外贸led网站建设赣州的免费网站建设
Google开发者大会每年都会提出有关于 Web UI 和 CSS 方面的新特性,今年又上新了许多新功能,今天就从中找出了影响最大的几个功能给大家介绍一下

:has
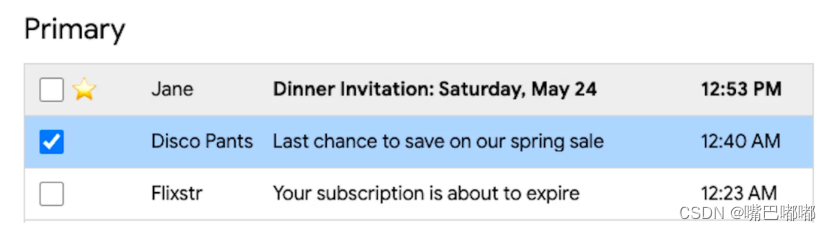
:has() 可以通过检查父元素是否包含特定子元素或这些子元素是否处于特定状态来改变样式,也就是父选择器。使用:has()选择器可以访问父元素、子元素,甚至兄弟元素
例如:带有“⭐️”元素的项目会应用灰色背景,而带有选中复选框的项目会应用蓝色背景。
Style Queries 样式查询
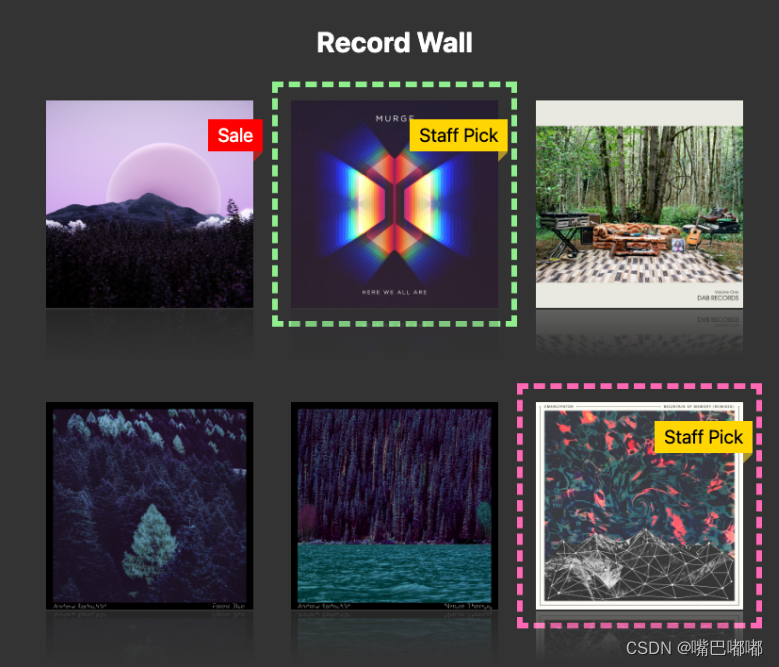
容器查询规范 允许查询父容器的样式值。目前在 Chrome 111 中部分实现,可以在其中使用 CSS 自定义属性来应用容器样式。
@container style(--sunny: true) {.weather-card {background: linear-gradient(30deg, yellow, orange);}.weather-card:after {content: url(<date-uri-for-demo-brevity>);background: gold;}
}

nth-of
nth-of 是更加高级 nth-child 语法,提供了一个新关键字(“of”),它允许使用现有的 An+B 语法,并在其中搜索更具体的子集。
如果使用常规的 nth-child,例如 :nth-child(2) 在特殊类上,浏览器将选择应用了特殊类的元素,也是第二个子元素。这与 :nth-child(2 of .special) 形成对比,后者将首先预过滤所有 .special 元素,然后从该列表中选择第二个。
:nth-child(2 of .highlight) {outline: 0.3rem dashed hotpink;outline-offset: 0.7rem;
}
动态视口单元
Web 开发人员今天面临的一个常见问题是准确且一致的全视口大小调整,尤其是在移动设备上。作为开发人员,希望 100vh (视口高度的 100%)表示“与视口一样高”,但该 vh 单元不考虑移动设备上缩回导航栏之类的事情,因此有时它最终会太长并导致滚动。

为了解决这个问题,现在在 Web 平台上提供了新的单位值:
- 小视口高度和宽度(或 svh 和 svw),表示最小的活动视口大小。
- 较大的视口高度和宽度(lvh 和 lvw),表示最大大小。
- 动态视口高度和宽度(dvh 和 dvw)。
支持 嵌套
Sass等框架的嵌套功能,是最受css开发人员追捧的功能之一,但是要想使用样式嵌套的功能只能安装各种框架,现在Web平台也同样支持了嵌套功能,允许开发人员以更简洁的分组格式编写,从而减少冗余。
.card {}
.card:hover {}/* can be done with nesting like */
.card {&:hover {}
}
Scoped CSS
Scoped CSS是CSS 作用域样式,允许开发人员指定应用特定样式的边界,本质上是在 CSS 中创建原生命名空间。以前,开发人员依靠第 3 方脚本来重命名类,或特定的命名约定来防止样式冲突,但很快,可以使用 @scope
这里将 .title 元素限定为 .card。这将防止该 title 元素与页面上的任何其他 .title 元素发生冲突,例如博客文章标题或其他标题。
@scope (.card) {.title { font-weight: bold;}
}

Scroll-driven animations
Scroll-driven animations是滚动驱动动画,它允许您根据滚动容器的滚动位置控制动画的播放。这意味着当您向上或向下滚动时,动画会向前或向后滑动。此外,对于滚动驱动动画,您还可以根据元素在其滚动容器中的位置来控制动画。这允许您创建有趣的效果,例如视差背景图像、滚动进度条和在进入视野时显示自己的图像。
此 API 支持一组 JavaScript 类和 CSS 属性,使您可以轻松创建声明性滚动驱动的动画。以前需要安装swiper插件才能实现的效果,现在原生就可以实现

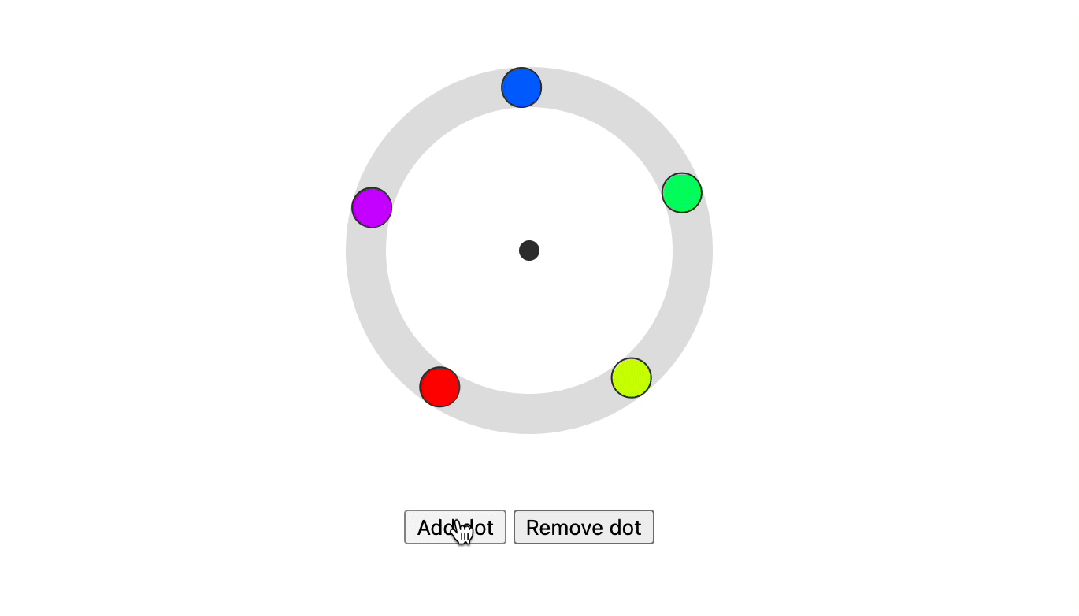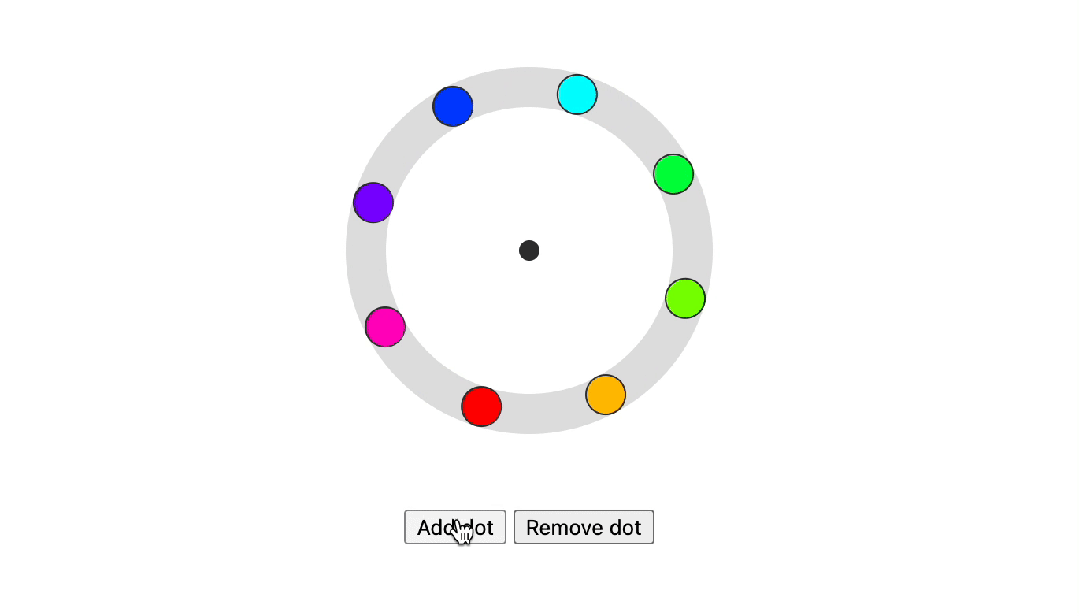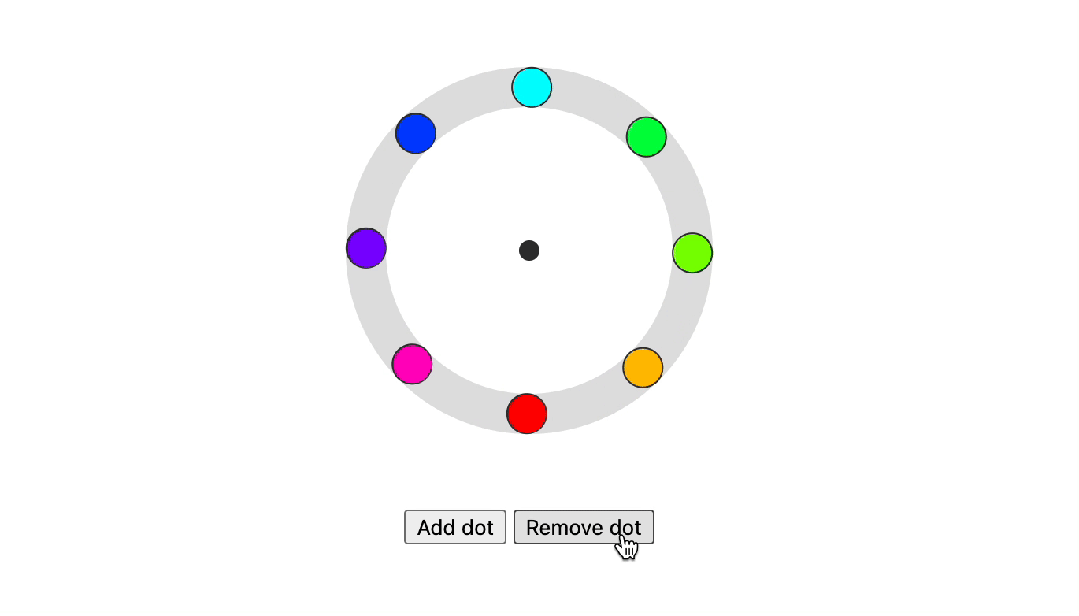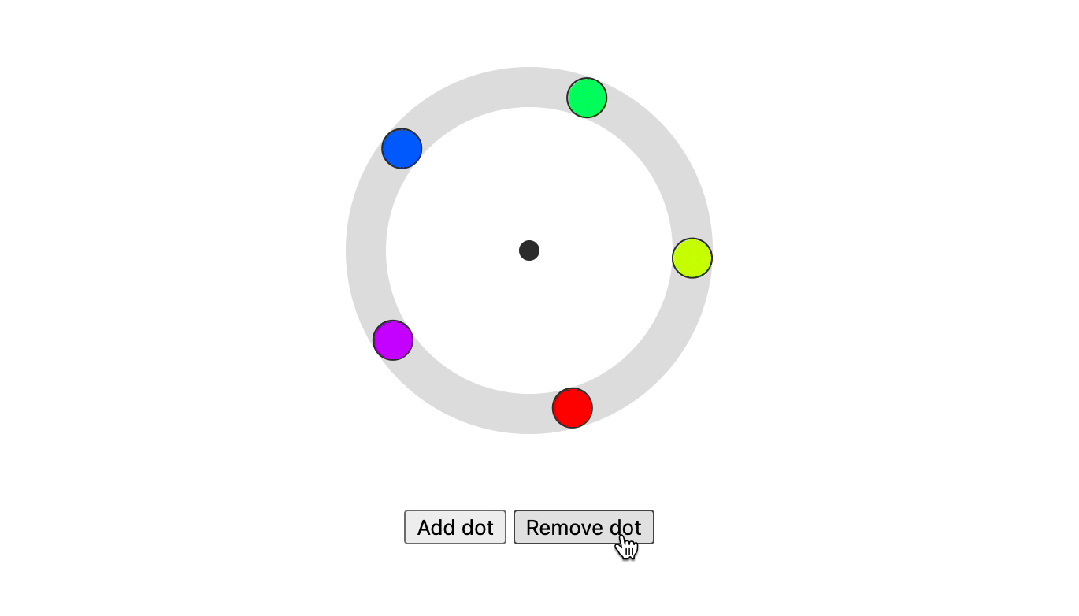
Trigonometric functions
Trigonometric functions是三角函数,CSS的另一个新功能是将三角函数添加到现有的CSS数学函数中。这些函数现在在所有现代浏览器中都是稳定的,并使您能够在Web平台上创建更有机的布局。一个很好的例子是这个径向菜单布局,现在可以使用sin()和cos()函数进行设计和动画。
在下面的示例中,点围绕中心点旋转。每个点不是围绕其自身的中心旋转然后向外移动,而是在 X 和 Y 轴上平移。X 轴和 Y 轴上的距离分别通过考虑 --angle 的 cos() 和 sin() 来确定。