淮南建设公司网站网站网址正能量
文章目录
- Spark 内存管理
- 堆内和堆外内存
- 堆内内存
- 堆外内存
- 堆外与堆内的平衡
- 内存空间分配
- 静态内存管理(早期版本)
- 统一内存管理
Spark 内存管理
堆内和堆外内存
Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
堆内内存受到 JVM 统一管理,堆外内存是直接向操作系统进行内存的申请和释放。
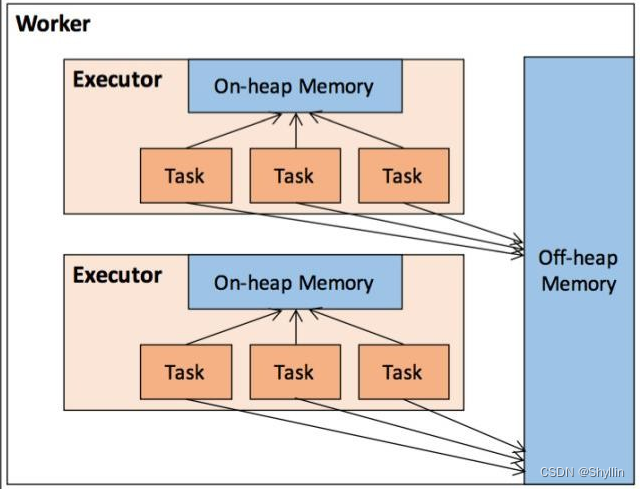
堆内内存
由 Spark 应 用 程 序 启 动 时 的 – executor-memory 或spark.executor.memory 参数配置,Executor 内运行的并发任务共享 JVM 堆内内存
存储(Storage)内存:RDD 数据缓存 和广播(Broadcast)变量;
执行(Execution)内存:任务在执行 Shuffle 时占用的内存;
剩余(Other)空间:Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例。
Spark 不能准确记录实际可用的堆内内存:在被 Spark 标记为释放的对象实例,有可能在实际上并没有被 JVM 回收,导致实际可用的内存小于 Spark 记录的可用内存。
堆外内存
Spark可以直接操作系统堆外内存,减少了不必要的内存开销,以及频繁的 GC 扫描和回收。堆外内存可以被精确地申请和释放(堆外内存之所以能够被精确的申请和释放,是由于内存的申请和释放不再通过JVM 机制,而是直接向操作系统申请和操作系统释放)
在默认情况下堆外内存并不启用,可通过配置spark.memory.offHeap.enabled 参数启用, 并由 spark.memory.offHeap.size 参数设定堆外空间的大小。堆外内存没有 other 空间,只有Storage内存和Execution内存。
堆外与堆内的平衡
对于需要处理的数据集,如果数据模式比较扁平,而且字段多是定长数据类型,就更多地使用堆外内存。
如果数据模式很复杂,嵌套结构或变长字段多,就更多采用 JVM 堆内内存会更加稳妥。
内存空间分配
静态内存管理(早期版本)
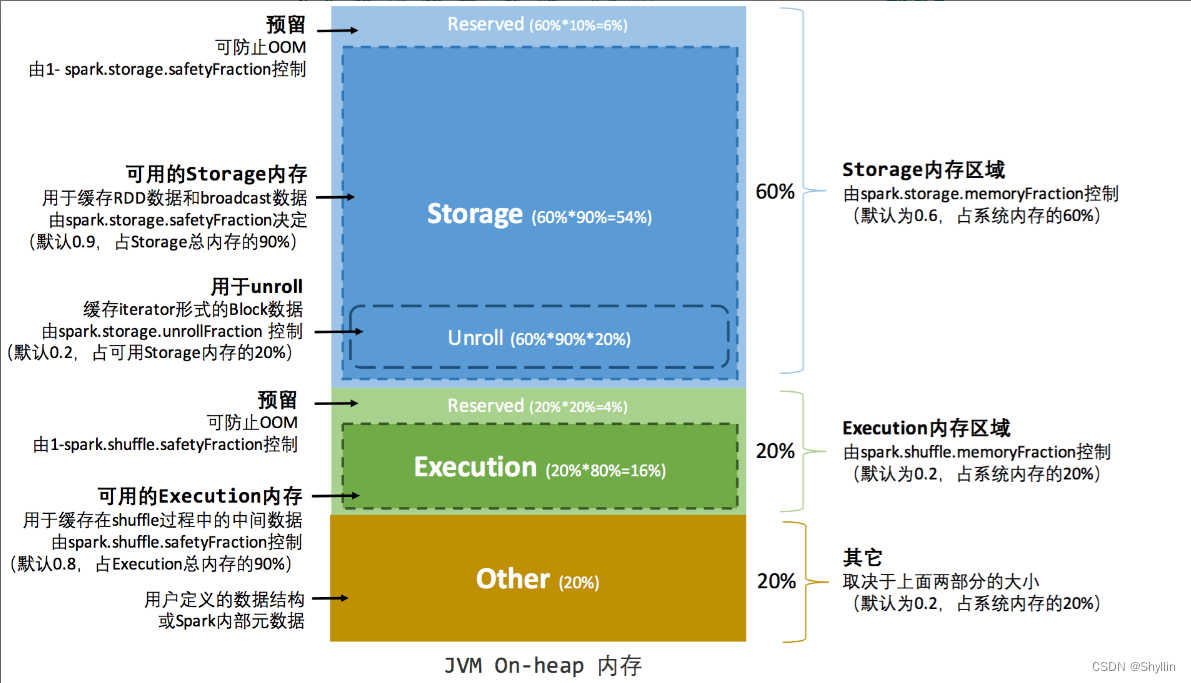
存储内存、执行内存和其他内存的大小在Spark 应用程序运行期间均为固定的,应用程序启动前可以通过参数配置。
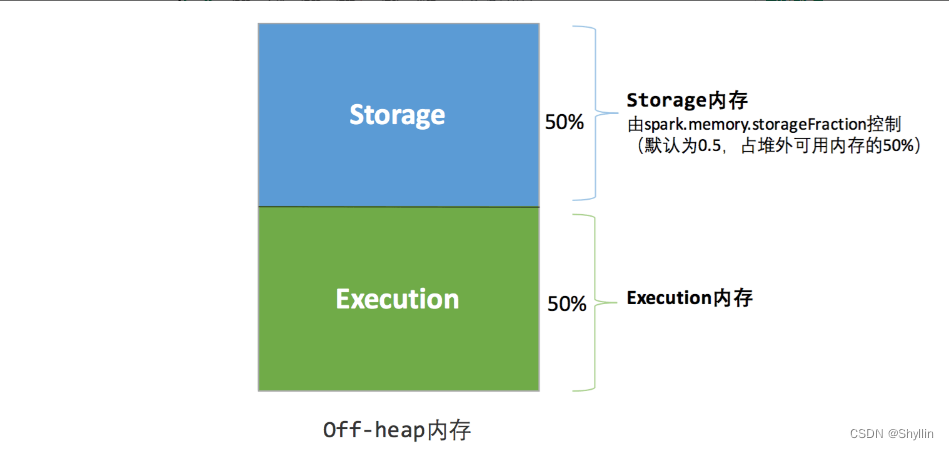
堆外的空间只有存储内存和执行内存,由参数 spark.memory.storageFraction 决定
# 静态内存# 堆内内存
# spark.executor.memory提交任务时指定executor 堆内内存总大小
可用的Execution内存 = executor.memory * spark.shuffle.memoryFraction * spark.shuffle.safety.Fraction
可用的Storage内存 = executor.memory * spark.storage.memoryFraction * spark.storage.safety.Fraction# 堆外内存
# spark.memory.offHeap.size 提交任务时指定executor 堆外内存总大小
可用的存储内存 = memory.offHeap.size * spark.storage.memoryFraction
可用的执行内存 = memory.offHeap.size * ( 1- spark.storage.memoryFraction)
统一内存管理
与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域
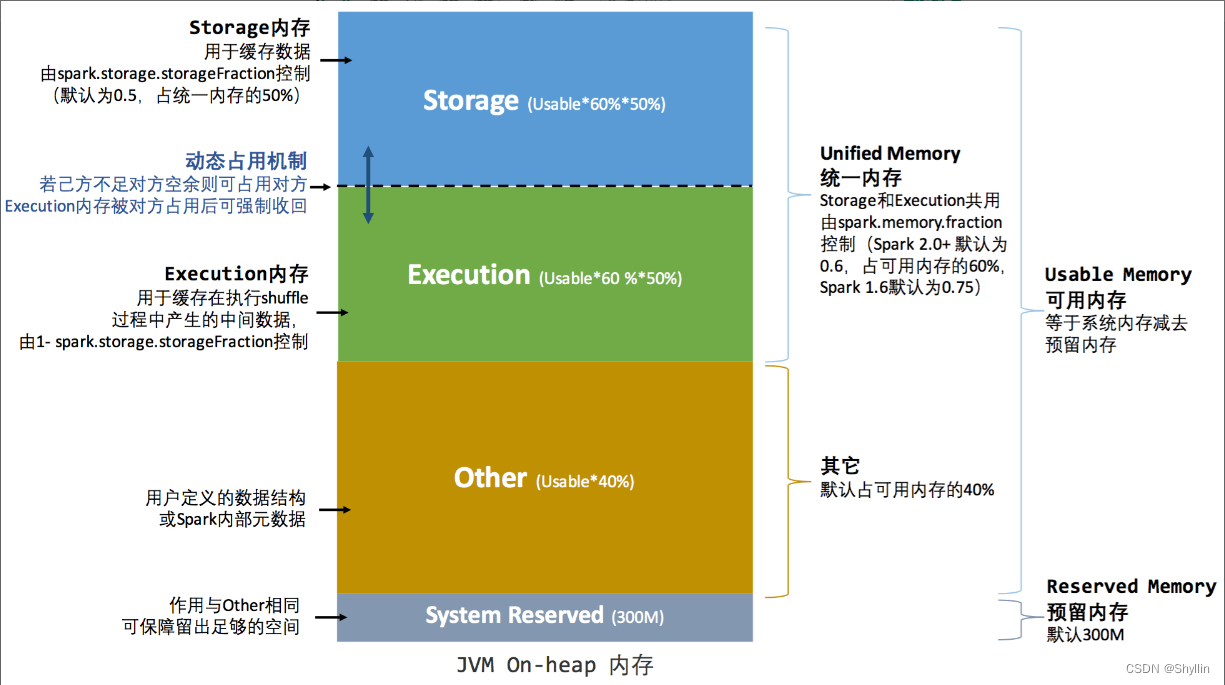
统一内存管理的堆外内存
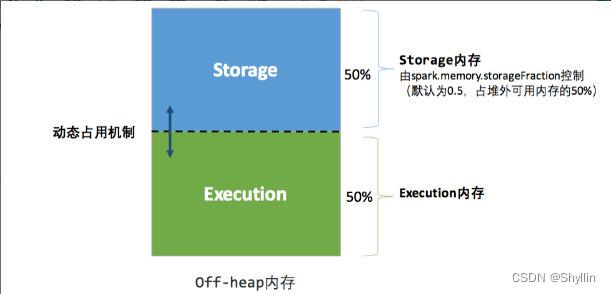
# 统一内存# 堆内内存
# spark.executor.memory提交任务时指定executor 堆内内存总大小
初始可用的Execution内存 = (executor.memory -300M) * spark.memory.fraction * (1-spark.storage.storageFraction)
初始可用的Storage内存 = (executor.memory -300M) * spark.memory.fraction * spark.storage.storageFraction# 堆外内存
# spark.memory.offHeap.size 提交任务时指定executor 堆外内存总大小
可用的存储内存 = memory.offHeap.size * spark.storage.memoryFraction
可用的执行内存 = memory.offHeap.size * ( 1- spark.storage.memoryFraction)
最重要的优化在于动态占用机制,其规则如下:
-
如果对方的内存空间有空闲,双方可以互相抢占;
-
对于 Storage Memory 抢占的 Execution Memory 部分,当分布式任务有计算需要时,Storage Memory 必须立即归还抢占的内存,涉及的缓存数据要么落盘、要么清除;
-
对于 Execution Memory 抢占的 Storage Memory 部分,即便 Storage Memory 有收回内存的需要,也必须要等到分布式任务执行完毕才能释放。