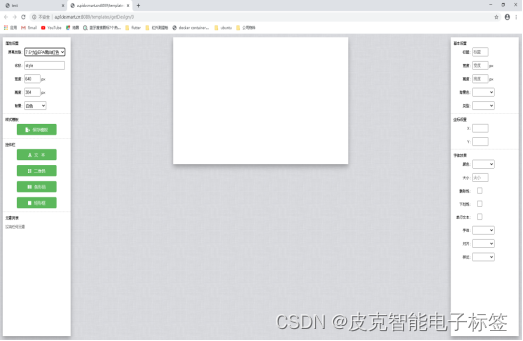
模板制作需要在PC机上面进行,点击PC上面的浏览器。输入地址:Account Login
注册登录之后,点击【模板管理】>【添加模板】就可以看到如下界面,这个就是可视化模板编辑界面。
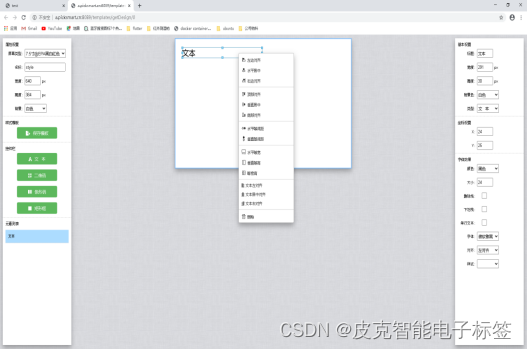
模板有文本,条码,二维码和矩形框三种类型。模板编辑中有右键功能。如下图所示。左边可以选择,相应的控件,当选择了某一个控件,右端会显示相应的属性。可以通过右端的属性来控制控件。
8.更新标签
标签内容编辑完之后,返回到【设备】界面之后,会提示对应的标签【等待更新】,如下图所示,这时候需要点击【投屏】按钮,APP就会将更改的内容刷新到标签上面。
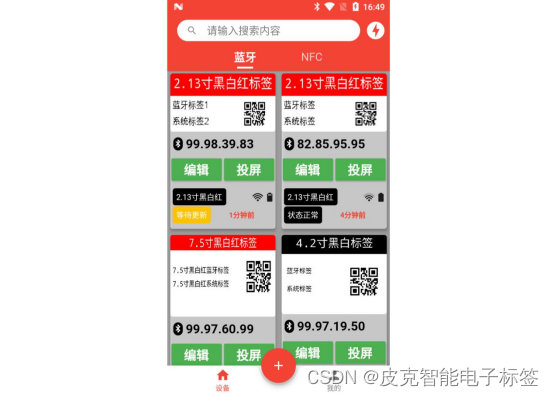
点击【投图】按钮之后,会提示不同状态,如提示【准备更新】,如下图所示
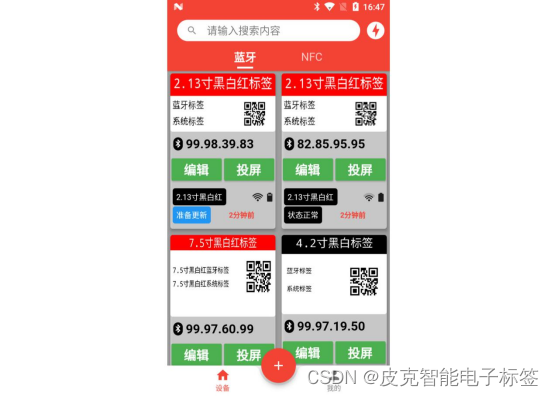
更新过程中,【进度条】显示,如下图所示。
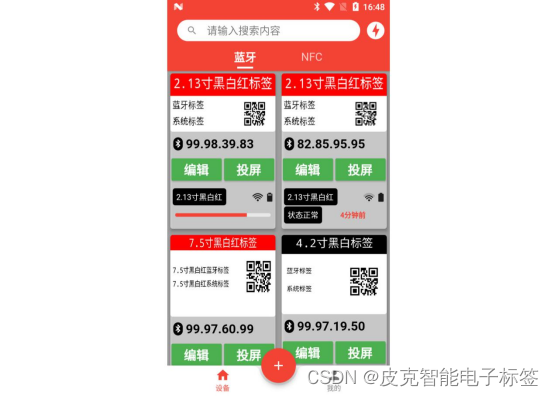
更新完之后,会提示更新的结果,【更新完成】或者【更新失败】
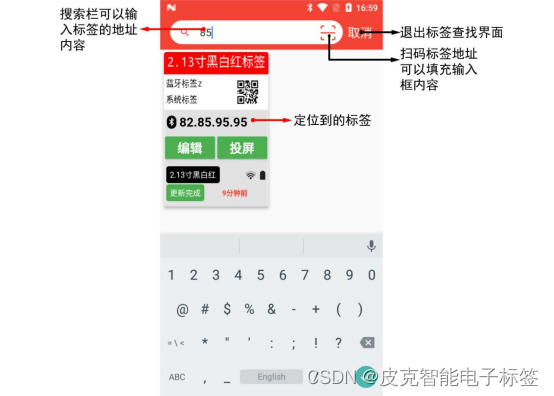
9.标签查找
点击主界面最上面的输入框,会进入到搜索界面,如下图所示。点击下面【标签地址】,可以通过标签的地址进行匹配搜索。如果需要退出搜索,点击【取消】按钮。
三、遇到的问题
- 查看是否打开了GPS定位功能,因为android6.0后蓝牙搜索需要打开蓝牙定位功能
- 查看是否打开GPS权限
- 查看是否打开蓝牙功能
- 查看是否打开了蓝牙功能权限
