网页导航网站设计网上注册公司名字审核
为什么你的品牌营销不见效?如何能推动品牌破圈?让媒介盒子给你一些启发。本期盒子要跟大家分享地新机上市,数码科技行业企业该如何做线上宣传。

HUAWEI Mate 60系列8月29日官宣发布,出色的拍照功能、强大的性能表现和持久的续航能力,同时搭载了华为自研的鸿蒙操作系统,包括HUAWEI Mate 60、HUAWEI Mate 60 Pro、HUAWEI Mate 60 RS保时捷设计版等型号。
各大媒体争相报道……
作为华为品牌下的高端旗舰手机,华为Mate 60手机的这次销售策略改变,不仅是一次市场营销上的成功,更是一次品牌形象和社会责任的成功。
权威背书+赢得用户信任
通过主流媒体尤其是权威媒体报道对打造品牌形象无可替代,企业在清晰自身的定位后,一定要逐步地、全面地搭建自身的品牌阵地,完善企业所能触达的、所有有价值的渠道网络。
华为一直在通过软广的形式不断丰富产品线布局,向大众传达打造国民品牌的形象,几乎打通了全网所以线上的渠道,自建营销矩阵+KOL+KOC合作,在渠道端主打高调发布、全面推广、密集覆盖。很早就开始开拓线上营销经验市场,有更大的先发优势,借助媒体影响力在各平台广泛传播,营销接近高峰。
渠道注重质量也注重数量
媒介盒子服务过上百家行业企业有一个非常强烈的感受,越来越多传统科技行业的企业意识到了玩转社媒平台的重要性。也越来越投入更多的成本作线上推广。
企业做线上宣传,实际就是扩大自己的流量池。越多的渠道,就会有越大的流量池,如今渠道碎片化带来的流量分散让获客越来越难。行业透明度越来越高,企业要利用大数据技术精准获客,降低营销成本全网覆盖推广,达到有效曝光。
一般知名品牌在新产品上市,找上百个媒体KOL宣传是非常正常的操作,华为Mate 60自然就不同说了。不知道怎么找渠道的企业看过来。
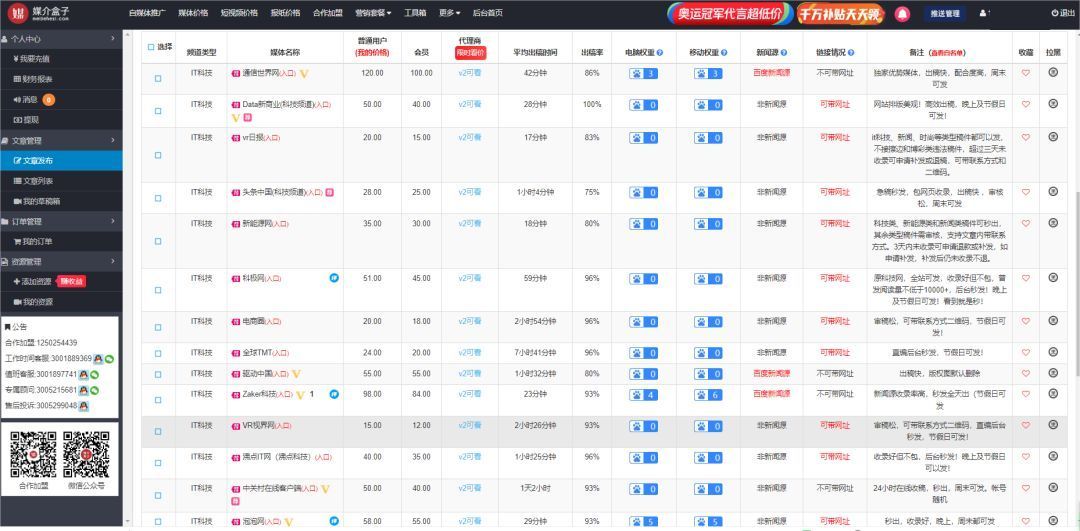
这里是媒介盒子,有十万渠道等你来挑,想要了解更多软文营销干货、新闻媒体、自媒体资源信息,欢迎随时咨询我们哦~