温州网站开发wordpress本地上传服务器
2024年2月28日凌晨1时许,在上海浦东大道的一家养护院四楼杂物间内发生了一起火灾事故。尽管火势不大,过火面积仅为2平方米,但这场小火却造成了1人死亡和3人受伤的悲剧。这一事件再次提醒我们,养老院作为老年人聚集的场所,其消防安全问题绝不能忽视。

老年人因年龄原因行动不便,对火灾的反应速度和自救能力相对较弱,消防安全意识也相对缺失,一旦发生火灾,后果不堪设想。因此,加强养老机构的消防安全措施至关重要。
针对这一问题,民政部与国家消防救援局联合印发的《养老机构消防安全管理规定》提出,有条件的地区要积极拓展科技手段和智能硬件在养老机构消防安全管理上的应用,推广电气火灾监控、燃气泄漏探测报警系统等智能手段,降低火灾发生风险。

为了多方位守护长者安全,全视通智慧机构养老解决方案在厨房、卧室等容易发生火灾的空间场景,配备燃气探测、烟雾感应等智能设备,可实现24小时监护,一旦发现异常情况,如煤气泄漏、起火等,系统能够立即发出警报,提醒工作人员迅速处理,从而有效避免火宅事故的发生。

除了消防安全隐患以外,养老机构的整体服务质量和其他安全场景也值得我们重视。
全视通的智慧方案为养老机构提供了如日常基本信息管理、运营管理、健康体征、安全监护、紧急呼叫等便捷的照护服务等,满足了老年人的多元化需求。同时,该方案也可以帮助机构精简业务流程,优化服务项目,科学规范管理,实现有效管理各楼层,为老年人提供精准化服务和智慧化照护。

方案利用智能胸卡等可穿戴设备,为老年人提供定位功能和一键呼叫等功能。通过照护床分机、照护房门口机、卫生间紧急按钮、告警门灯等智能设备,为老年人提供双向呼叫,信息展示、紧急呼叫、紧急预警等功能,护工可以快速看到老年人的求救信息,以便于对紧急情况快速做出反应。
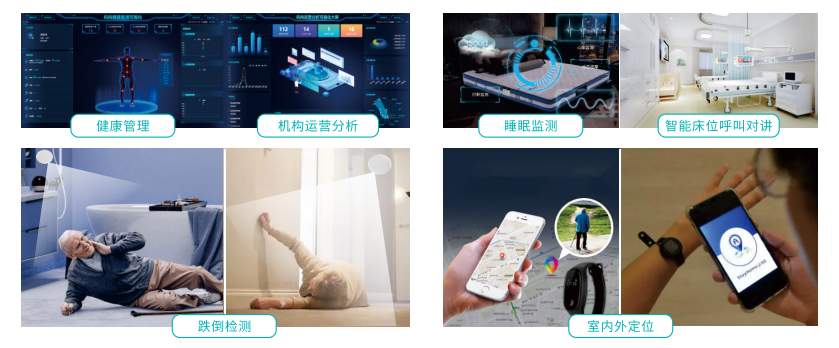
方案还利用跌倒检测雷达、生命体征监测雷达、智能传感垫等健康监测设备对老年人进行检测,检测结果可以直接上传至康养运维平台数据库,并形成老年人的健康管理档案,院方的医护人员便可根据健康档案数据对老年人做有针对性的护理,不仅提高了效率,还提升了准确性。
此外,全视通智慧机构养老解决方案还支持政府监管和数据分析,为民政管理部门提供有效监督手段和动态化数据支撑决策。系统还可以提供完整的统计报表和强大的数据分析功能,帮助机构优化运营策略和提升服务品质。
截至目前,全视通智慧机构养老解决方案已在上海、青岛、大连等地区投入使用,帮助大连康养葵英养护院、上海市浦东新区新金桥金杨养老院、青海省社会福利院等机构实现数智化转型,并取得了良好的口碑。
未来,全视通将继续深耕医康养业务领域,以科技创新为动力,助力养老产业的健康发展。让我们共同努力,为老年人创造更安全、更舒适的康养环境。