广州网站建设怎么样抖音代运营是做什么
相信有上线过自己的网站、小程序经验的同学深有体会,给服务加上 SSL 证书还挺麻烦的,尤其是没有运维经验的同学。本来最省事的方法是买个证书,但是一看价格,还是算了吧,动辄就是几万块一年。作为个人来说,这跟抢钱有什么区别。
那没有 ssl 不行吗?🤔 如果你不害怕自己的小网站被嵌入流量污染变成小yellow广告网站,还是建议你加下 ssl!

当你手里有超过1个以上的域名,如 a.com、b.com,之后你还对域名使用了多级域名部署不同的服务,如;api.a.com、openai.b.com、blog.b.com 那么这个时候一种是对每个域名都申请 ssl 证书,另外一种就是购买更贵的泛域名,支持 *.a.com。
除了对域名证书的申请还包括了这些域名证书的管理工作,你得知道他们什么时候到期,什么时候要更新。我见过有些互联网公司也有忘记更新域名的情况,从 https 跳转到了访问微信提示的页面。所以大家需要一款 自动续期、支持泛域名、可视化所有证书时效性、可配置CDN的一款工具!那么,他来了!
一、产品介绍
产品链接:
🔥httpsok一行命令,轻松搞定SSL证书自动续签。
https://httpsok.com/p/4dh3
(1)购买服务器
推荐购买香港服务器,这样通过域名访问就不需要备案。
(2)安装Nginx服务
登录到服务器后,输入以下命令,安装Nginx服务
yum install nginx -y启动nginx服务器
service nginx start(3)通过域名访问网站
添加一条DNS的A记录,将域名解析到刚刚的IP地址即可。
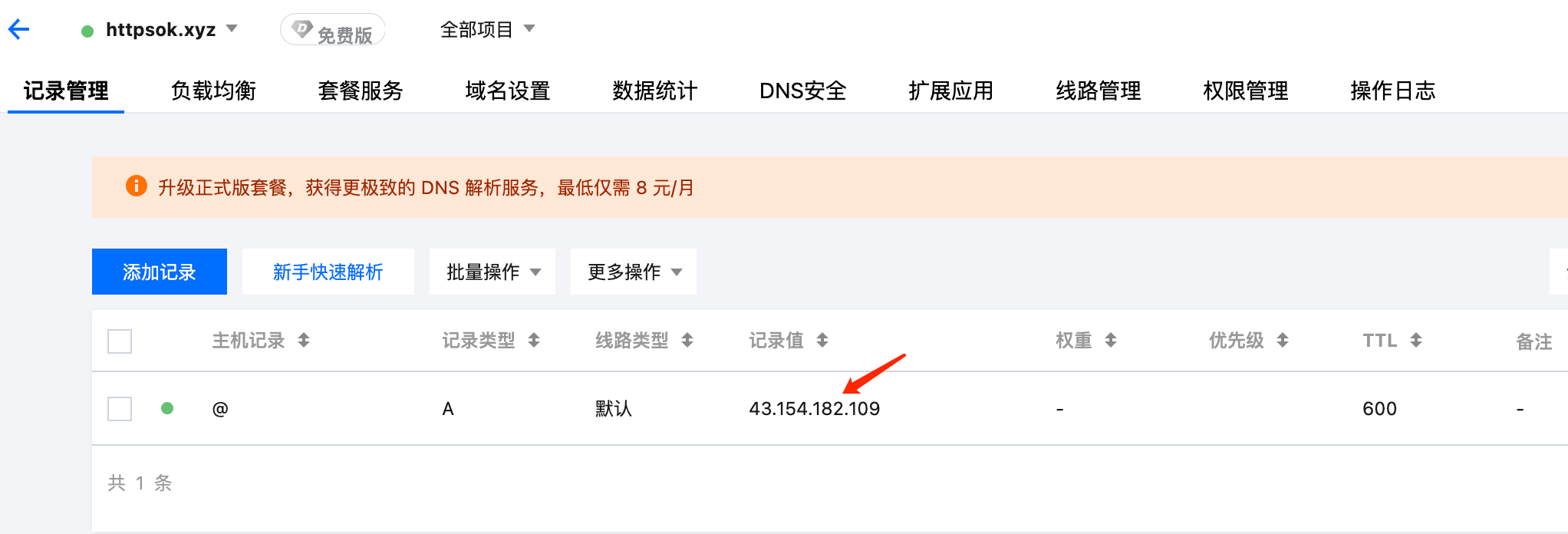
此时,可以通过域名访问刚刚的服务器了。

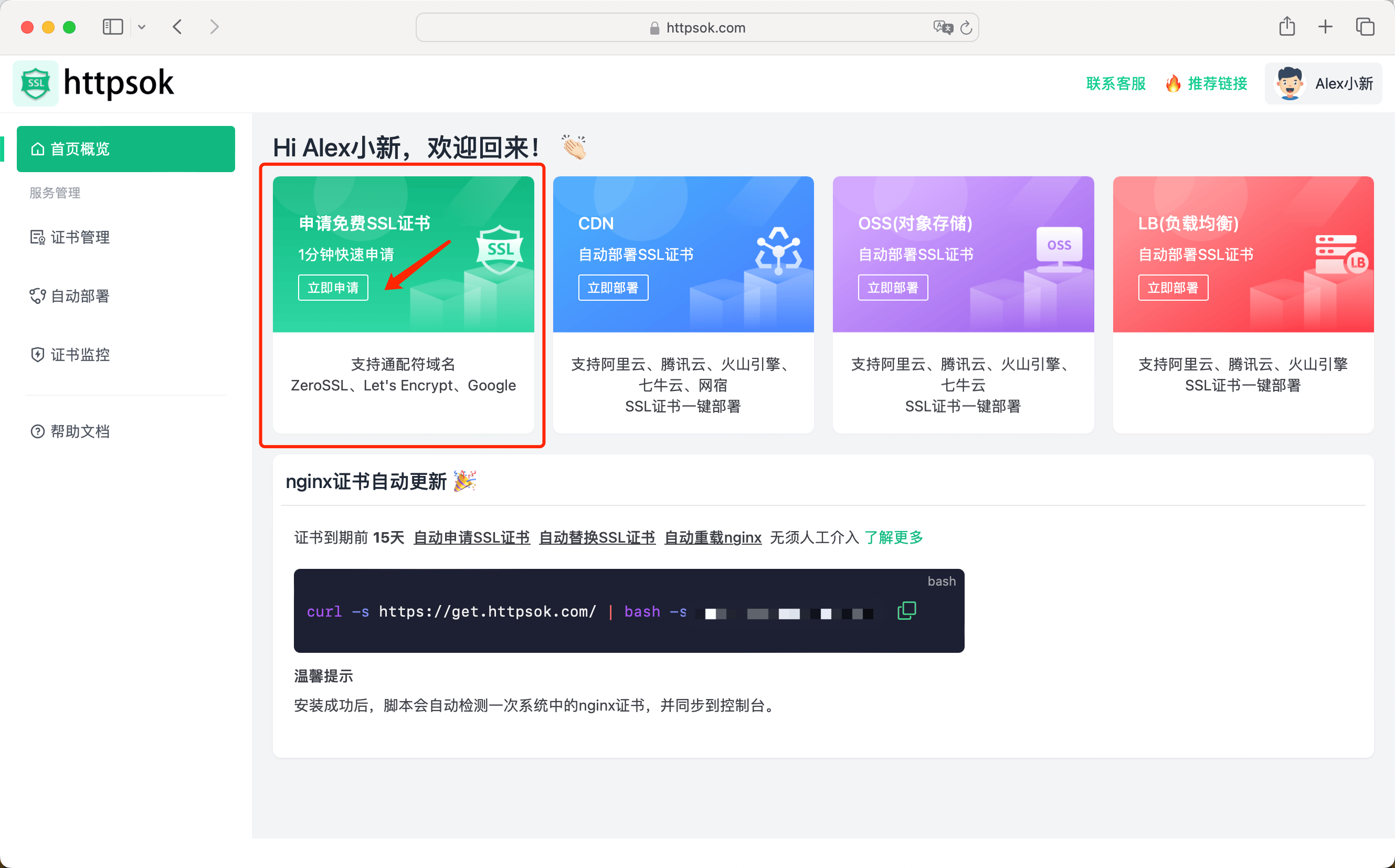
(4)申请SSL证书
打开 httpsok-SSL证书自动续期 ,登录后,点击【申请证书】
输入自己的域名(这里演示是 httpsok.xzy )并且回车
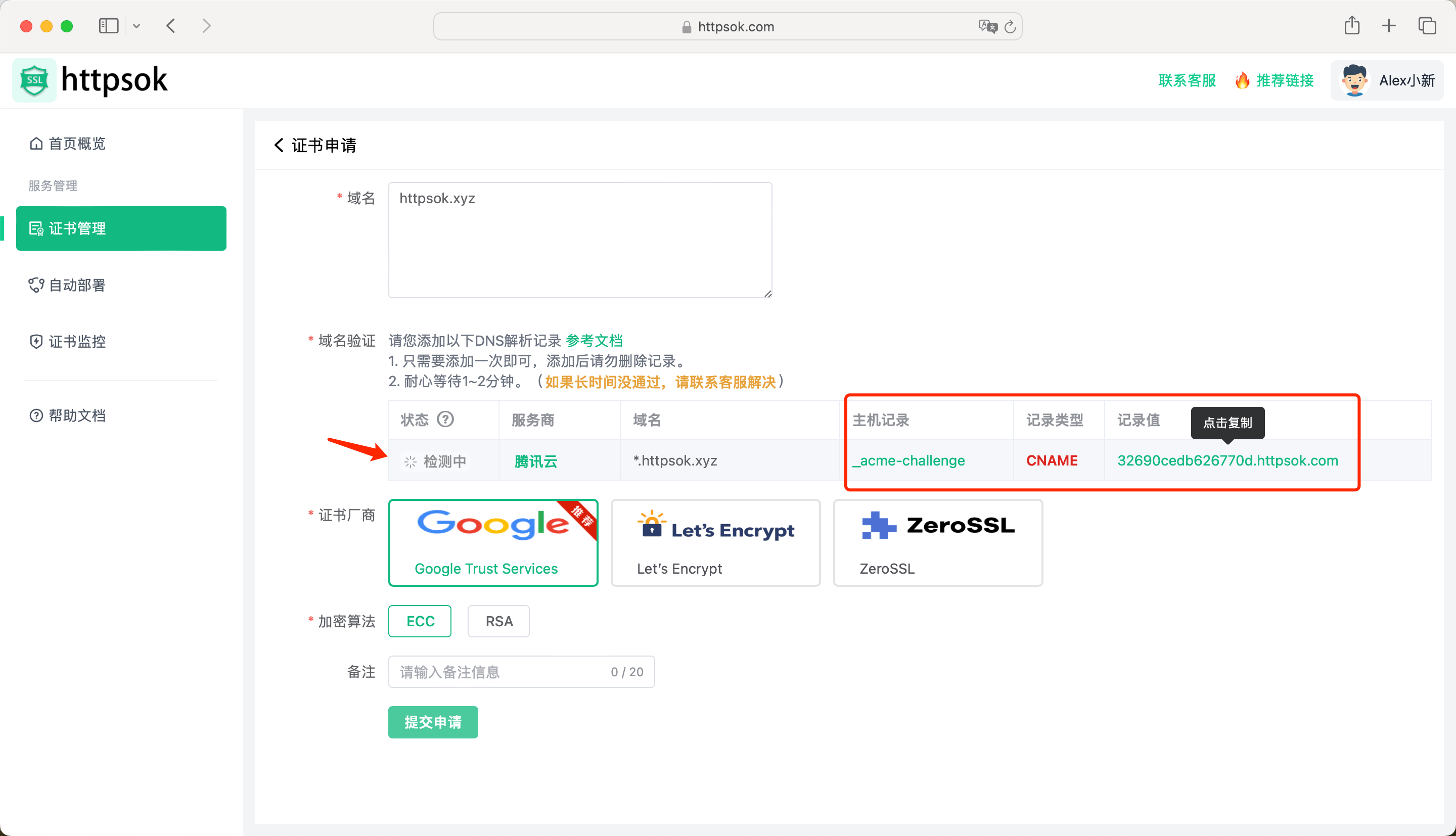
此时,会提示检测中,我们需要再到DNS添加一条 CNAME 类型的解析记录。
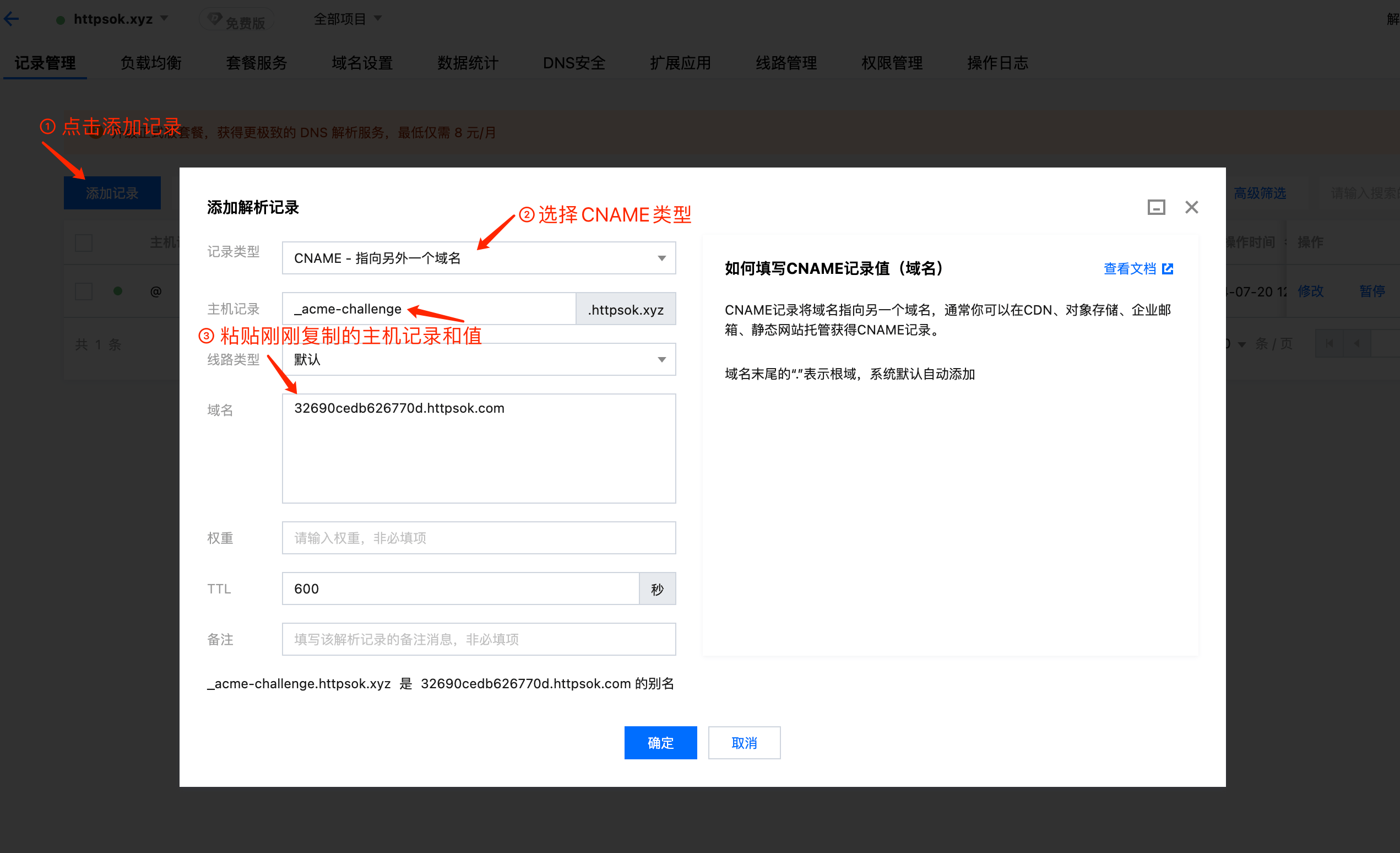
添加成功后,如下图所示。
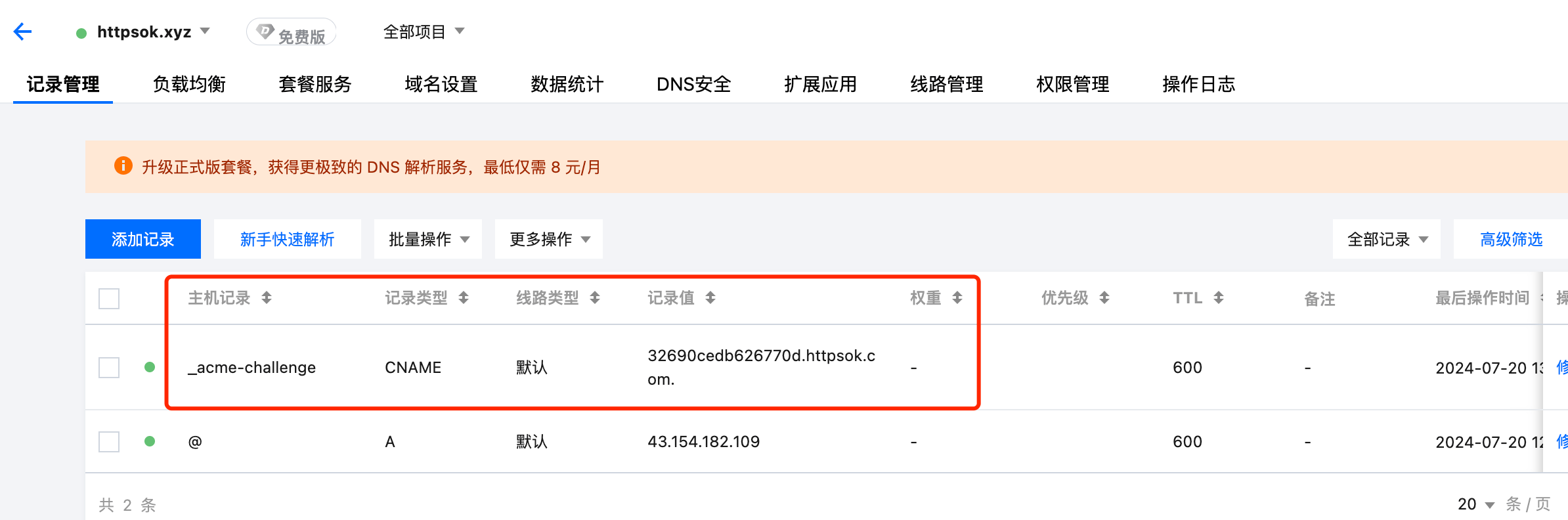
此时,再回到页面控制台,发现已经域名已经检测通过了。
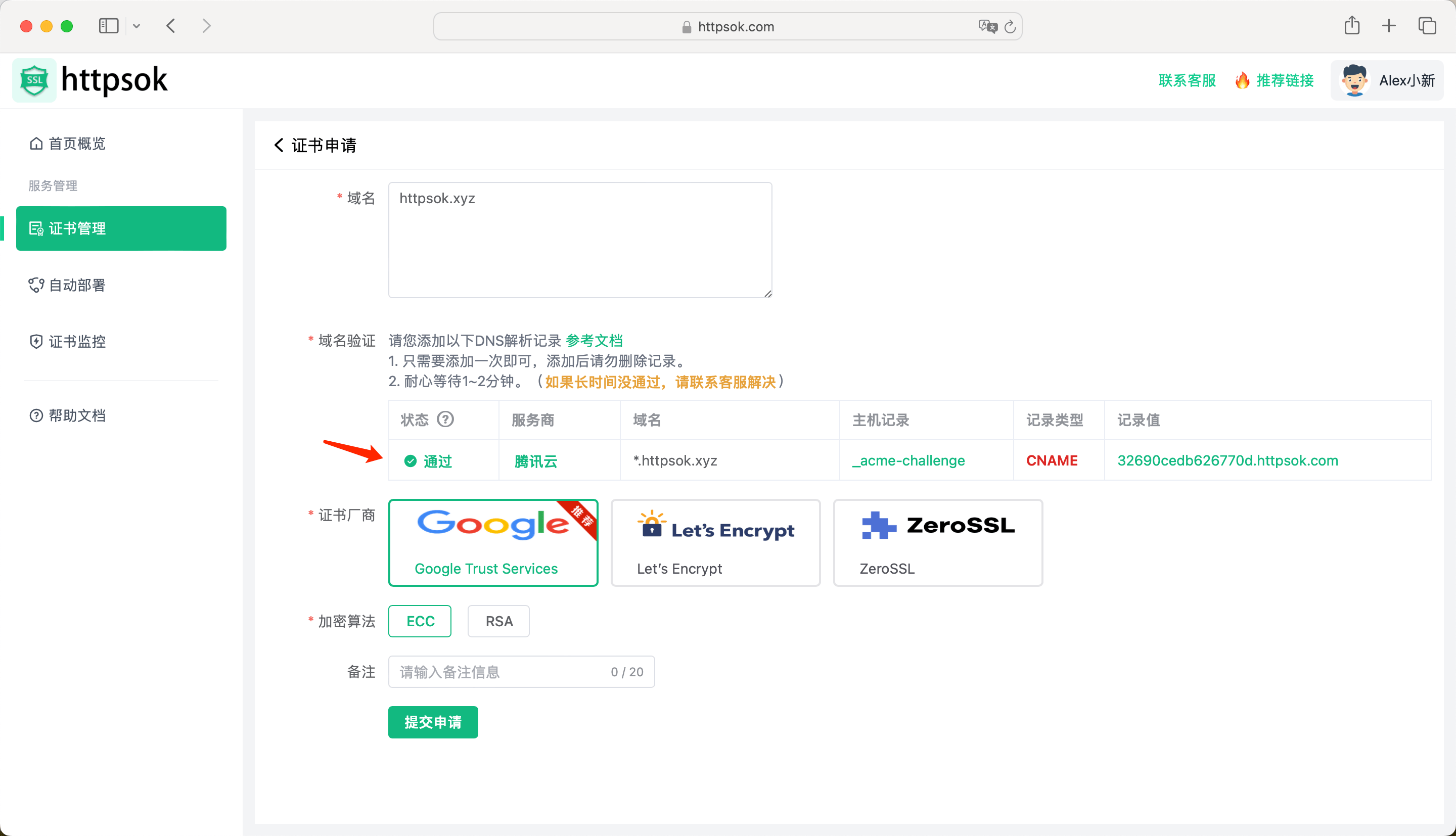
点击【提交申请】,证书进入申请中,等待1分钟左右,即可申请成功。
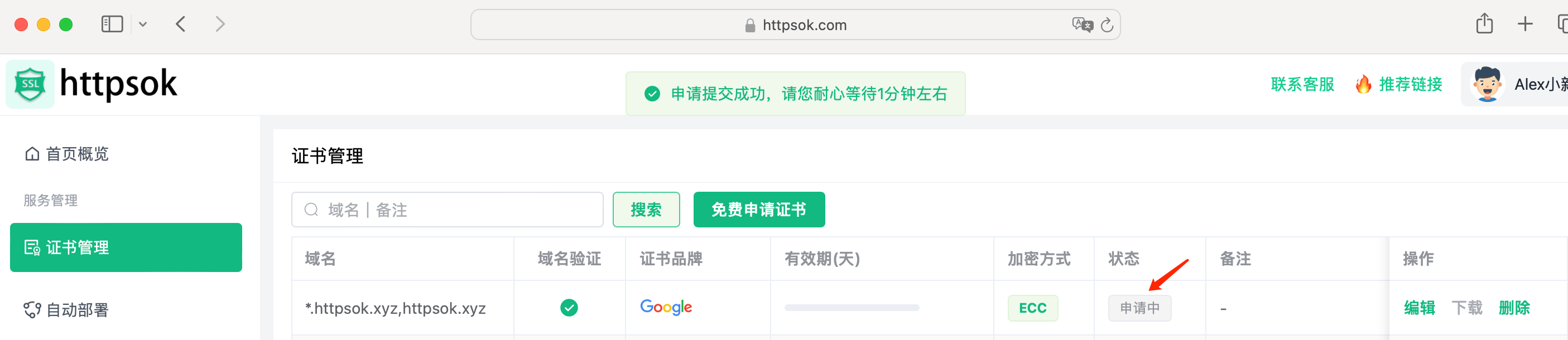
(5)部署SSL证书
nginx配置https站点
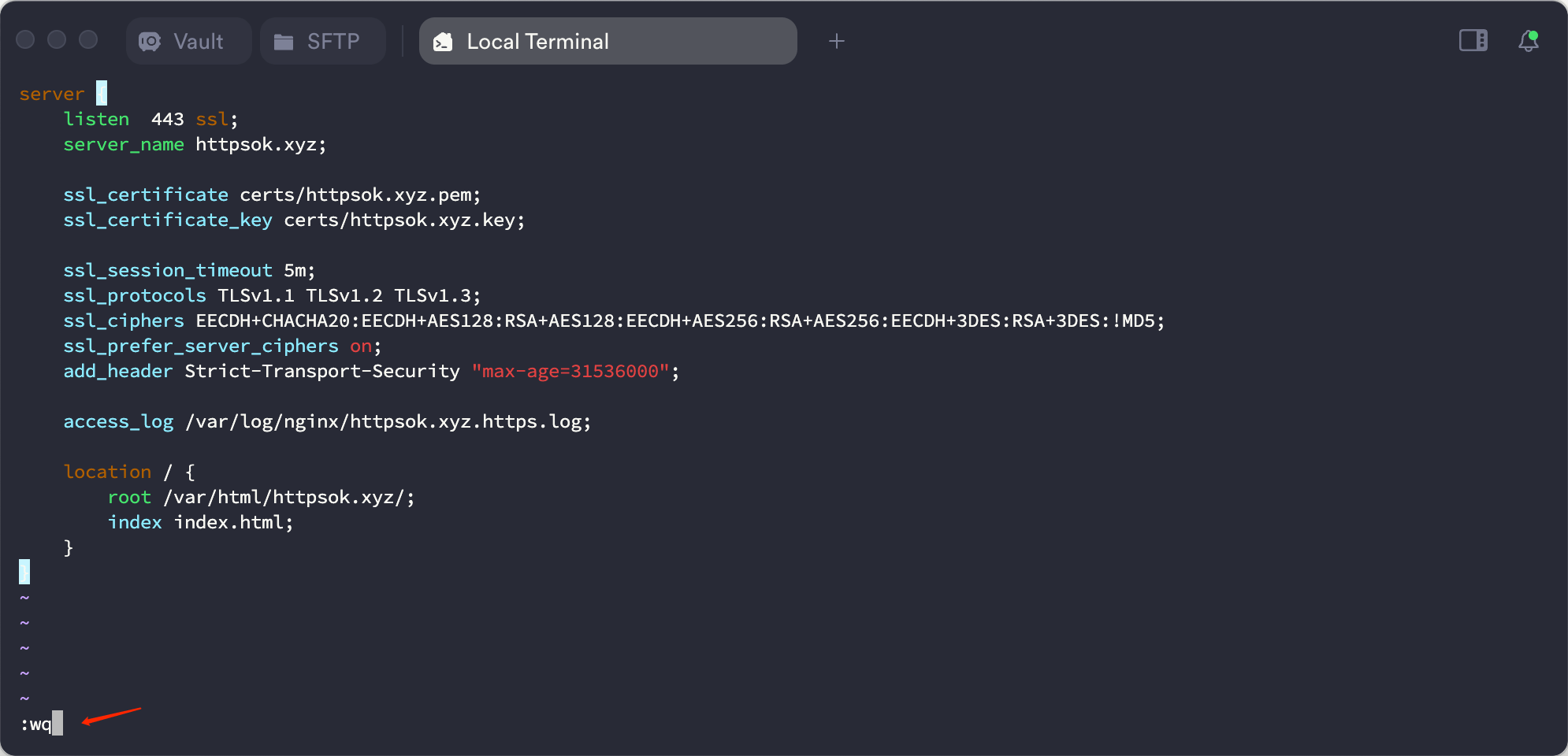
配置指令(请将 httpsok.xyz 替换成自己的域名)
nginx
server {listen 443 ssl;server_name httpsok.xyz;ssl_certificate certs/httpsok.xyz.pem;ssl_certificate_key certs/httpsok.xyz.key;ssl_session_timeout 5m;ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3;ssl_ciphers EECDH+CHACHA20:EECDH+AES128:RSA+AES128:EECDH+AES256:RSA+AES256:EECDH+3DES:RSA+3DES:!MD5;ssl_prefer_server_ciphers on;add_header Strict-Transport-Security "max-age=31536000";access_log /var/log/nginx/httpsok.xyz.https.log;location / {root /var/html/httpsok.xyz/;index index.html;}
}增加nginx站点配置文件(最佳实践 域名.conf)
bash
vim /etc/nginx/conf.d/httpsok.xyz.conf输入 i,进入insert模式 ,粘贴刚刚上面的配置指令。
然后按 ESC键,再输入再输入:wq ,保存并退出。
(6)安装 httpsok.sh并部署证书
回到控制台首页,点击按钮复制安装命令。
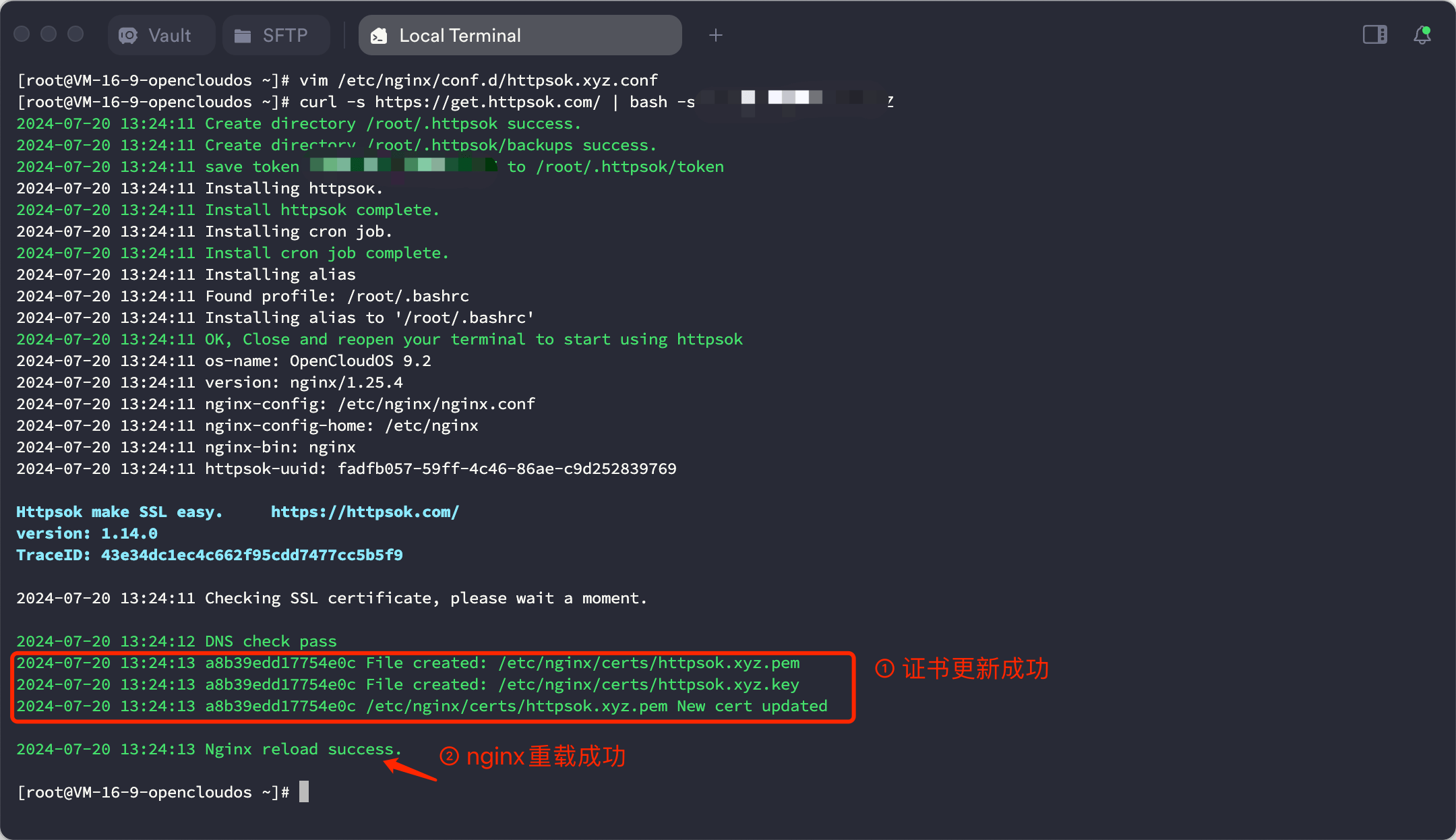
到服务器,粘贴并执行刚刚复制的命令,此时 自动更新SSL证书,并且自动重载nginx。
(7)通过HTTPS访问网站
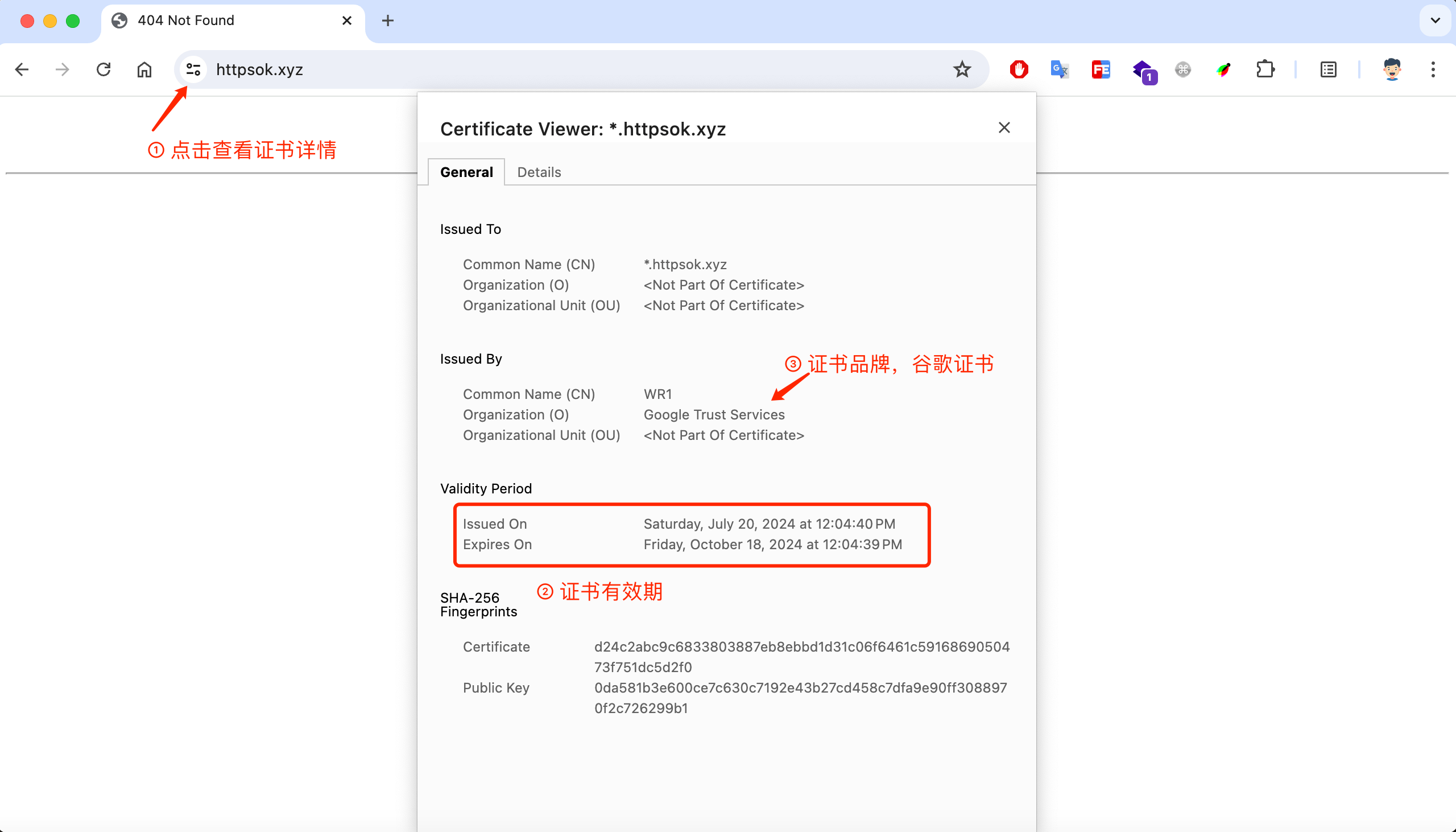
点击小锁,可以看到证书详情。(提示:网站404是因为没有部署页面文件,部署之后就不会了)
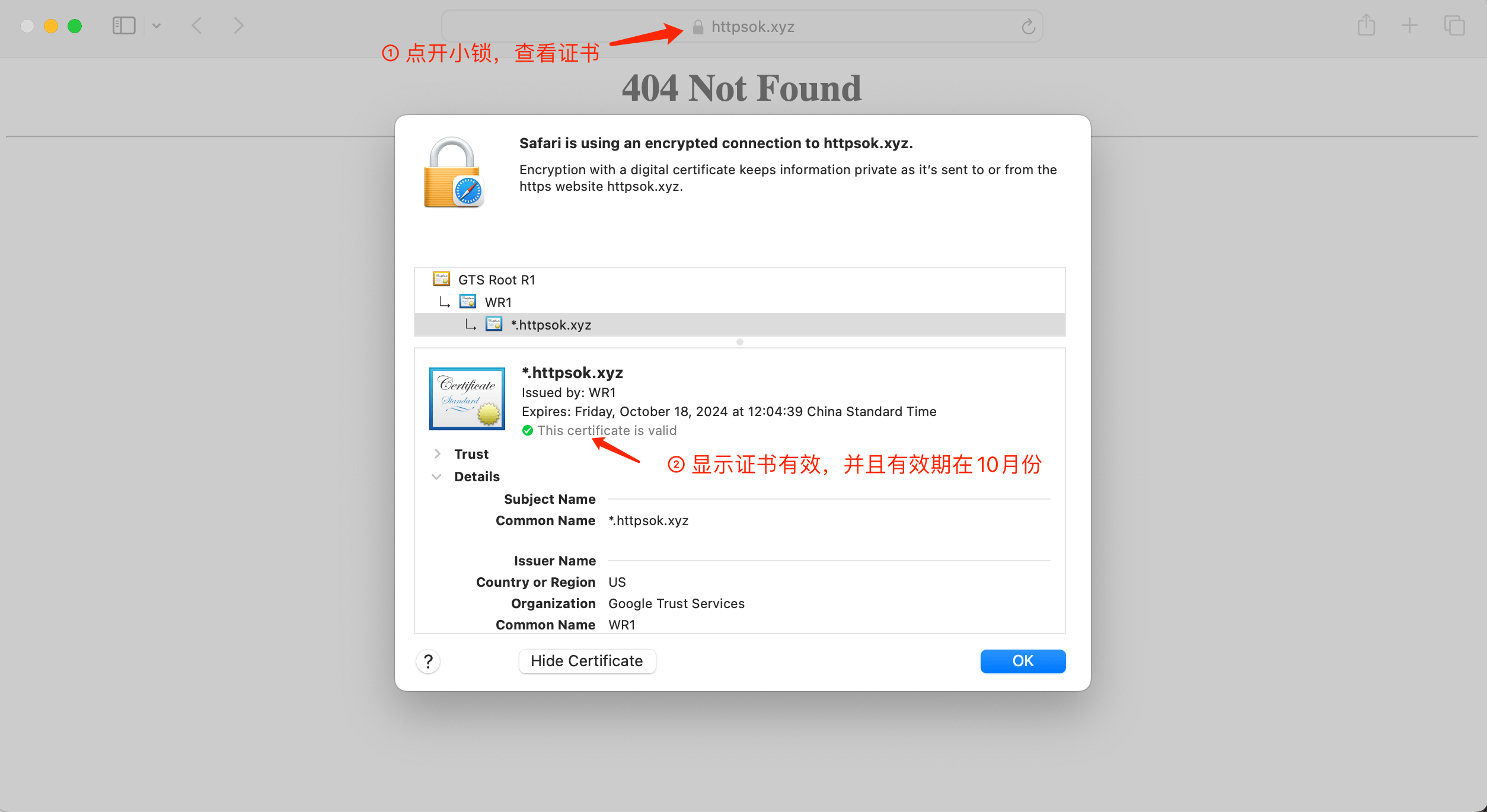
下面是谷歌浏览器查看证书方式
(二)更多 SSL(HTTPS)证书获取
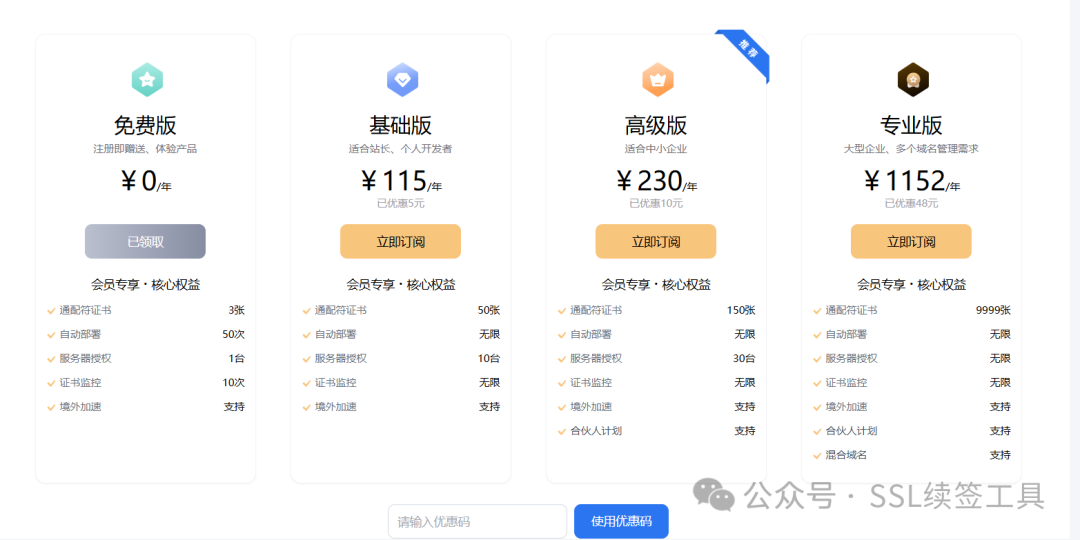
httpsok「订阅服务」中还有其他三种服务,包括基础版、高级版以及专业版,每个版本服务也有不同;
-
基本版证书数量增加到50张,服务器增加10台,适合站长、个人开发者;
-
高级版证书数量增加到150张,服务器增加到30台,适合中小企业;
-
专业版证书数量增加到9999张,服务器增加到无限台,并支持混合域名,大型企业、多个域名管理需求;
httpsok专属优惠码「DL44BVB3」- 马上订阅吧
点击链接直接使用:
https://httpsok.com/console/vip
好用的话,可以推荐转发给你的好友噢.