防城港网站建设wordpress学生主题
相关链接
1、控制流平坦化进行AST 解析 AST网址
2、JS进制转换(Function.prototype.call)
1、断点调试mtgsig参数
这里mtgsig已经被拼到url中
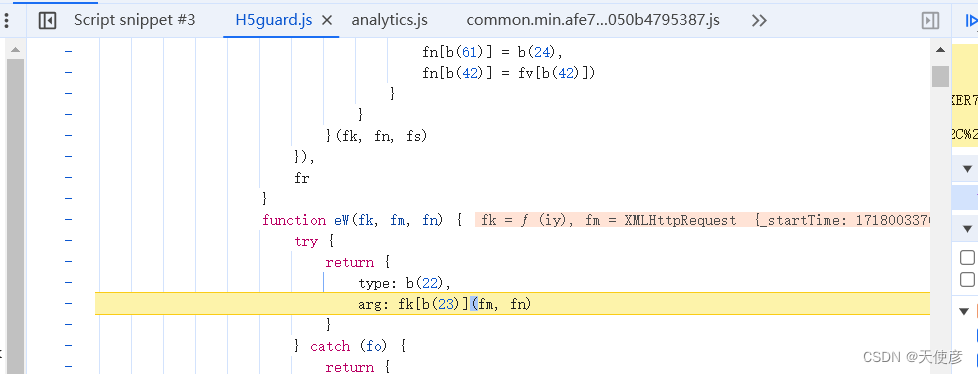
2、进入后mtgsig已经计算完, ir = he(this[b(4326)], !1), 就是加密函数
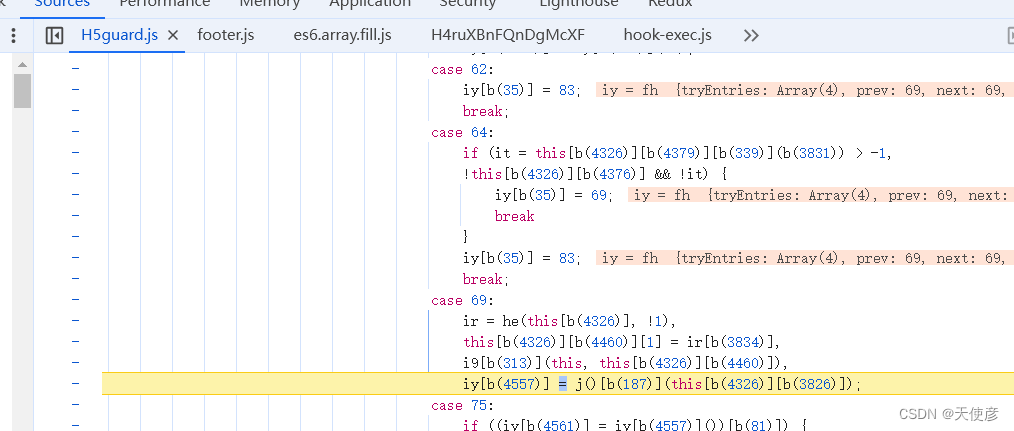

断点位置
三、观察mtgsig的值
{"a1":"1.1",
"a2":1718468767104,
"a3":"xuy1zzu91zv25262z3259x8wx343501480981x32u65979585511yvv0",
"a5":"EO/9ybr3Lu84Fo+S/aTJ",
"a6":"hs1.4aOG4x69iuIGtADfqn9IKcfnvTEIjKjY9H6EeuMkKzu5/rXMEfcX4PkryisYfKr+LFobgDNzDmFr3cb73An0DxQ==",
"x0":4,
"d1":"3d8e870992de460f5333124faf50c103"}{"a1":"1.1",
"a2":1718468774352,
"a3":"xuy1zzu91zv25262z3259x8wx343501480981x32u65979585511yvv0",
"a5":"EO/9yMr3Lu84Fo+S/aTJ",
"a6":"hs1.4aOG4x69iuIGtADfqn9IKcfnvTEIjKjY9H6EeuMkKzu5/rXMEfcX4PkryisYfKr+LFobgDNzDmFr3cb73An0DxQ==",
"x0":4,
"d1":"6739982310bed1200c8b526977874905"}{"a1":"1.1","a2":1718469128184,
"a3":"xuy1zzu91zv25262z3259x8wx343501480981x32u65979585511yvv0",
"a5":"EO/98br3Lu84Fo+S/aTJ",
"a6":"hs1.4aOG4x69iuIGtADfqn9IKcfnvTEIjKjY9H6EeuMkKzu5/rXMEfcX4PkryisYfKr+LFobgDNzDmFr3cb73An0DxQ==",
"x0":4,
"d1":"0f681765340220edcd3b4a5b3b6a3781"}
四、断点调试加密过程
仔细观察上面mtgsig的值 发现 a2 是时间戳,a5 需要破解 , d1需要破解 , 其他是固定的
var guardOwl, md5 = {md5: function(s) {return hex(md51(s))},md5Array: md51,md5ToHex: hex
};md5.s(ik);
ij = N[510] // 4294967295
ih = hU& ij
ij = fZ(null , ih)
ik = new Uint8Array(fW(i5)[concat](ij))im = md5( md5 , ik) // cee70b7578ff51b84f14efa2efbc7891i5=hs1.4aOG4x69iuIGtADfqn9IKcfnvTEIjKjY9H6EeuMkKzu5/rXMEfcX4PkryisYfKr+LFobgDNzDmFr3cb73An0DxQ==
io = new Uint8Array(fW(i5))iq = md5( md5 , io )
ir = fY(null , iq) 得到 ,
is = [fm[b1], fm[b2 ],fm[b3 ], fm[b5 ] ]
it = h6( null , h8(null , ir , JOSN.stringify(is))) // "EO/9JriScRkoUfM7cAq9Cc=="
iv = hb( ib , hU)
iw = fZ(null , iv )
ix = d0 ( null , fK ) ["dfpId"] // a3 : "xuy1zzu91zv25262z3259x8wx343501480981x32u65979585511yvv0"
iy = hb(null , new Uint8Array(fW(it)) , hU )
iz = fZ(null , iy )
iA = hex(md5 , [iv , iy , iv ^ ih ,iv ^ iy - ih ] )
iB = h1(null , concat ( iw , iz , iA) )
iE = iy
iC = a1 : fs , a2 : hU , a3 : ix , a5 : it , a6 : i5 , x0 :4 ,
XXXXXXX
iF = a1 + a2 + a3 + iB + iE + im
iG = md51( md5 , new Uint8Array(fW(iF)) )
iH = ih | ( ih << iC [x0] ) << ( ih << iC [x0] ) XXXXX
iG[0] = iG[0] ^ iH
iG[1] = iG[1] ^ iE
iG[2] = iG[2] ^ iE ^ iH
iG[3] = iG[3] ^ iG[0]
iI = hex(md5 , iG )
iC[d1] = il
iK = iI
iM = parstInt ( null , iK (0x 两位一组 ))
iJ = [ iM = parstInt ( null , iK (0x 两位一组 )) ]
iL < iK.length false
N[1145 ]
iO = hf ( null , fw )
iJ[12] = iJ[0] ^ iJ[4] ^ iO [0]
iJ[13] = (iJ[1 ] ^ iJ[5 ] ) ^ iO [1 ]
iJ[14] = iJ[2 ] ^ iJ[6 ] ^ iO [2 ]
iJ[15] = iJ[3 ] ^ iJ[7 ] ^ iO [3 ]iJ[9] = iJ[4 ] ^ iJ[5 ] ^ iJ[5 ] & 189 iJ[10] = ( iJ[5 ] ^ iJ[6] ^ iJ[1] ) & N[1287] iJ[11] = ( iJ[6 ] ^ iJ[7] ^ iJ[2] ) & N[1312]
iP = fE [ N[1321] ]
iP [ 0 ] iP [1] iP [2] iP [3] iP [4] iP [5] 1 1 1iJ[9] |= T[T.length - 1]; iJ[11] |= 1;iJ[8] = iJ[9] ^ iJ[10] ^ iJ[11] ^ iJ[12] ^ iJ[13] ^ iJ[14] ^ iJ[15]
iQ = '' iR = ''
if( iJ [i] < 16){1、小于 16 iJ [i] < 10 // 4 -> 04 2、大于等于16 g.call(182['toString'], 126 , 16) // 十六进制转换?d1: 实现方案:Function.prototype.call.call(17['toString'], 125, 16).padStart(2, '0');
}
iS是最终结果, 进 796 第15次停 计算的 iQ 加上两位 就是d1