网站建设项目外包网站怎么编写一个网站
serkio应用实战
- 前言
- 实战开发
- 多次调用加密方法破解失败
- 如何刷新加密方法
- 同一个浏览器的加密代码如何给不同用户使用
- 注意事项
- 总结
前言
最近在工作中遇到了一个反爬虫产品,处于技术能力和新产品迭代更新快的考虑,最后选择使用RPC技术解决问题,因为serkio框架帮我们封装好了服务,且自身具备一定的负载均衡能力,所以选择它作为RPC实现方案。
新手入门请参考K哥的文章,我也是通过这篇继续学习的。
RPC 技术及其框架 Sekiro 在爬虫逆向中的应用,加密数据一把梭
实战开发
由于是工作业务相关的开发,设计隐私问题,这里就不一一展示开发过程了,我大概罗列出开发过程中遇到的问题
多次调用加密方法破解失败
在部署好Sekiro后,调用RPC服务已经能够拿到加密参数生成结果了,但是在多次调试后发现生成的结果用于请求时会失败,根据浏览器抓包请求流程确定请求接口定期会返回419,结果会携带一个data,当出现419必须将data进行处理,因为这个data会作用于下一次加密结果生成,流程图如下:
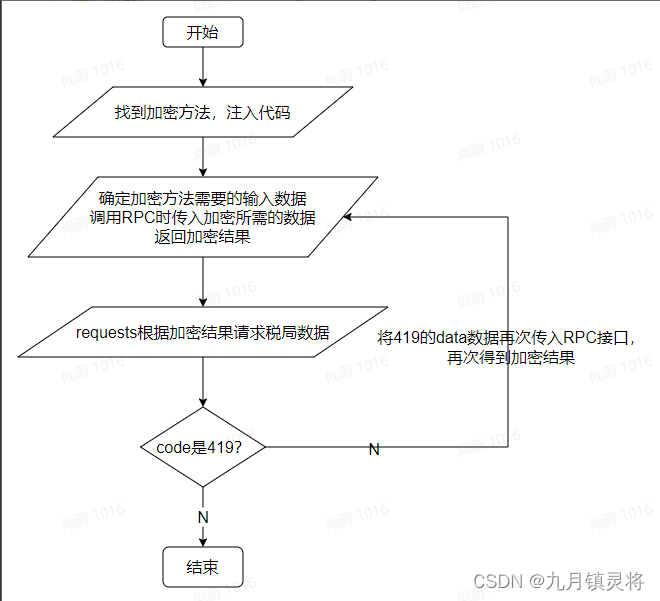
如何刷新加密方法
419的data怎么刷新到加密方法里呢?这个需要在js处理响应数据中找到相关的处理代码(onResponse),然后只要将这段代码在RPC服务中执行即可。
if (request.hasOwnProperty('dunm_data')) {let _0x37561b = _0x365f28(request['dunm_data'], window);_0x37561b["run"]();window.localStorage.dunm_data = request['dunm_data'];
}
同一个浏览器的加密代码如何给不同用户使用
使用同一份加密代码加密到的结果,然后用不同cookie发起请求,发现不是浏览器登录用户的请求结果是419,重试也无效,确定加密过程会引用用户的信息,删除浏览器的登录信息后,原浏览器登录用户用加密结果发起请求也无效,但是在重新设置cookie后有效,确定只要动态设置cookie即可实现同一个浏览器的加密代码给不同用户使用。
使用Object.defineProperty动态设置cookie和ua
var client = new SekiroClient("ws://127.0.0.1:5612/business-demo/register?group=shanghai&clientId=" + guid());
client.registerAction("getLosEncrypt", function (request, resolve, reject) {if (request.hasOwnProperty('dunm_data')) {let _0x37561b = _0x365f28(request['dunm_data'], window);_0x37561b["run"]();window.localStorage.dunm_data = request['dunm_data'];}if (request.hasOwnProperty('cookie')) {Object.defineProperty(document, 'cookie', {value: request['cookie'],writable: true});}if (request.hasOwnProperty('userAgent')) {Object.defineProperty(navigator, 'userAgent', {value: request['userAgent'],writable: true});}let result = window["ssx91m$212"](request['hurl'], request['post_data'], {});resolve(result)
})
注意事项
- 浏览器弹窗会将浏览器瞄点定位到弹框,导致RPC服务连接不上,所以我们需要处理弹窗,让其无法弹出,只需要重写方法即可
window.alert = function(str){return true;
}
window.compile = function(str){return true;
}
- RPC其实不会产生太大的浏览器内存,我在三台服务器中部署了sekiro,通过监控资源情况确定不会产生过大的内存占用
- sekiro如何实现负载均衡呢?其实sekiro可以创建很多哥group,每个group有16个client可以动态使用,也就是对于一个group来说其实是有一定的负载均衡能力,但是如果对多个group进行负载均衡,非商用版的话需要自己实现
- 调用rpc服务时由于传参太大导致调用失败,这个时候可以使用post,能实现一样的效果

总结
当我们不考虑去逆向js来实现加密参数的话,可以考虑使用RPC 技术,它不需要加载多余的资源,稳定性和效率明显都更高,也不需要考虑浏览器指纹、各种环境。但是,由于服务时注入到浏览器js文件中的,所以需要维护浏览器窗口的稳定性,且如果网站对ua等浏览器信息进行强校验的话,其实RPC也很难使用。