网站开发管理学什么网站建设方案书怎么写样版
朴素贝叶斯算法是一种基于贝叶斯定理和特征条件独立假设的分类算法。它被广泛应用于文本分类、垃圾邮件过滤、情感分析等领域,并且在实际应用中表现出色。
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法:
1)对于给定的待分类项r,通过学习到的模型计算后验概率分布。
2)此项出现的条件下各个目标类别出现的概率,将后验概率最大的类作为α所属的类别。
核心思想:是利用特征之间的条件独立性,来对给定的数据进行分类。具体而言,朴素贝叶斯算法基于贝叶斯定理,通过计算每个类别下各个特征对应的概率来进行分类推断。其对应的贝叶斯公式如下:

朴素贝叶斯朴素在: 计算条件概率分布P(X=xY=C_k)时,NB引入了一个很强的条件独立假设,即,当Y确定时,X的各个特征分量取值之间相互独立。
在估计条件概率P(X|Y)时出现概率为0的情况下采用贝叶斯估计,简单来说就是引入“ 入”:
入=0时,就是普通的极大似然估计;入=1时称为拉普拉斯平滑。
接下来通过文章分类计算案例进行演示,需求是通过前四个训练样本(文章),判断第五篇文章,是否属于China类:
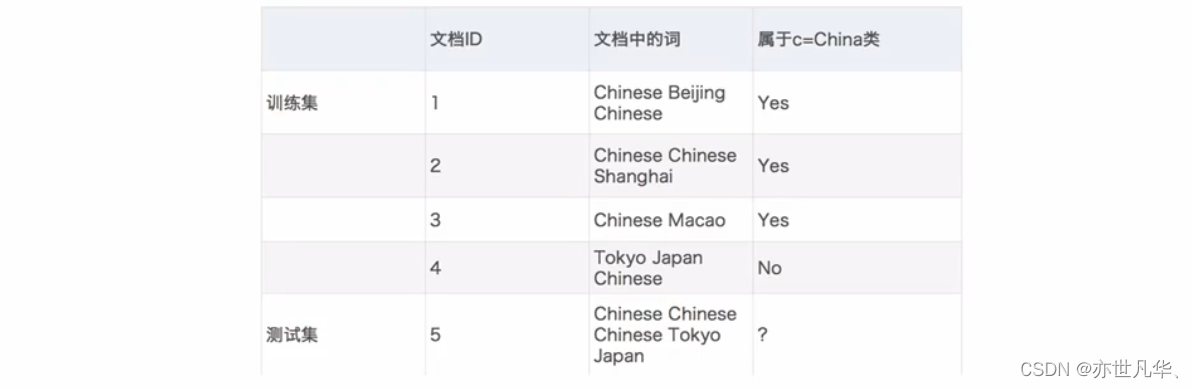
其计算结果如下所示:

上面的例子我们得到P(TokvolC)和P(JapanlC)都为0,这是不合理的,如果词频列表里面有很多出现次数都为0,很可能计算结果都为零。 解决办法就是使用拉普拉斯平滑系数:


商品评论情感分析:接下来通过一个案例来解释一下朴素贝叶斯算法的实现过程,其大致的操作就是给定一段话判断当前是好评还是差评:

下面这段代码主要实现了文本数据的处理、特征提取和朴素贝叶斯模型的训练与评估:
import pandas as pd
import numpy as np
import pkuseg
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB# 获取数据
data = pd.read_json('./data/书籍评价.json')
# print(data)# 数据基本处理
# 取出内容列用于后面分析
content = data["内容"]
# print(content)
# 把评价中的好评差评转换为数字
data.loc[data.loc[:, "评价"] == "好评", "评论编号"] = 1
data.loc[data.loc[:, "评价"] == "差评", "评论编号"] = 0# 选择停用词
stopwords = []
with open("./data/stopwords.txt", "r", encoding="utf-8") as f:lines = f.readlines()for tmp in lines:line = tmp.strip()stopwords.append(line)
stopwords = set(stopwords) # 去重,集合格式# 把内容处理成标准模式
comment_list = []
seg = pkuseg.pkuseg() # 实例化分词器对象
for tmp in content:seg_list = seg.cut(tmp)seg_list = [word for word in seg_list if word not in stopwords] # 过滤停用词seg_str = " ".join(seg_list) # 使用空格连接词语comment_list.append(seg_str)# 统计词频
con = CountVectorizer()
X = con.fit_transform(comment_list)# 准备训练集
x_train = X.toarray()[:10, :]
y_train = data["评价"][:10]# 准备测试集
x_test = X.toarray()[10:, :]
y_test = data["评价"][10:]# 3. 模型训练
# 构建朴素贝叶斯算法分类器
mb = MultinomialNB(alpha=1) # alpha为Laplace平滑系数# 训练数据
mb.fit(x_train, y_train)# 预测数据
y_pred = mb.predict(x_test)
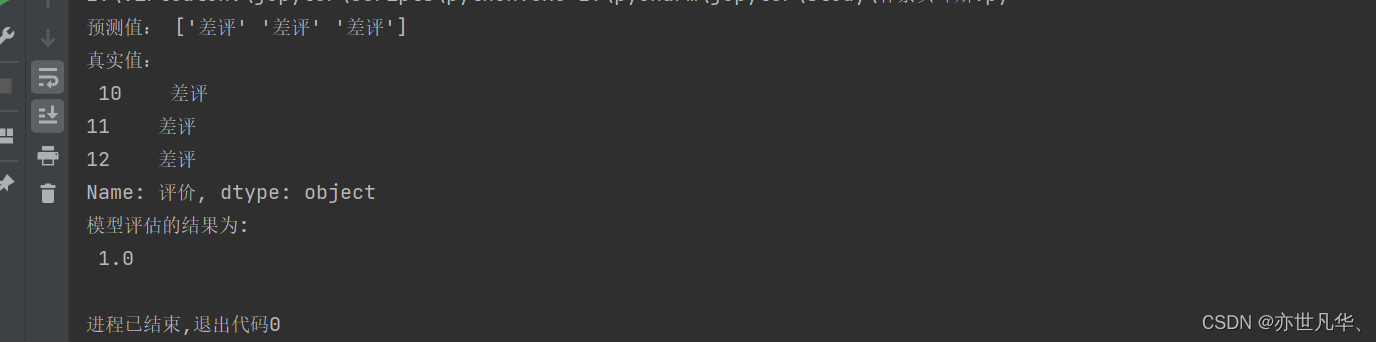
# 预测值与真实值展示
print("预测值:", y_pred)
print("真实值:\r\n", y_test)# 模型评估
result = mb.score(x_test, y_test)
print("模型评估的结果为: \n", result)最终的模型评估结果会显示模型在测试集上的准确率。整个过程涉及数据处理、文本特征提取、模型训练和评估:
我们可以体验一下百度开源的情感分析项目:点击跳转地址 :
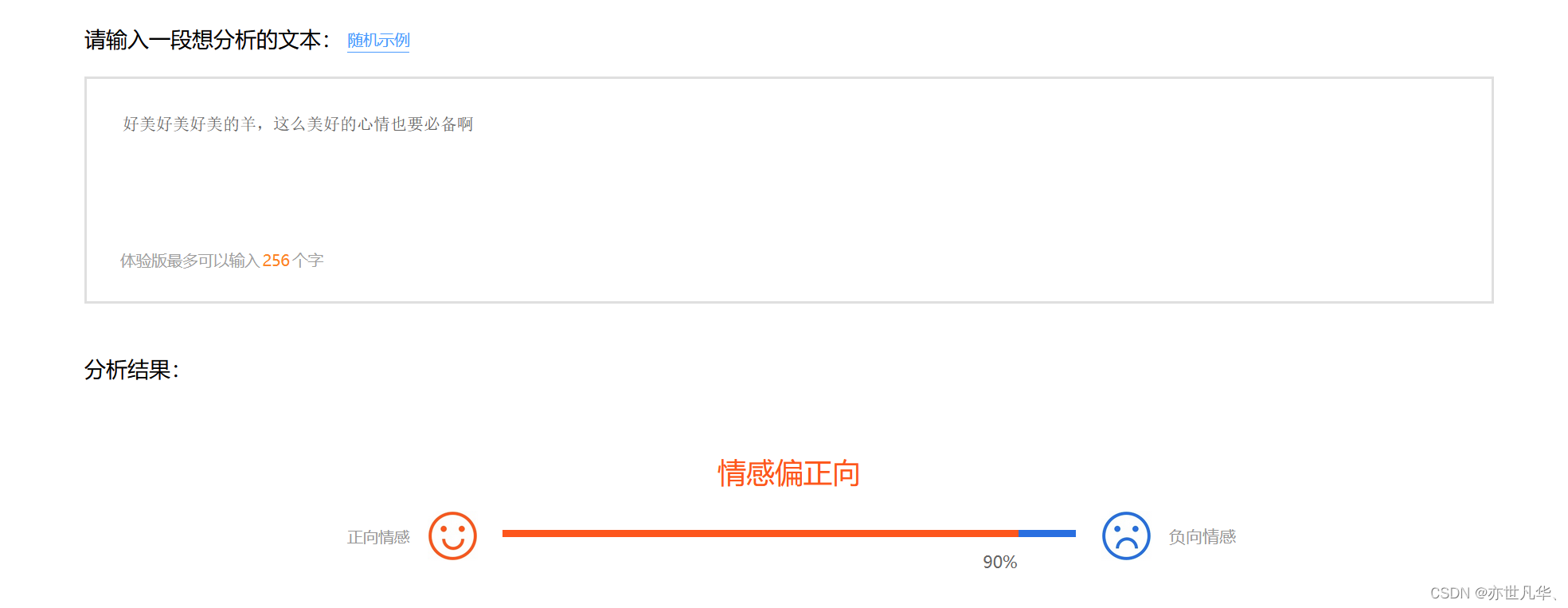
结果如下:
朴素贝叶斯优缺点:
优点:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率
2)对缺失数据不太敏感,算法也比较简单,常用于文本分类
3)分类准确度高,速度快
缺点:
1)由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
2)需要计算先验概率,而先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳;
为什么属性独立性假设在实际情况中很难成立,但朴素贝叶斯仍能取得较好的效果?
1)人们在使用分类器之前,首先做的第一步(也是最重要的一步)往往是特征选择,这个过程的目的就是为了排除特征之间的共线性、选择相对较为独立的特征;
2)对于分类任务来说,只要各类别的条件概率排序正确,无需精准概率值就可以得出正确分类;
3)如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独立性假设在降低计算复杂度的同时不会对性能产生负面影响。