做网站找哪家好熊掌号做网站营销
在nacos中添加配置文件
在配置列表中添加配置,
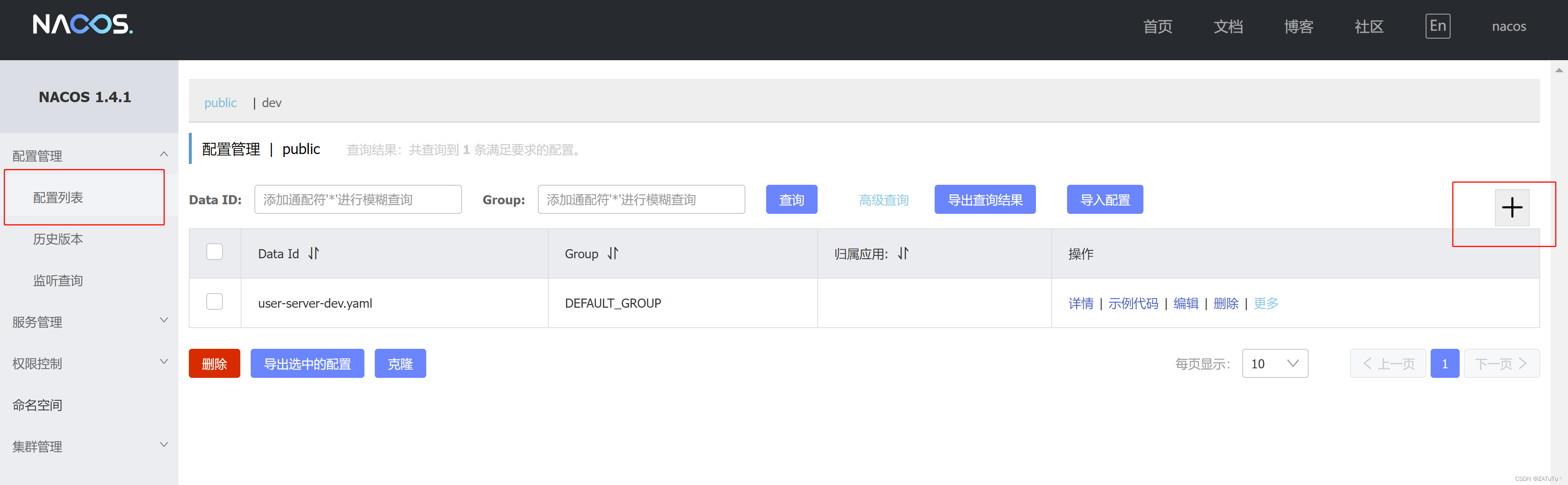
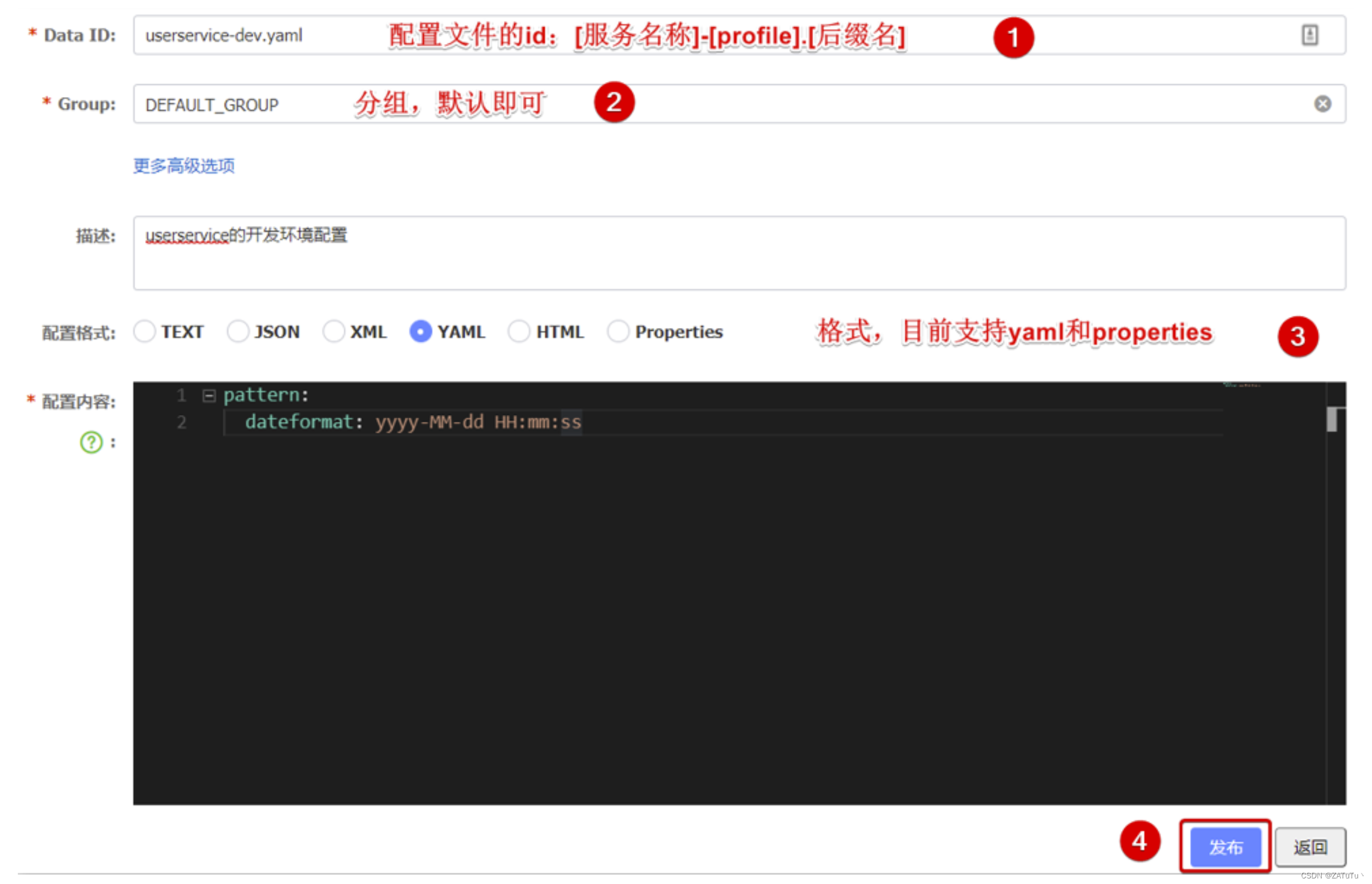
注意:项目的核心配置,需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。
从微服务拉取配置
微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。
但如果尚未读取application.yml,又如何得知nacos地址呢?
因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,流程如下:
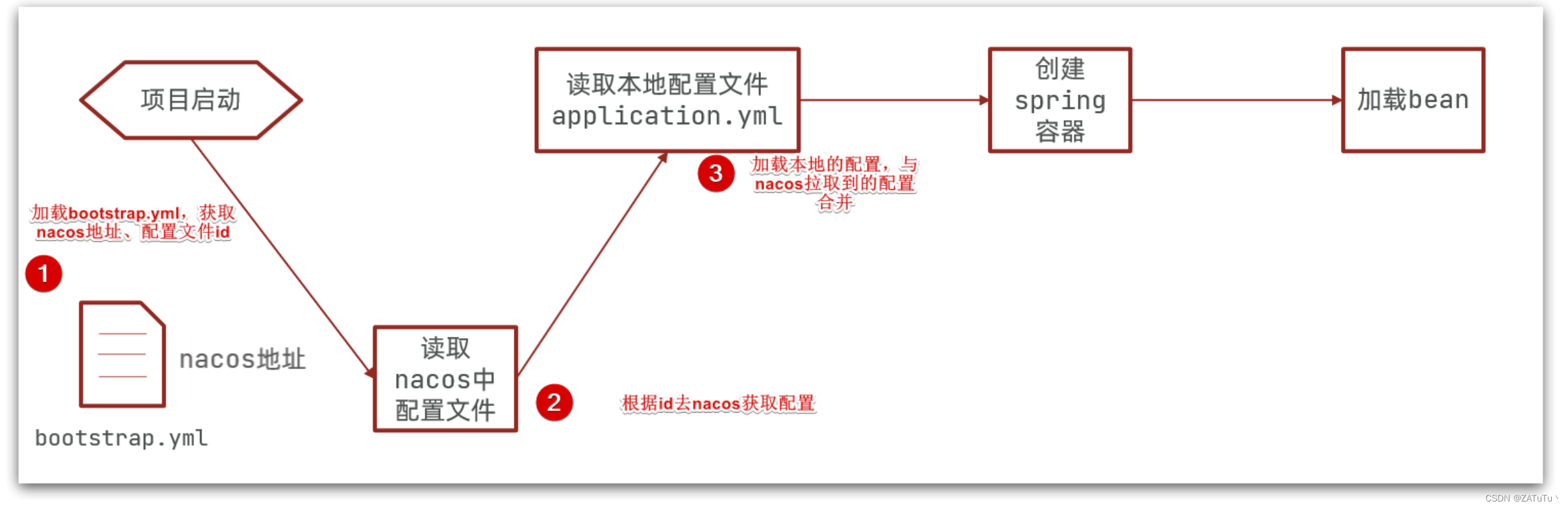
bootstrap.yaml是一种先导的文件,他的执行位于application.yml,可以用他来告诉整个服务的热配置的位置
首先我们引入依赖
首先,在user-service服务中,引入nacos-config的客户端依赖:
<!--nacos配置管理依赖-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
我们在与application.yml同样的目录下建立了bootstrap.yaml文件
# 引导文件
# 他的执行时间比application.yml还要靠前spring:application:name: user-server # 服务名称profiles:active: dev #开发环境,这里是devcloud:nacos:server-addr: localhost:8848 # Nacos地址config:file-extension: yaml # 文件后缀名
他主要告诉了三件事,我们服务的名称、开发环境以及文件的后缀。这与我们Nacos中的配置的Data ID是相互对应的。

利用代码读取nacos配置
方式一:
在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置:
我们利用@Value("${pattern.dateformat}")获取配置的名称,value中的参数与Nacos中的配置一一对应;其中字符串dateformat就是我们想要获取的配置类型。同时在@Value注入的变量所在类上添加注解@RefreshScope:
@Slf4j
@RestController
@RequestMapping("/user")
@RefreshScope // 实时扫描
public class UserController {@Autowiredprivate UserService userService;@Value("${pattern.dateformat}")private String dateformat;@GetMapping("now")public String now(){return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));}方式二
使用@ConfigurationProperties注解代替@Value注解。
在user-service服务中,添加一个类,读取patterrn.dateformat属性:
@ConfigurationProperties(prefix = “pattern”)进行前缀扫描
package cn.itcast.user.config;import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;@Component@Data@ConfigurationProperties(prefix = "pattern")public class PatternProperties{private String dateformat;}
>@Autowired
>private PatternProperties patternProperties;
将这个配置类的bean声明进来
利用get函数获取字符串【patternProperties.getDateformat()】
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {@Autowiredprivate UserService userService;@Autowiredprivate PatternProperties patternProperties;@GetMapping("now")public String now(){return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));}// 略
}