英语培训网站模板diy wordpress
关于报告的所有内容,公众【营销人星球】获取下载查看
核心观点
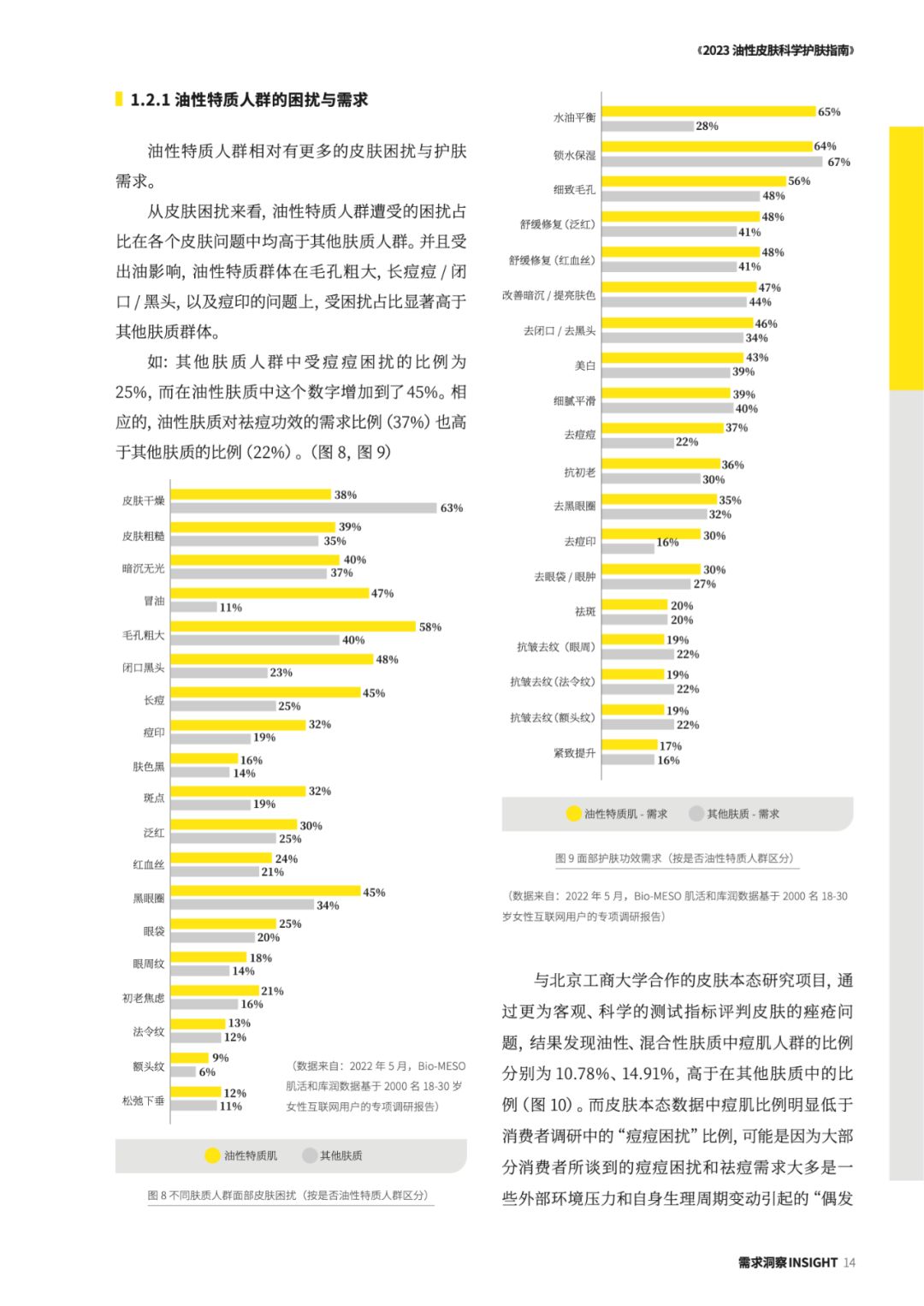
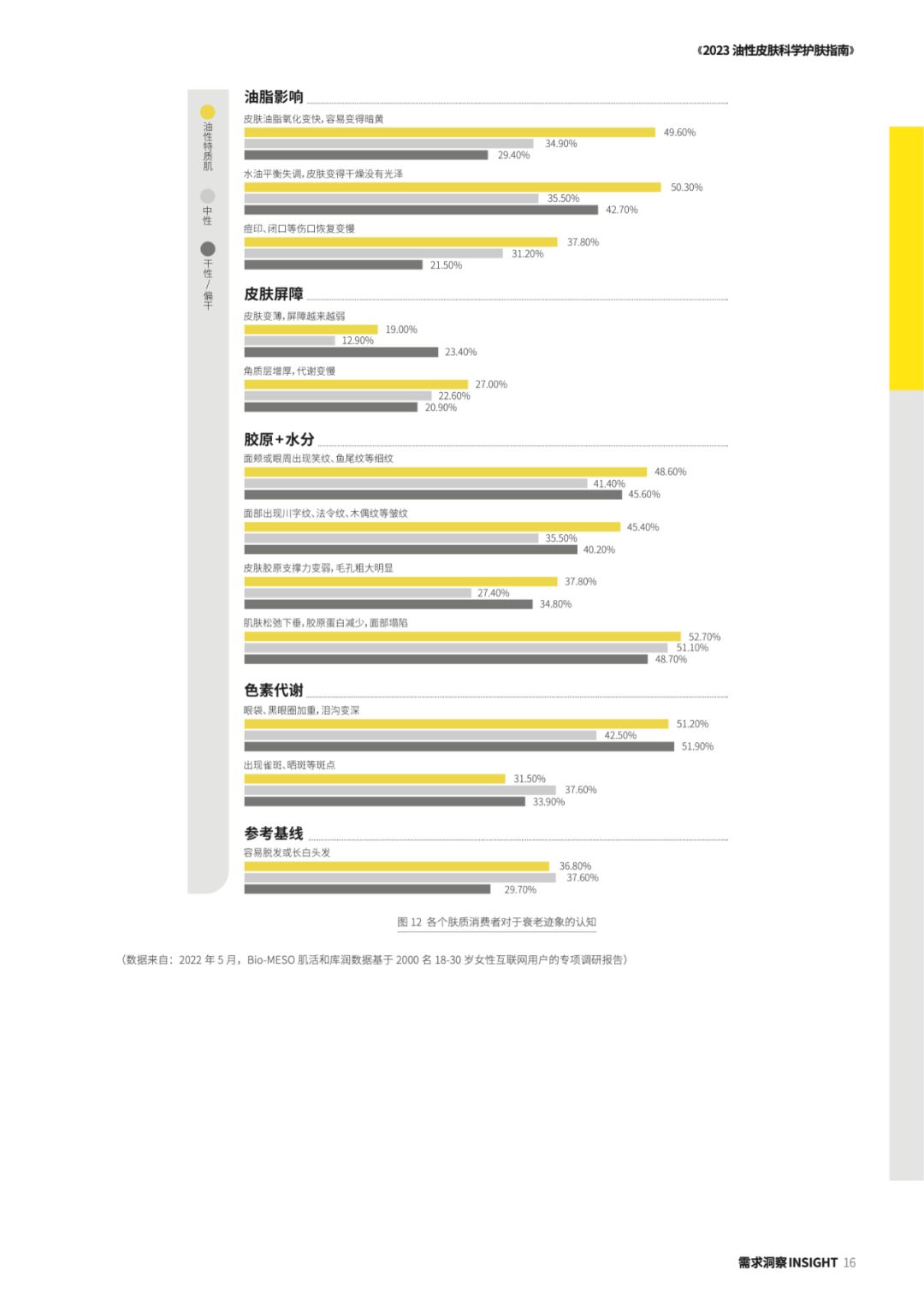
以悦己和尝鲜为消费动机的他们,已迅速崛起成为护肤行业的焦点人群。而在新生代护肤议题中,“油性皮肤护理”已经成为一个至关重要的子集。今天,中国新生代人口数量约为 3.7亿,其中油性皮肤(油皮)女性就达到约 0.433 亿。“因为看过太多好东西”,所以这个庞大的群体在油皮“颜”究这条大道上不断进阶,不止步于基础保湿功效的护肤需求,格外注重更深层次的护理效果。
报告来源

















免责声明:营销人星球尊重知识产权、数据隐私,只做内容的收集、整理及分享,报告内容来源于网络,报告版权归原撰写发布机构所有,通过公开合法渠道获得,如涉及侵权,请及时联系我们删除;如对报告内容存疑,请与撰写、发布机构联系。