网站导航营销的优点有限责任公司的特点

一.概述
Maven是专门用于管理和构建Java项目的工具,它的主要功能有:
- 提供了一套标准化的项目结构
- 提供了一套标准化的项目构建流程(编译,测试,打包,发布)
- 提供了一套依赖管理机制
一方面,不同的IDE的项目目录不尽相同,Maven的存在可以使得同一项目在不同的IDE之间通用。
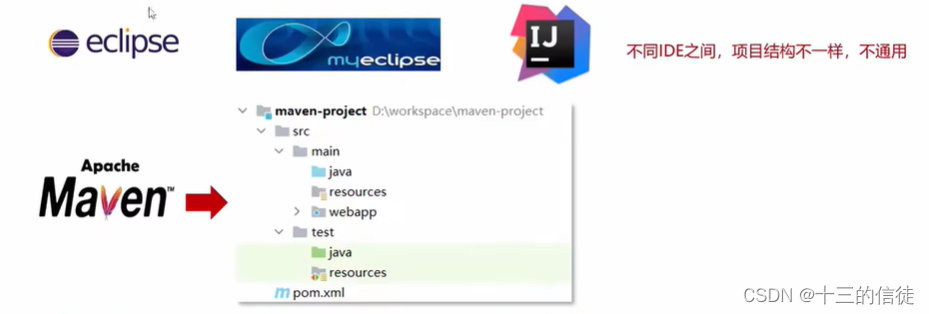
标准的Maven项目配置目录如下:
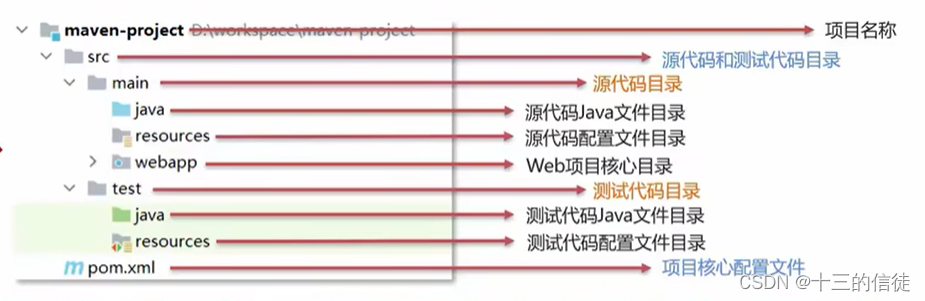 标准的项目构建流程如下:
标准的项目构建流程如下:
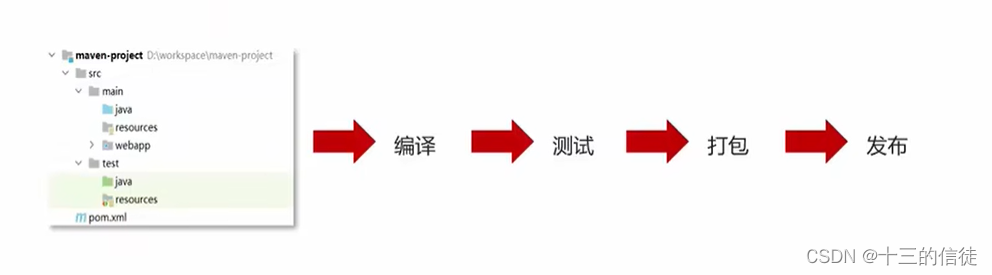 Maven提供了一套命令来完成项目构建:
Maven提供了一套命令来完成项目构建: 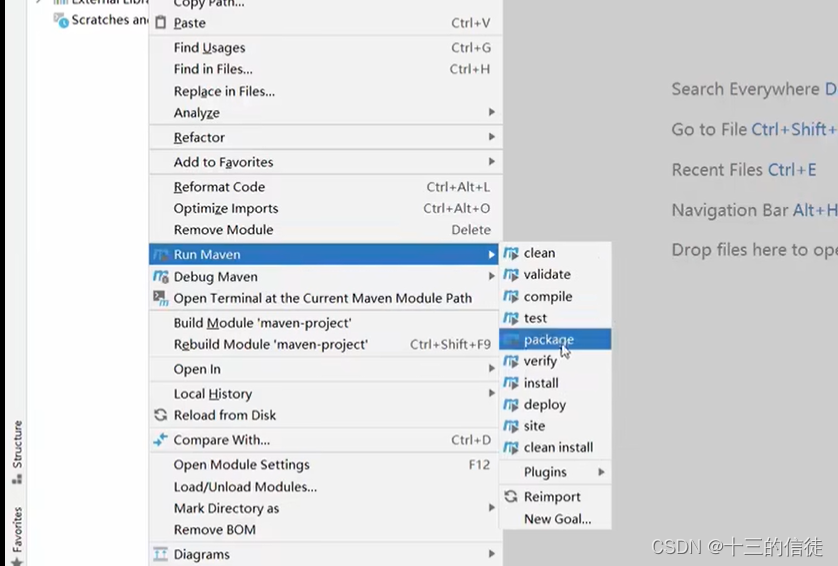
至于依赖管理,本质上就是管理项目所依赖的第三方资源。
未配置Maven的执行流程如下:
有了Maven,配置jar包,只需要简单的坐标配置即可实现,省略了寻找jar包的过程。
二.简介
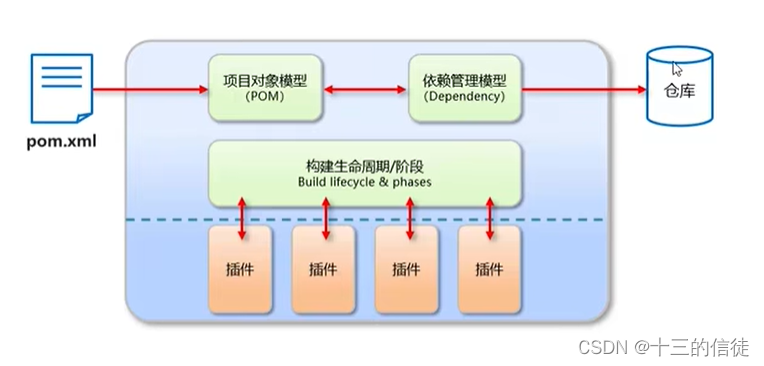
Maven是一个项目管理和构建工具,它基于项目对象模型POM的概念,通过一小段描述信息来管理项目的构建、报告、文档。
Maven模型:
仓库中提前存放了一些列jar包~

- 本地仓库:自己计算机上的一个目录
- 中央仓库:由Maven团队维护的全球唯一的仓库
- 远程仓库(私服): 一般由公司团队搭建的私有仓库

项目如要使用jar包,先在本地仓库寻找;如果本地没有则先从中央仓库下载到本地,再进行下一步引用~
三.基本使用
1.下载并解压
下载路径:Maven – Download Apache Maven
https://maven.apache.org/download.cgi
Maven文件的目录结构如下:
2.配置环境变量
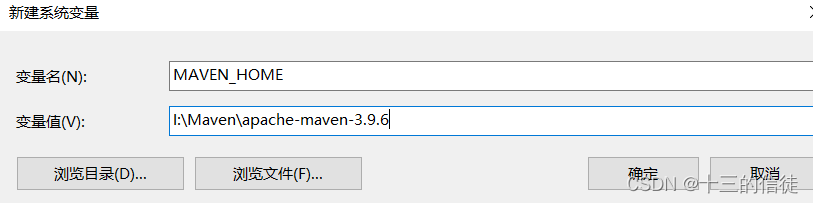
(和jdk什么的一个道理,很简单不再赘述~)
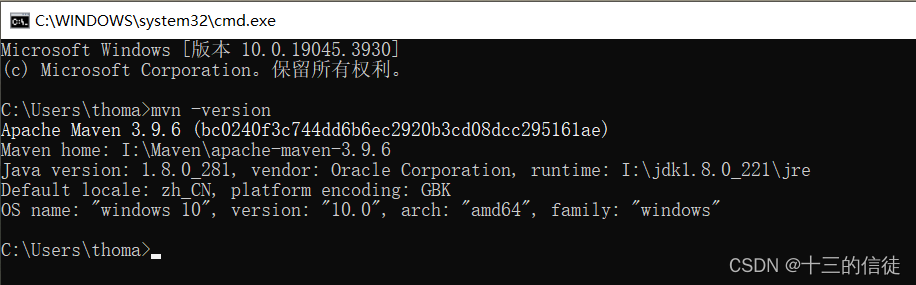
博主使用的是最新的3.9.6版本~
3. 配置本地仓库
进入conf目录下的setting.xml。
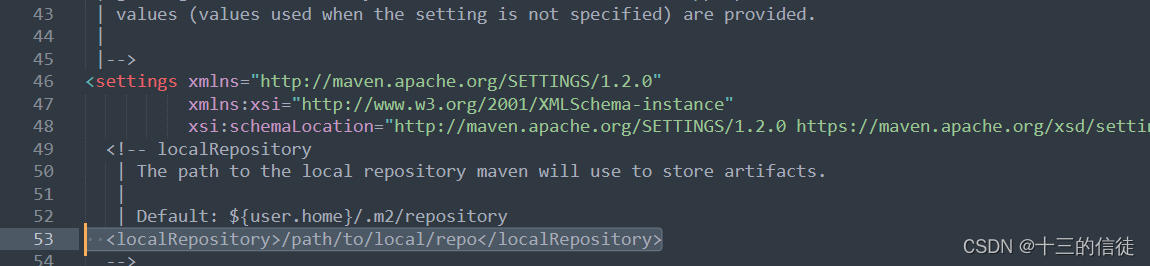 寻找被注释的如上这一行。
寻找被注释的如上这一行。

更改本地仓库的路径如上。(默认在C盘~)
4.配置阿里云私服
在mirrors标签(镜像)中植入如下代码:
<mirror><id>alimaven</id><mirrorOf>central</mirrorOf><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url> </mirror>5.Idea集成Maven
选择IDEA中的file--Settings,搜索Maven,设置使用本地安装的Maven,并修改配置文件的路径。 如下:
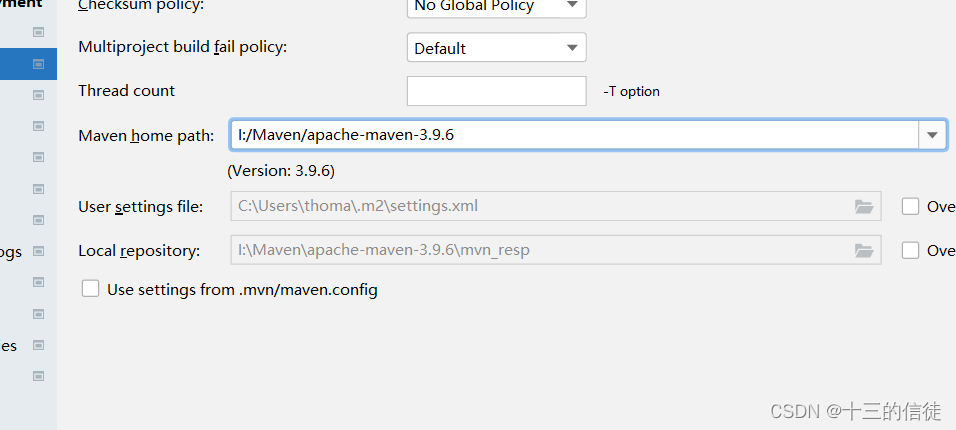
修改了本地的Maven配置后,自动加载出来了本地仓库。

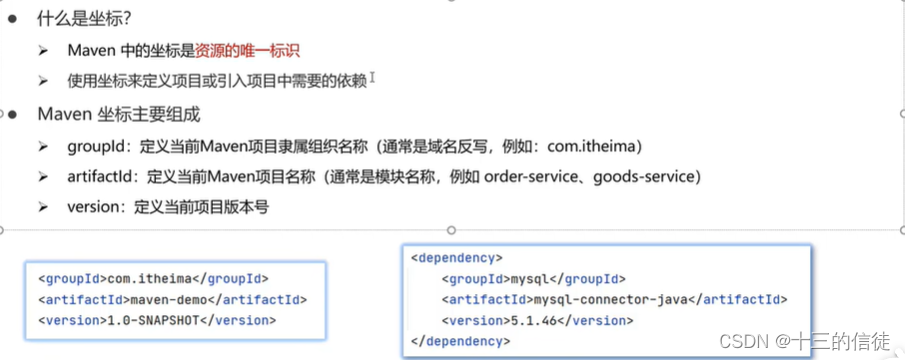
有关Maven的坐标:
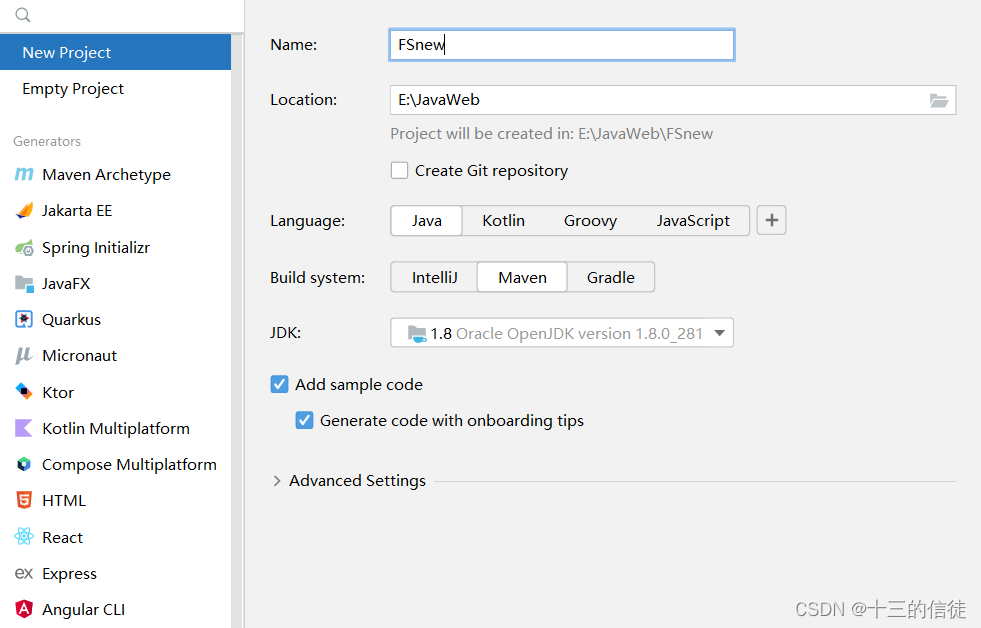
创建Maven项目:
默认项目如下:
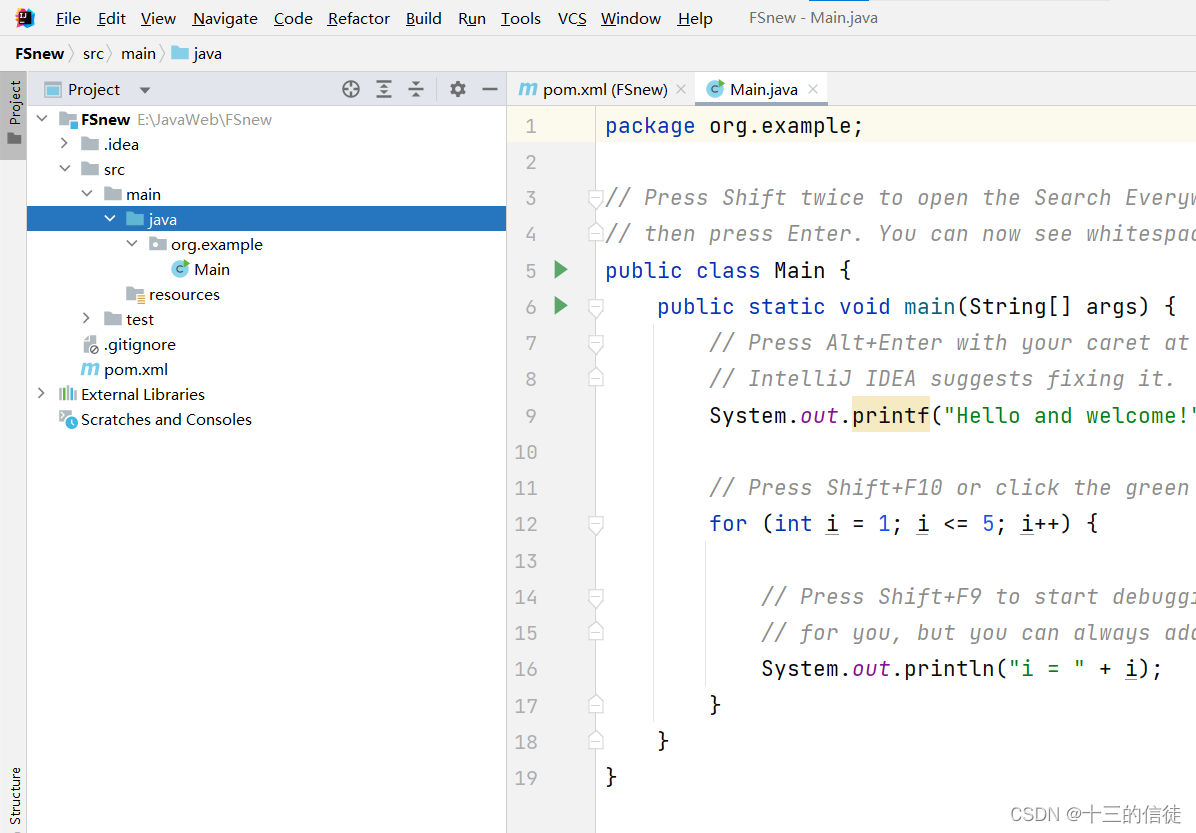
导入Maven:(点击右侧栏的Maven~)
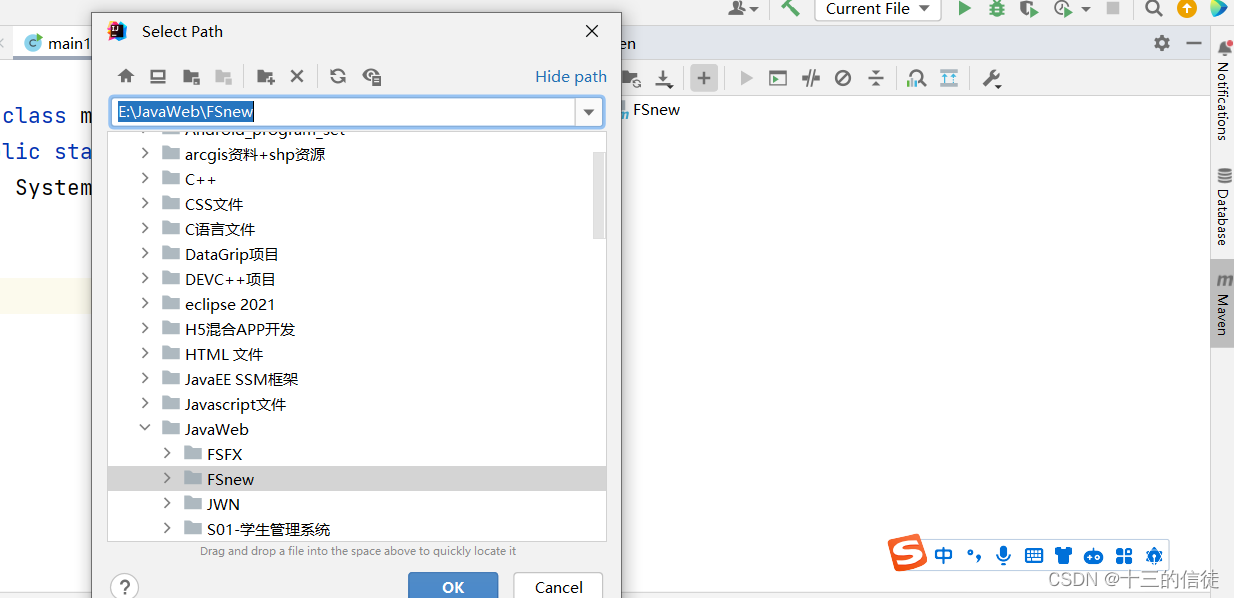
可视化地操作命令:
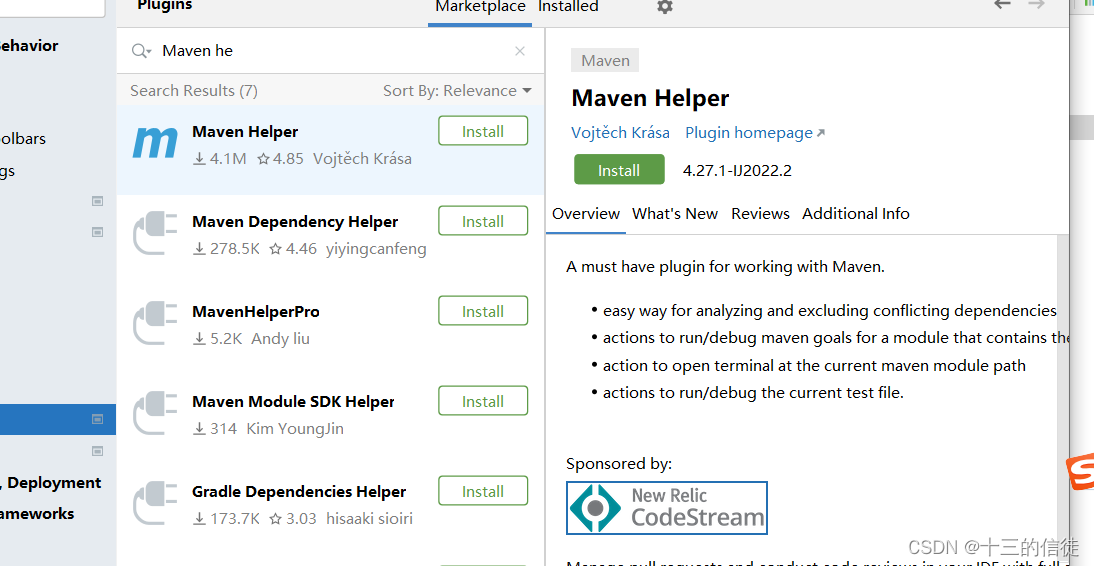
安装插件Maven helper:
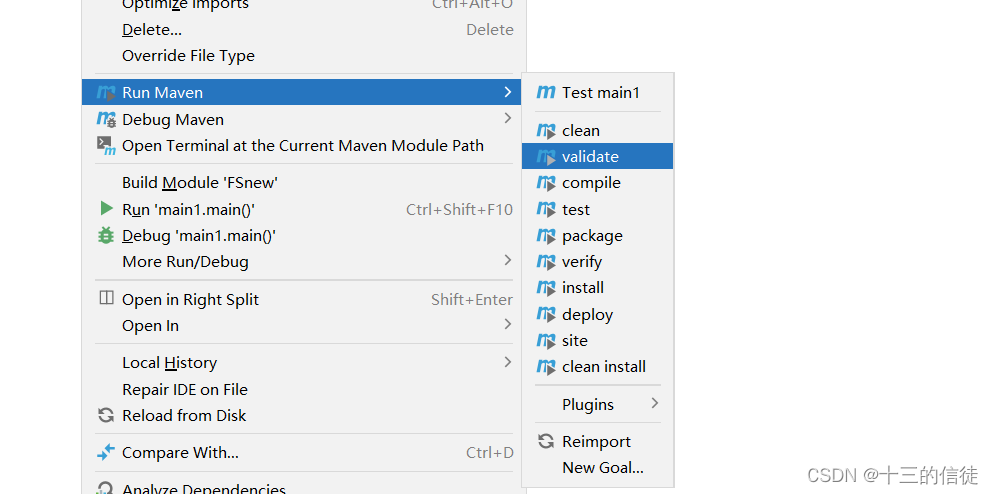
看个人喜好~
6.常见命令
- compile:编译
- clean:清理
- test:测试
- package:打包
- install:安装
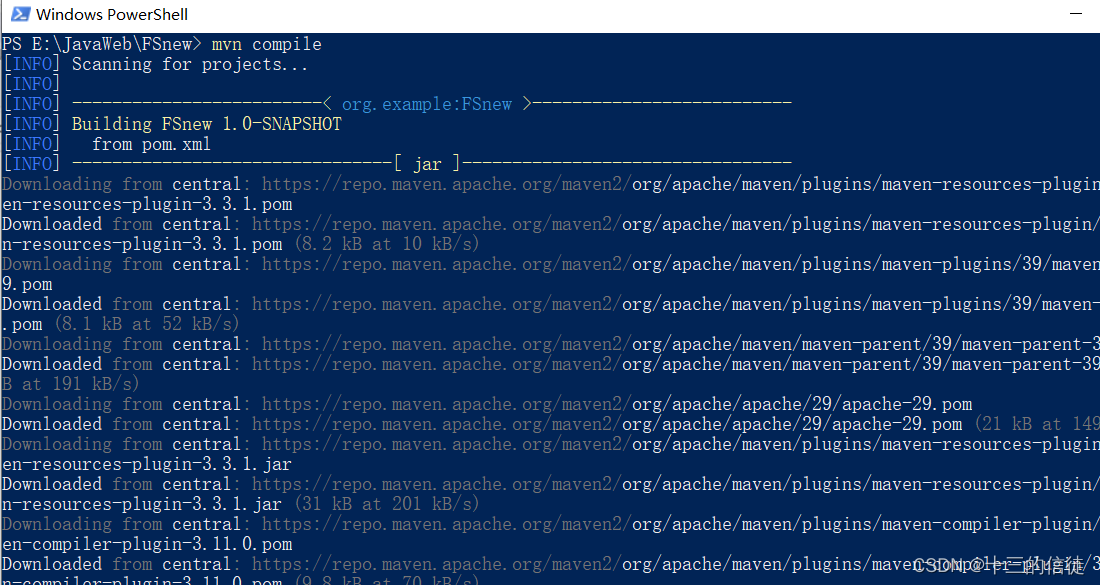
简单演示一下complie命令~
上面用的不是aliyun的私服,回去重新检查一下是没有删掉配置文件中默认的路径,修改后再次尝试test命令,效果如下:
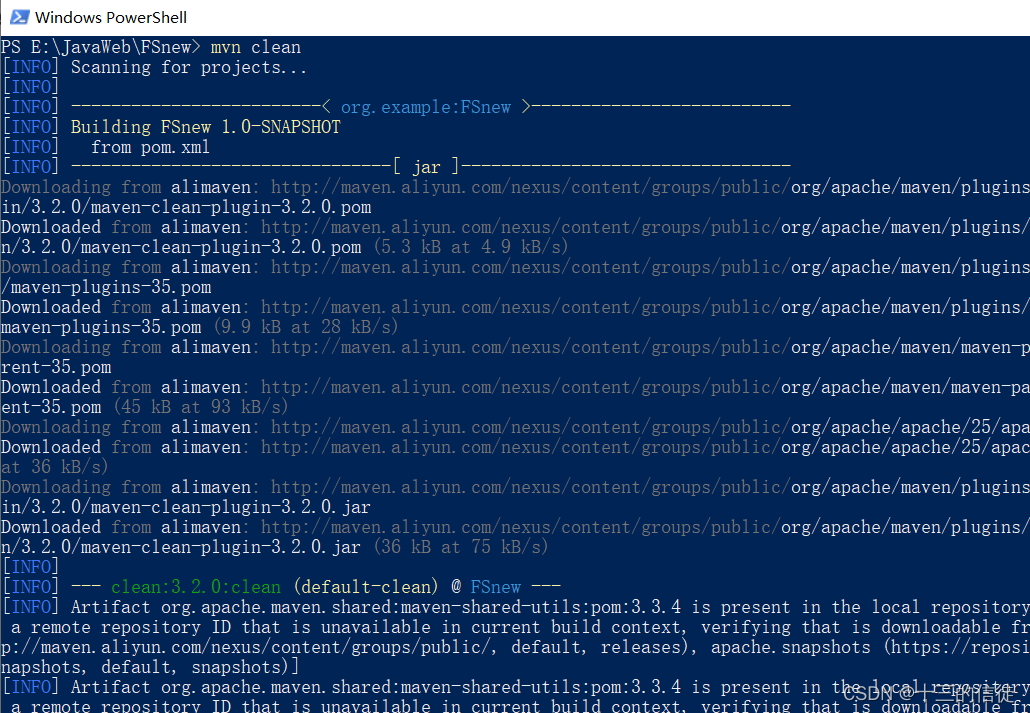
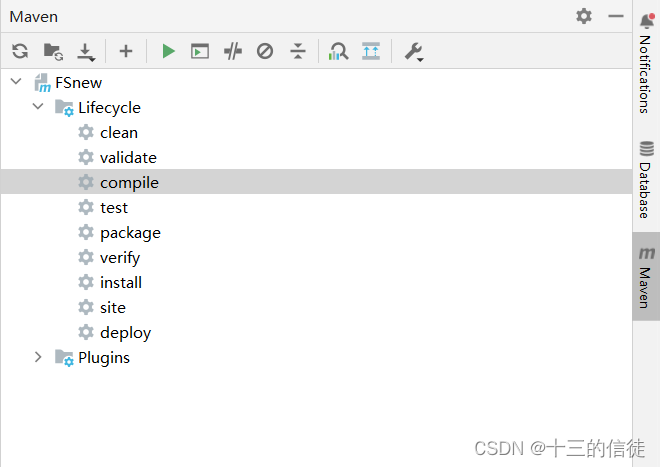
7.生命周期

四.依赖管理
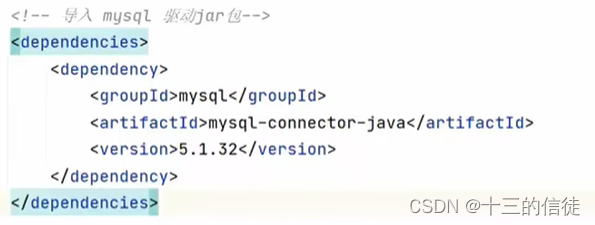
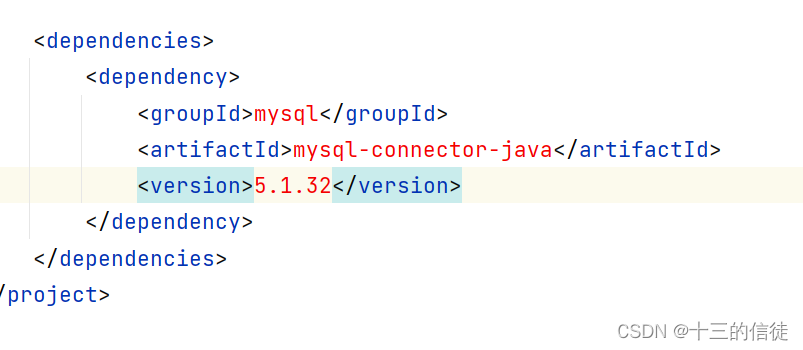
1.在pom.xml配置文件中编写<dependencies>标签
2.在其中,用<dependency>引入坐标
3.定义坐标的groupid、artificial、version等信息。
4.别忘了点击刷新按钮!
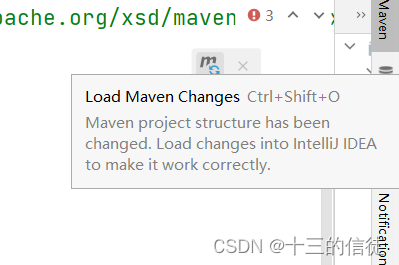
如下图(默认仓库的问题导致时间挺长的):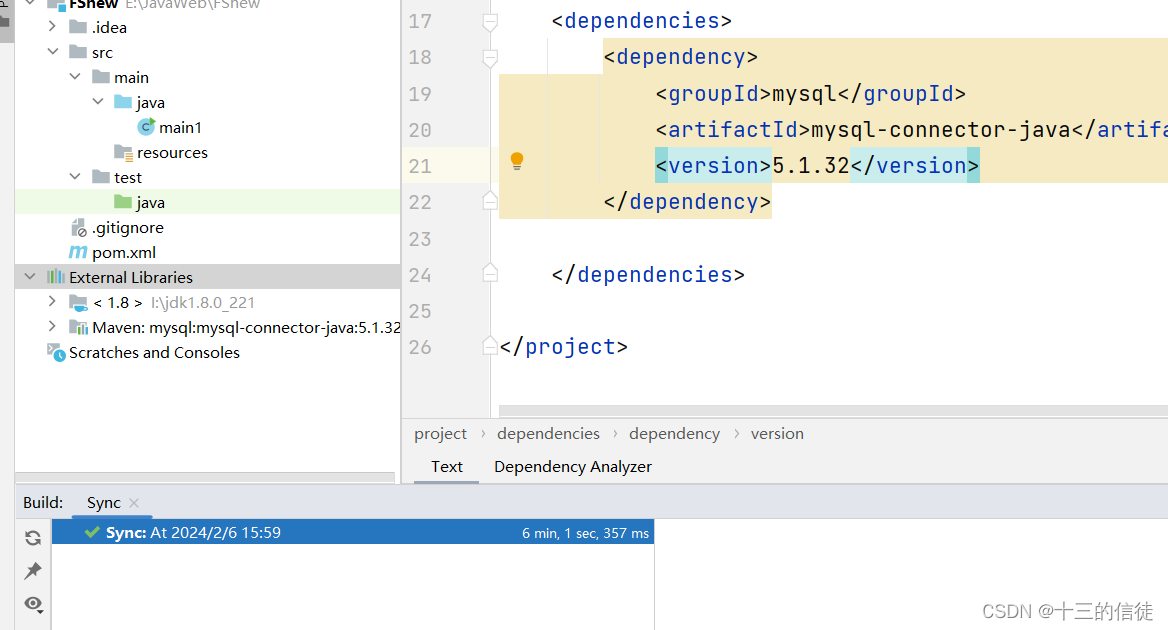
快捷方式导入坐标:右键选择如下
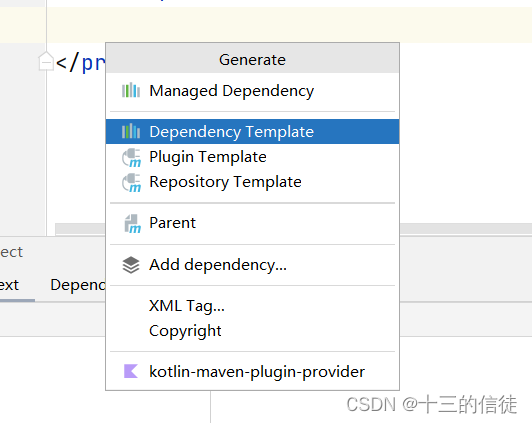
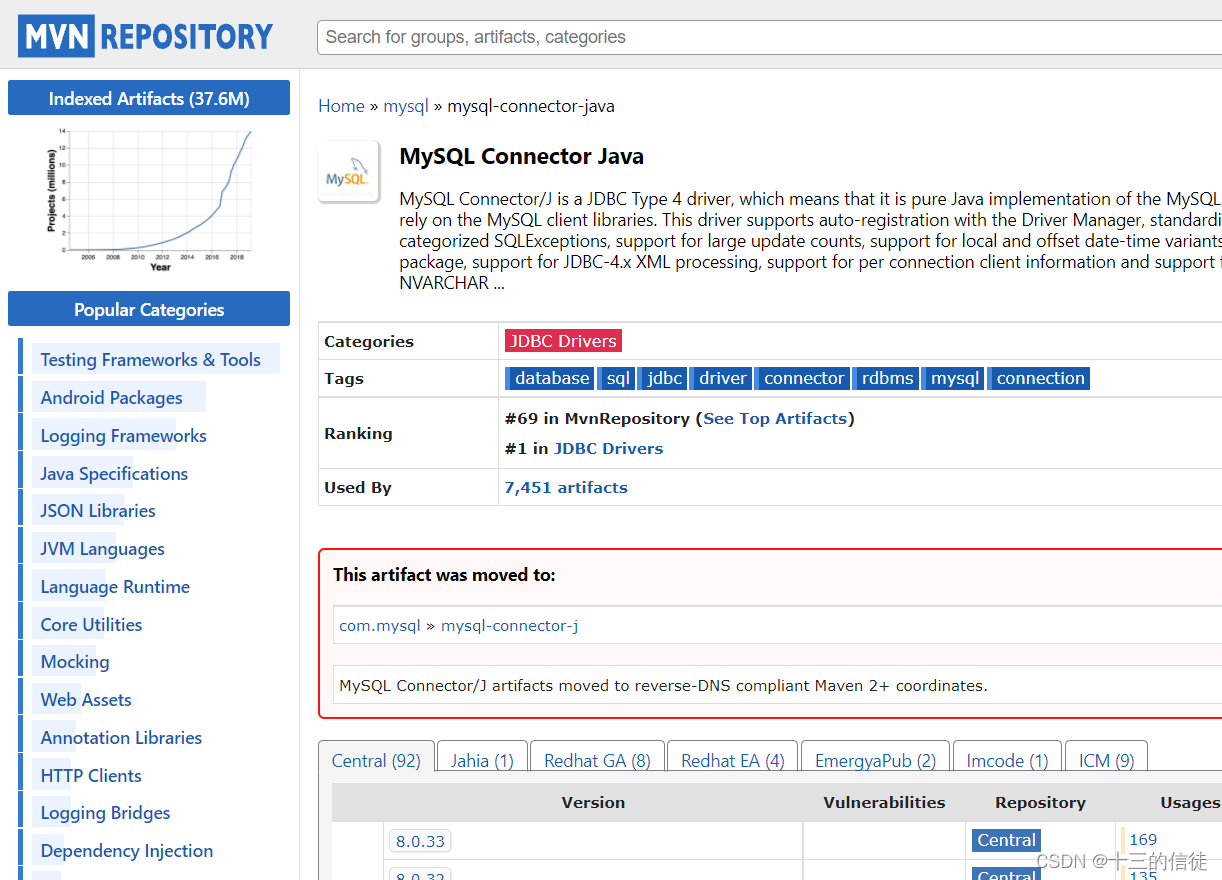
模版引用网址:
Maven Repository: mysql » mysql-connector-java

五.依赖范围
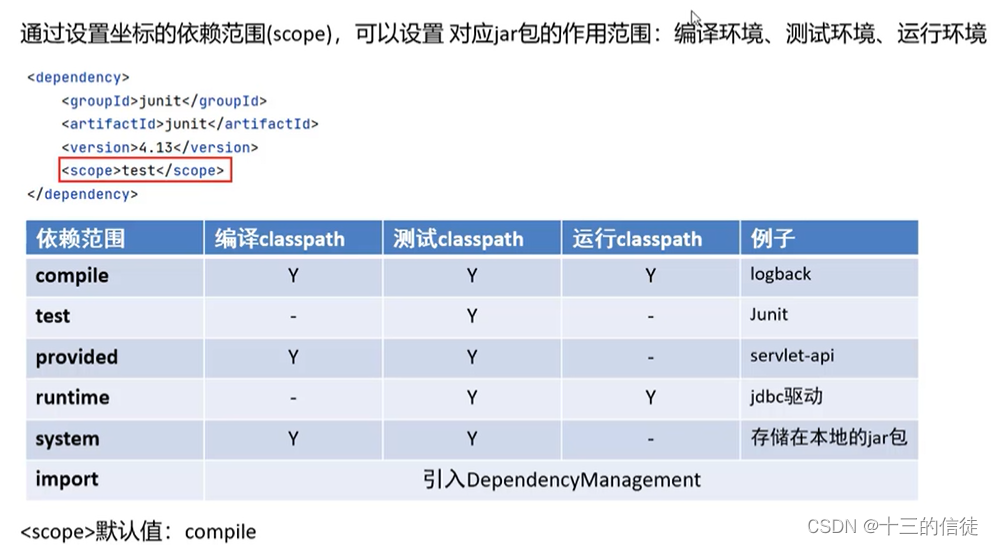
了解一下即可。