文章目录
- SpringBoot整合Easy-ES操作演示文档
- 1 概述及特性
-
- 2 整合配置
- 2.1 导入POM
- 2.2 Yaml配置
- 2.3 @EsMapperScan 注解扫描
- 2.4 配置Entity
- 2.5 配置Mapper
- 3 基础操作
- 3.1 批量保存
- 3.2 数据更新
- 3.3 数据删除
- 3.4 组合查询
- 3.5 高亮查询
- 3.6 统计查询
- 4 整合异常
-
SpringBoot整合Easy-ES操作演示文档
1 概述及特性
1.1 官网
- Easy-ES官网: https://www.easy-es.cn/
- 官方示例: https://gitee.com/dromara/easy-es/tree/master/easy-es-sample
- 参考链接: https://blog.51cto.com/yueshushu/6193710
1.2 主要特性
- **零侵入:**针对ES官方提供的RestHighLevelClient只做增强不做改变,引入EE不会对现有工程产生影响,使用体验如丝般顺滑。
- **损耗小:**启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作。
- 自动化: 全球领先的哥哥你不用动,索引我全自动模式,帮助开发者和运维杜绝索引困扰。
- 智能化: 根据索引类型和当前查询类型上下文综合智能判断当前查询是否需要拼接.keyword后缀,减少小白误用的可能。
- **强大的 CRUD 操作:*内置通用 Mapper,仅仅通过少量配置即可实现大部分 CRUD 操作,更 有强大的条件构造器,满足各类使用需求。
- **支持 Lambda 形式调用:**通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错段。
- **支持主键自动生成:**支持多种主键策略,可自由配置,完美解决主键问题。
- **支持 ActiveRecord 模式:**支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作。
- **支持自定义全局通用操作:**支持全局通用方法注入( Write once, use anywhere )。
- **内置分页插件:**基于RestHighLevelClient 物理分页,开发者无需关心具体操作,且无需额外配置插件,写分页等同于普通 List 查询,比MP的PageHelper插件用起来更简单,且保持与其同样的分页返回字段,无需担心命名影响。
- **MySQL功能全覆盖:**MySQL中支持的功能通过EE都可以轻松实现。
- **支持ES高阶语法:**支持聚合,嵌套,父子类型,高亮搜索,分词查询,权重查询,Geo地理位置查询,IP查询等高阶语法,应有尽有。
- **良好的拓展性:*底层仍使用RestHighLevelClient,可保持其拓展性,开发者在使用EE的同时, * 仍可使用RestHighLevelClient的所有功能。
2 整合配置
2.1 导入POM
- Latest Version: 2.0.0-beta4
<dependency><groupId>org.dromara.easy-es</groupId><artifactId>easy-es-boot-starter</artifactId><version>${Latest Version}</version>
</dependency>
2.2 Yaml配置
easy-es:enable: trueaddress: 10.15.20.11:9200schema: httpusername:password:keep-alive-millis: 18000global-config:process-index-mode: smoothlyasync-process-index-blocking: trueprint-dsl: truedb-config:map-underscore-to-camel-case: trueid-type: customizefield-strategy: not_emptyrefresh-policy: immediateenable-track-total-hits: true
2.3 @EsMapperScan 注解扫描
- 标注与主启动类上,功能与MP的@MapperScan一致。
package com.xs.easy;import org.dromara.easyes.starter.register.EsMapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.EnableConfigurationProperties;@EsMapperScan("com.xs.easy.mapper")
@EnableConfigurationProperties
@SpringBootApplication
public class XsEasyApplication {public static void main(String[] args) {SpringApplication.run(XsEasyApplication.class, args);}}
2.4 配置Entity
package com.xs.easy.entity;import lombok.Data;
import lombok.experimental.Accessors;
import org.dromara.easyes.annotation.HighLight;
import org.dromara.easyes.annotation.IndexField;
import org.dromara.easyes.annotation.IndexId;
import org.dromara.easyes.annotation.IndexName;
import org.dromara.easyes.annotation.rely.Analyzer;
import org.dromara.easyes.annotation.rely.FieldStrategy;
import org.dromara.easyes.annotation.rely.FieldType;
import org.dromara.easyes.annotation.rely.IdType;
@Data
@Accessors(chain = true)
@IndexName(value = "easy-es-document", shardsNum = 3, replicasNum = 2, keepGlobalPrefix = true, maxResultWindow = 100)
public class Document {@IndexId(type = IdType.CUSTOMIZE)private String id;private String title;@HighLight(mappingField = "highlightContent")@IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART)private String content;@IndexField(strategy = FieldStrategy.NOT_EMPTY)private String creator;@IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")private String gmtCreate;@IndexField(exist = false)private String notExistsField;@IndexField(fieldType = FieldType.GEO_POINT)private String location;@IndexField(fieldType = FieldType.GEO_SHAPE)private String geoLocation;@IndexField(value = "wu-la", fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_SMART, fieldData = true)private String customField;private String highlightContent;private Integer starNum;
}
2.5 配置Mapper
package com.xs.easy.mapper;import com.xs.easy.entity.Document;
import org.dromara.easyes.core.core.BaseEsMapper;
public interface DocumentMapper extends BaseEsMapper<Document> {}
3 基础操作
3.1 批量保存
public Integer insertES(int num) {List<Document> lis = new ArrayList<>();for (int i = 0; i < num; i++) {Document document = new Document();document.setId(ChineseUtil.randomNumber(1, 1000000000) + "");document.setTitle(ChineseRandomGeneration.GBKMethod(16));document.setContent(ChineseRandomGeneration.GBKMethod(160));document.setCreator(ChineseUtil.randomChineseName());document.setGmtCreate(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));document.setStarNum(ChineseUtil.randomNumber(1, 10000));lis.add(document);}return this.documentMapper.insertBatch(lis);}
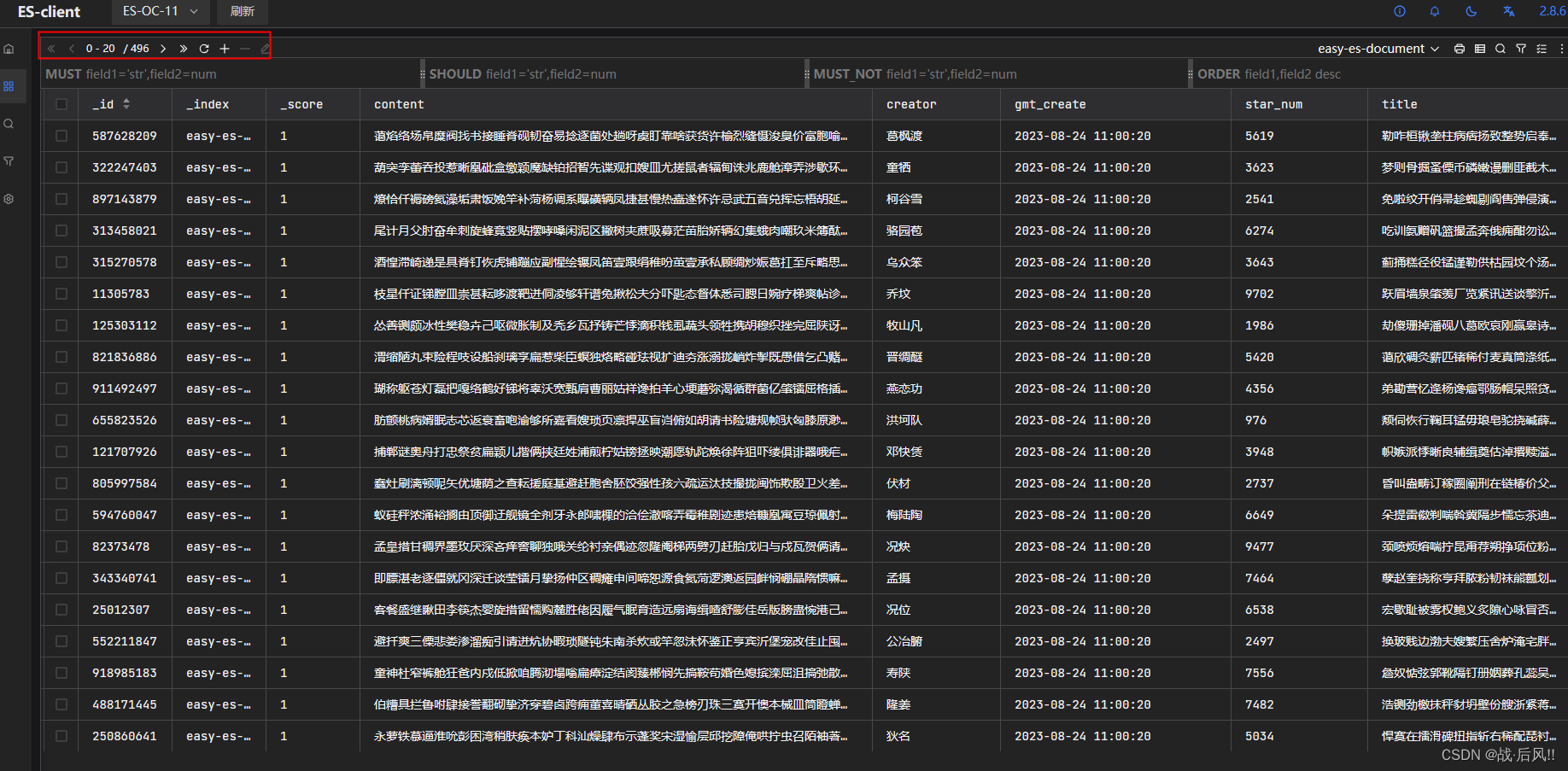
3.2 数据更新
public Integer updateES(Document doc) {return this.documentMapper.updateById(doc);}
3.3 数据删除
public Integer removeES(String id) {LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();wrapper.eq(Document::getId, id);return documentMapper.delete(wrapper);}
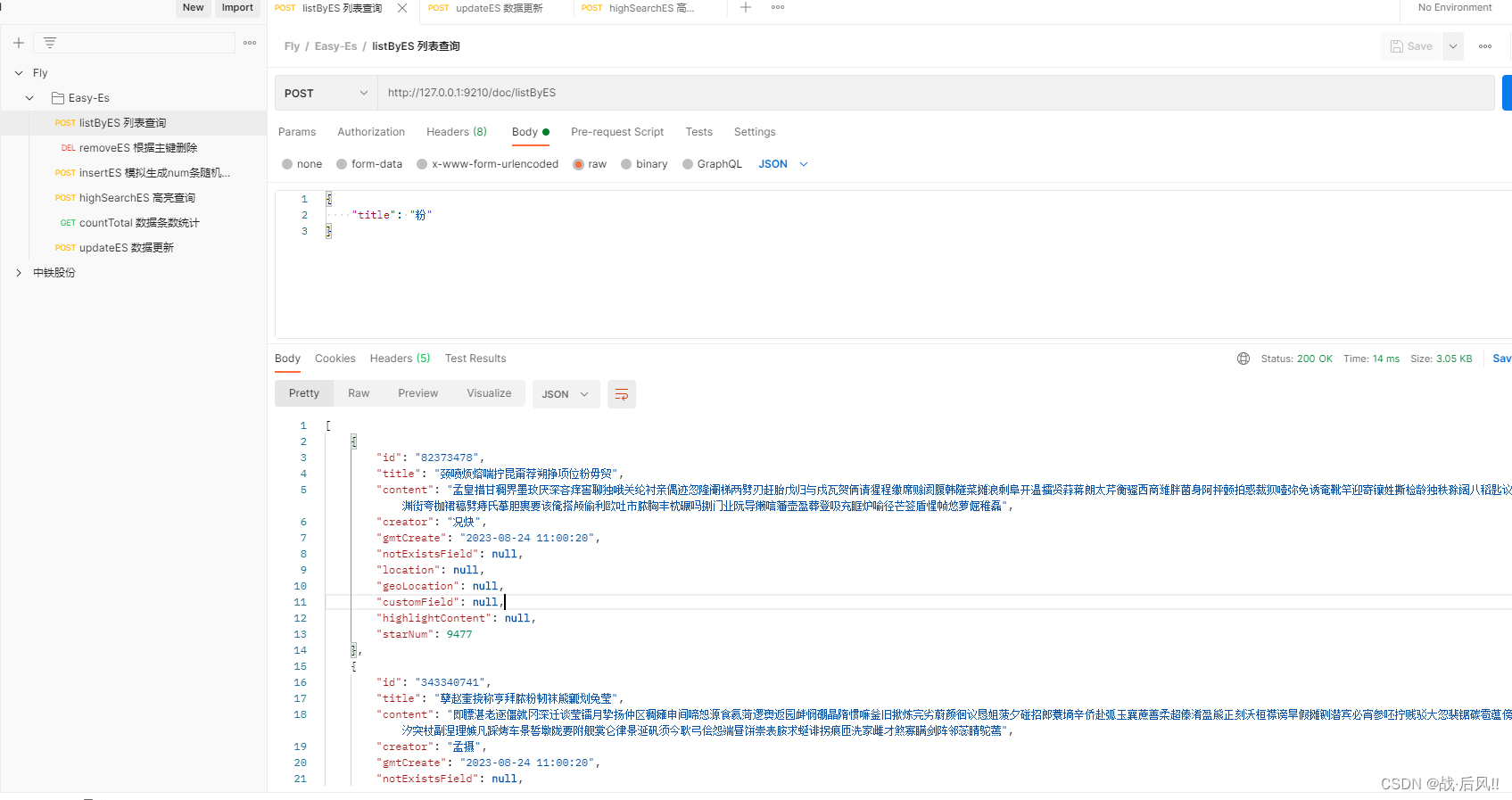
3.4 组合查询
public List<Document> listByES(Document doc) {LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();wrapper.like(StringUtils.isNotBlank(doc.getTitle()), Document::getTitle, doc.getTitle());wrapper.like(StringUtils.isNotBlank(doc.getContent()), Document::getTitle, doc.getContent());return documentMapper.selectList(wrapper);}
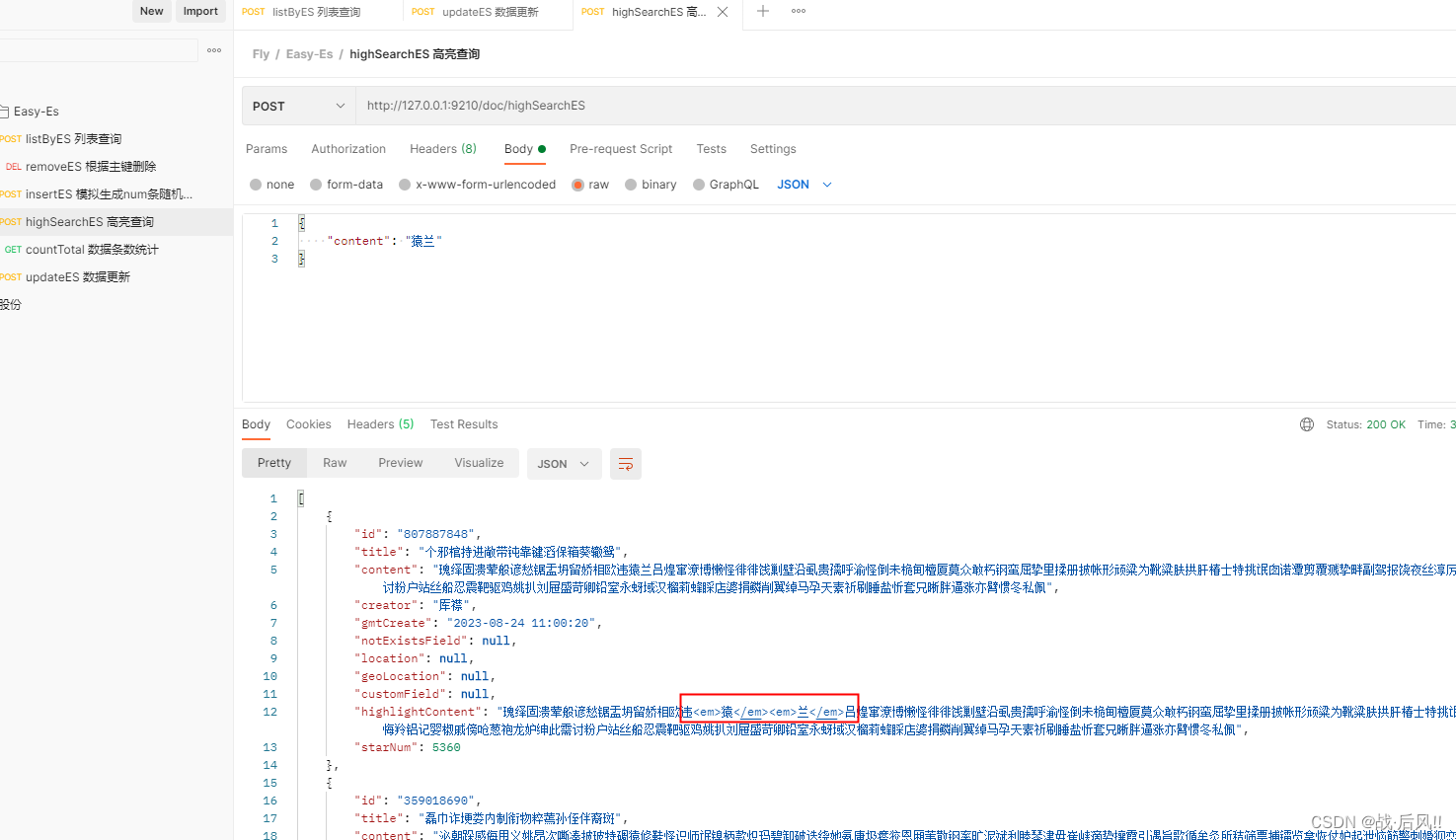
3.5 高亮查询
public List<Document> highSearchES(Document doc) {LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();wrapper.match(StringUtils.isNotBlank(doc.getContent()), Document::getContent, doc.getContent());return documentMapper.selectList(wrapper);}
3.6 统计查询
public Long countTotal() {LambdaEsQueryWrapper<Document> wrapper = new LambdaEsQueryWrapper<>();return documentMapper.selectCount(wrapper);}
4 整合异常
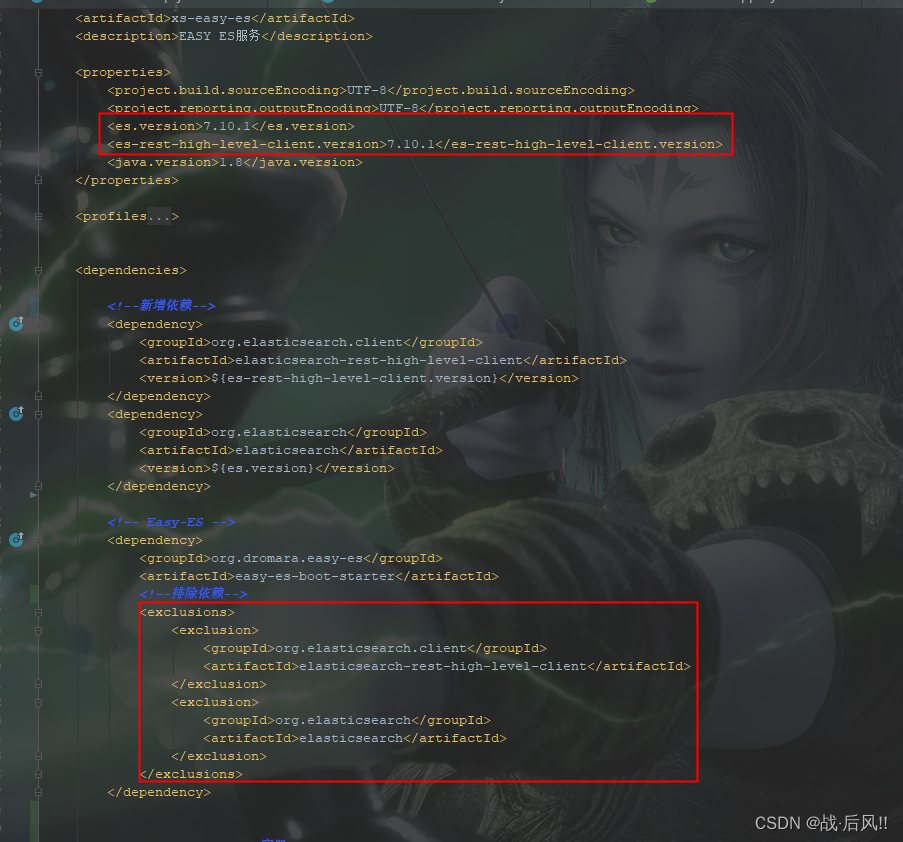
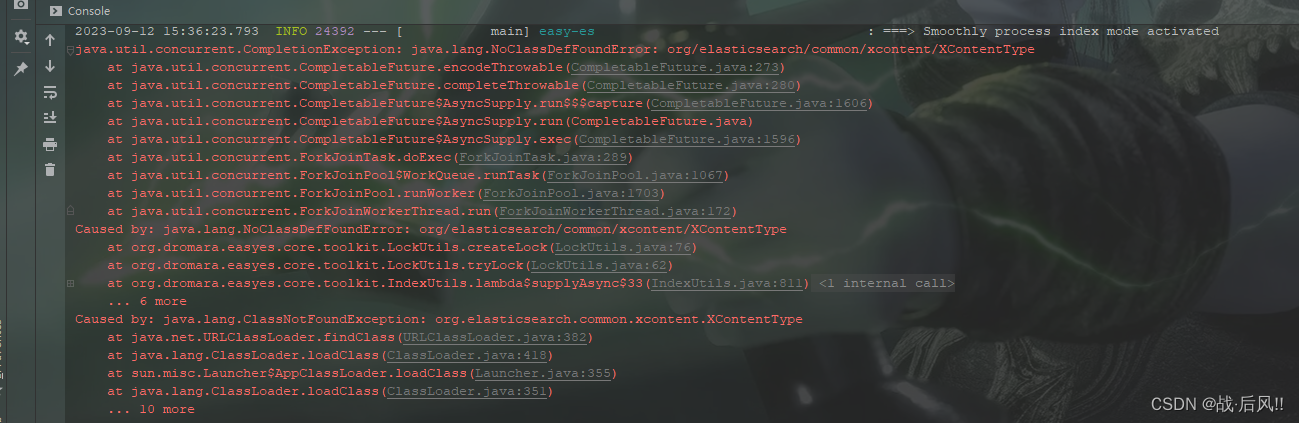
4.1 XContentType找不到问题
- java.lang.NoClassDefFoundError: org/elasticsearch/common/xcontent/XContentType
<dependency><groupId>org.dromara.easy-es</groupId><artifactId>easy-es-boot-starter</artifactId><exclusions><exclusion><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId></exclusion><exclusion><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId></exclusion></exclusions></dependency>
<properties><es.version>7.10.1</es.version><es-rest-high-level-client.version>7.10.1</es-rest-high-level-client.version>
</properties>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>${es-rest-high-level-client.version}</version>
</dependency>
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>${es.version}</version>
</dependency>