古镇网站建设公司网站设计文档模板
stack 与 queue
- stack
- STL 容器中 stack 的使用
- 模拟实现 stack
- queue
- STL 容器中 queue 的使用
- 模拟实现 queue
stack
在数据结构中,我们了解到,stack 栈结构,是一种先进后出的结构,并且我们是使用顺序表来进行实现栈的操作的。
STL 容器中 stack 的使用
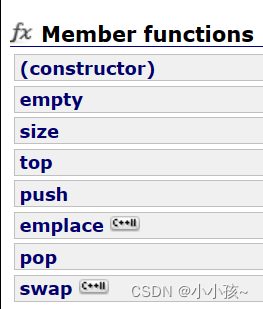
C++ STL 中stack的基本操作有:
代码测试练习:
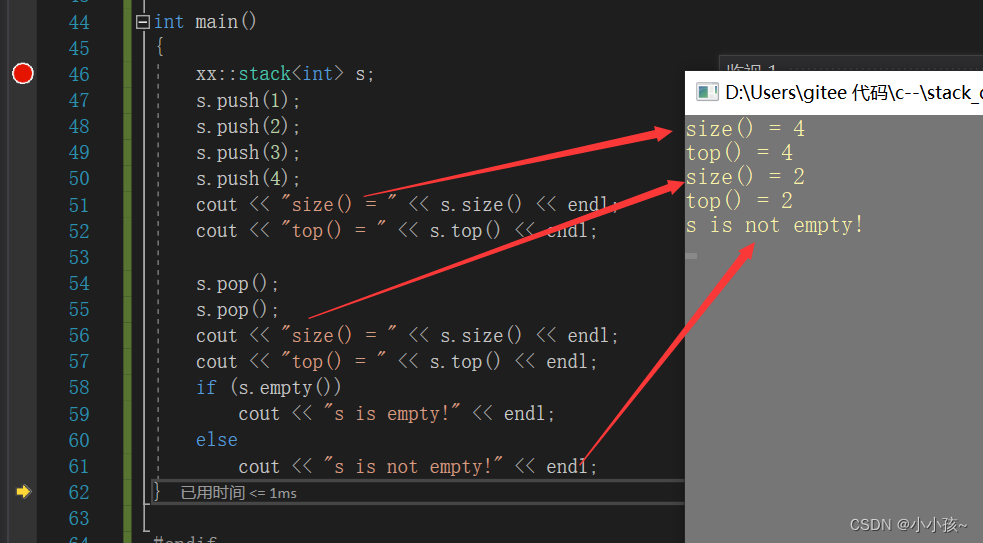
void test0()
{stack<int> s;s.push(1);s.push(2);s.push(3);s.push(4);cout << "size() = " << s.size() << endl;cout << "top = " << s.top() << endl;if (s.empty())cout << "s is empty!" << endl;elsecout << "s is not empty!" << endl;s.pop();s.pop();s.pop();cout << "size() = " << s.size() << endl;cout << "top = " << s.top() << endl;if (s.empty())cout << "s is empty!" << endl;elsecout << "s is not empty!" << endl;}

模拟实现 stack
由于栈结构是“后进先出”的,因此在进行栈模拟时候我们可以使用顺序结构来进行,之前学习到 STL 容器中的 vector 容器是顺序结构的,我们可以直接复用:
namespace xx { //定义自己的命名空间template<class T,class Container=std::vector<T>> //定义模板类型class stack {public:stcak() //构造方法不需要写,因为 Container 被定义为 vector 容器,会自动进行构造方法的调用 {}void push(const T& val){c.push_back(val); //使用 vector 容器的尾插方法}void pop(){if (empty())return ;c.pop_back(); //出队,使用 vector 容器中的尾删操作-----------后进先出原则}T& top(){return c.back(); //获取栈顶元素,也就是最后一个入栈的元素------即复用 vector 容器中获取最后一个元素的方法}const T& top()const{return c.back();}size_T size()const{return c.size(); //返回 vector 容器的大小}bool empty()const{return c.empty(); //判断 vector 容器是否为空}private:Container c; //定义 Container 为 vector 容器};}
代码测试:
queue
在数据结构中,我们知道 queue 队列是一种先进先出的结构。
STL 容器中 queue 的使用
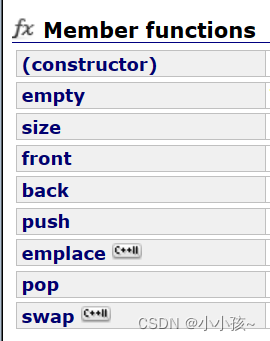
C++ STL 中queue的基本操作有:
代码测试练习:
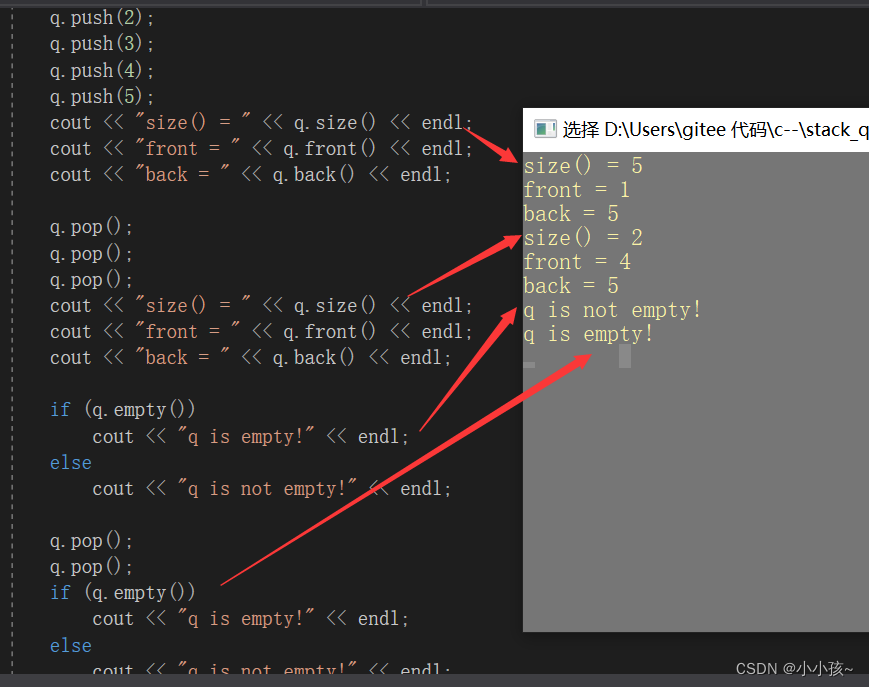
void test1()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);q.push(5);cout << "size() = " << q.size() << endl;cout << "front = " << q.front() << endl;cout << "back = " << q.back() << endl;q.pop();q.pop();q.pop();cout << "size() = " << q.size() << endl;cout << "front = " << q.front() << endl;cout << "back = " << q.back() << endl;if (q.empty())cout << "q is empty!" << endl;elsecout << "q is not empty!" << endl;q.pop();q.pop();if (q.empty())cout << "q is empty!" << endl;elsecout << "q is not empty!" << endl;}
模拟实现 queue
队列是属于“先进先出”的结构,在队尾进行元素的插入,队头进行元素的删除操作,因此为了避免头删而导致大量元素的移动操作,我们避免使用顺序结构来实现队列,故可以复用 list 链表结构来实现:
namespace xx { //自定义命名空间template<class T,class Container=std::list<T>> //定义模板类型class queue {public:queue() //构造方法会直接使用 list 方法的构造{}void push(const T& val){//尾插q.push_back(val); //尾插------链表的尾插操作}void pop(){//头删if (empty())return; q.pop_front(); //队头出队----------链表的头删操作}T& front(){return q.front(); //获取队头元素---------链表的首节点信息}const T& front()const{return q.front(); }T& back(){return q.back(); //获取队尾元素----------链表的尾节点信息}const T& back()const{return q.back();}size_t size()const{return q.size(); //队中元素个数 --------> 链表中节点个数}bool empty()const{return q.empty(); //队列是否为空 -----------> 判断链表是否为空}private:Container q;};
}代码测试:
ps:
代码需要多练多理解,今天的分享相对于来说还是比较简单的,需要详细的 stack 和 queue 的实现可以参考数据结构中的讲解哦 —> 添加链接描述
~今天的学习就到这里啦!期待周末考试一切顺心鸭!!!