wordpress快速仿站杭州余杭做网站公司
通过3d max渲染效果图时,经常会出现3Dmax渲染效果图全黑或是3Dmax渲染效果图全白这类异常问题。可能遇到这类问题较多的都是新手朋友。不知如何解决。
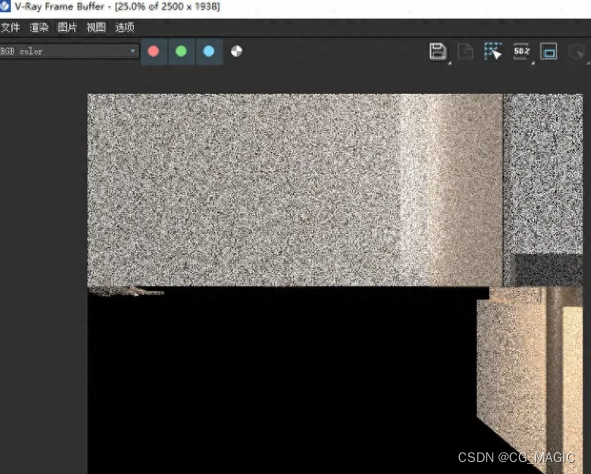
3dmax渲染出现异常的问题,该如何高效解决呢?今天小编这里整理几项知识点,大家可以快快一起看起来!
1、相机的位置
普通相机还是物理相机。注意看它的位置是否存在异常。
比如放在了模型的里面或者是墙体的外面,从而遮挡了视角。然后确认相机剪切的数值是否正确。

2、物理相机
如果使用的是物理相机,要查看是否启用了曝光功能,这时可以调整ISO、快门、光圈的数值。
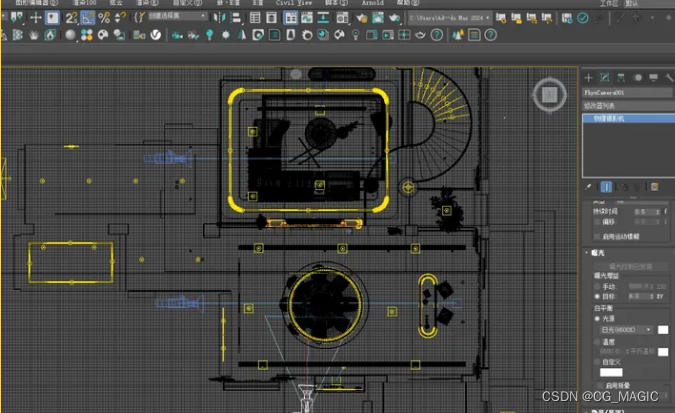
3、环境面板
如果这个文件是别人做的,或者使用的是vray物理相机,渲染出现问题,就需要在环境与效果面板的曝光控制选项中,把“曝光控制”改成“找不到位图代理管理器”。
4、灯光位置
如果场景存在光源,要检查灯光是否被遮挡住,并且检查一下灯光的强度够不够。
5、渲染器设置
使用的是渲染预设导致异常,有可能是VR版本差异等原因导致的,这时候要将渲染器重置,先切换为扫描渲染器,在切换为VR或者CR渲染器,重置之后,重新调整参数。
3dmax渲染出现异常的问题,小编推荐一款更高效的解决方法就是通过3dmax插件CG Magic。
CG MAGIC多款亮点功能 操作简单便捷,助力设计师们简化日常繁琐操作,实用的很!
操作过程中遇到问题,可以直接一键体检,CG MAGIC支持全场景全方位体检,异常问题可直观知晓并一键修复与优化,解决渲染慢、和Max崩溃等各类问题。
CG Magic实用功能——全面体检
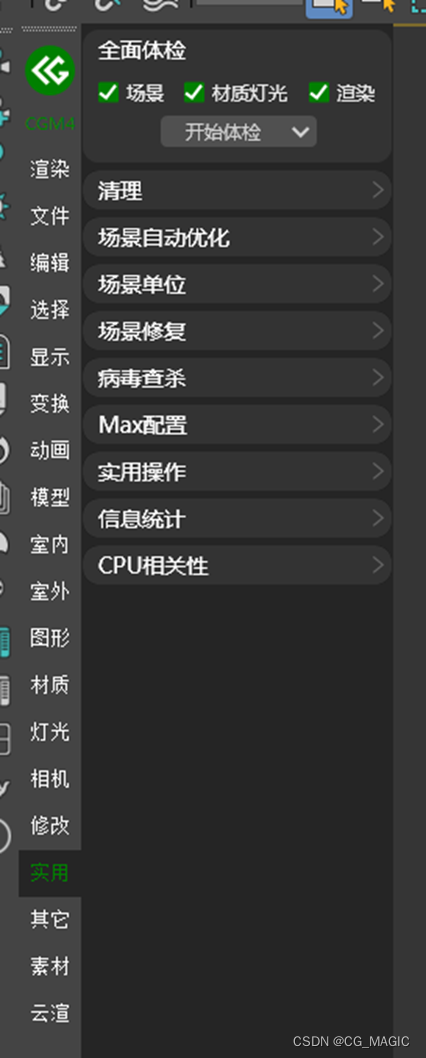
针对当前场景进行全方位的体检,在体检报告中显示当前场景中存在的问题,可在检查结果中选择是否针对此问题进行处理。
CG Magic 专业版更是新增【室外、室内、模型、动画】和云渲染五大板块,覆盖面更广、更强,助你一键解锁快速建模、生长动画、云端渲染等高效功能,把更多的时间留给创意。
更多功能快快下载使用!福利多多!