云计算 网站建设wordpress案例制作
WGAN前作:有原则的方法来训练GANs
论文:https://arxiv.org/abs/1701.04862
发表:ICLR 2017
本文是wgan三部曲的第一部。文中并没有引入新的算法,而是标是朝着完全理解生成对抗网络的训练动态过程迈进理论性的一步。

文中基本是理论公式的推导,看起来确实头大,偷懒就直接阅读网上整理好的资料了,参考
1:译文
2:生成模型(一):GAN - 知乎
3:令人拍案叫绝的Wasserstein GAN - 知乎
梯度消失
文章花了大量的篇幅进行数学推导,证明在一般的情况,如果Discriminator训练得太好,Generator就无法得到足够的梯度继续优化,而如果Discriminator训练得太弱,指示作用不显著,同样不能让Generator进行有效的学习。这样一来,Discriminator的训练火候就非常难把控,这就是GAN训练难的根源。
实验验证:基于DCGAN,分别训练1、10、25epoch,固定Generator,然后从头开始训练Discriminator,绘制出Generator目标函数梯度和训练迭代次数的关系如下。可以看到,经过25 epochs的训练以后,Generator得到的梯度已经非常小了,出现了明显的梯度消失问题。
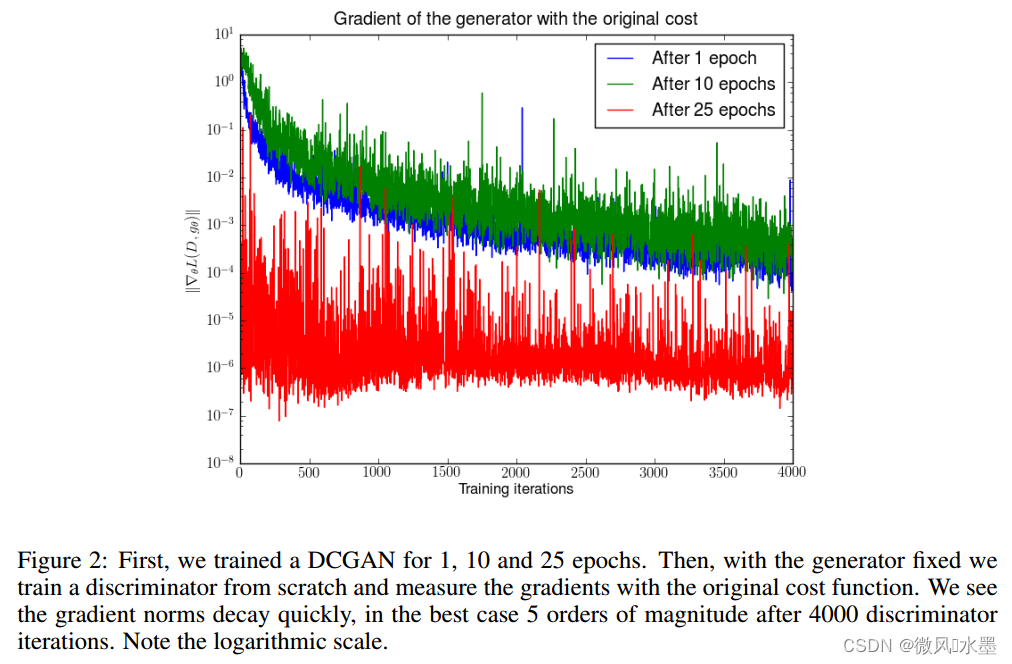
梯度不稳定
实验验证:基于DCGAN,分别训练1、10、25epoch,固定Generator,然后从头开始训练Discriminator,绘制出梯度信息。可以看出更有明显的梯度方差较大的缺陷,导致训练的不稳定。在训练的早期(训练了1 epoch和训练了10 epochs),梯度的方差很大,对应的曲线看起来比较粗,直到训练了25 epochs以后GAN收敛了才出现方差较小的梯度。
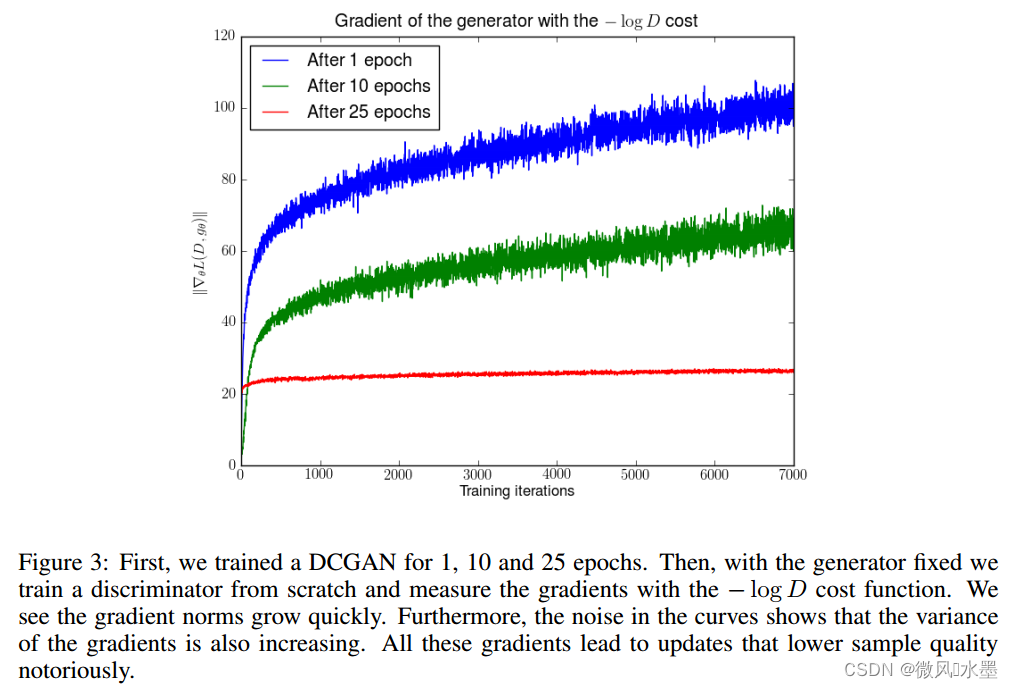
本文的解决方案: 添加噪声
为增加两个概率分布创造更高的重叠机会,一种解决方案是在判别器的输入上添加连续噪声.